
Войти
Обнаружение плагиата или Определение сходства контента - это процесс выявления случаев плагиата и / или нарушения авторских прав в произведении или документе. Широкое использование компьютеров и появление Интернета упростили плагиат работы других.
Выявление плагиата может осуществляться разными способами. Обнаружение людей - это наиболее традиционная форма выявления плагиата в письменной работе. Это может быть длительной и трудоемкой задачей для читателя, а также может привести к несогласованности в способах выявления плагиата в организации. Программное обеспечение сопоставления текста (TMS), которое также называют «программным обеспечением для обнаружения плагиата» или «антиплагиатом», стало широко доступным в виде как коммерчески доступных продуктов, так и программного обеспечения с открытым исходным кодом. TMS фактически не обнаруживает плагиат как таковой, а вместо этого находит определенные отрывки текста в одном документе, которые соответствуют тексту в другом документе.
Компьютерное Обнаружение плагиата (CaPD) - это задача поиска информации (IR), поддерживаемая специализированными системами IR, которая называется системой обнаружения плагиата (PDS) или системой обнаружения сходства документов. В систематическом обзоре литературы 2019 года представлен обзор современных методов обнаружения плагиата.
Системы обнаружения текстового сходства реализуют один из двух общих подходов к обнаружению, один из которых является внешним, а другой - внутренним. Внешние системы обнаружения сравнивают подозрительный документ со справочной коллекцией, которая представляет собой набор документов, которые считаются подлинными. На основе выбранной модели документа и предопределенных критериев подобия задача обнаружения состоит в том, чтобы извлечь все документы, содержащие текст, который в некоторой степени подобен выбранному пороговому значению для текста в подозрительном документе. Внутренние PDS анализируют только текст, подлежащий оценке, без сравнения с внешними документами. Этот подход направлен на распознавание изменений в уникальном стиле письма автора как индикатора потенциального плагиата. PDS не способны надежно идентифицировать плагиат без человеческого суждения. Сходства и особенности стиля письма вычисляются с помощью предопределенных моделей документов и могут представлять ложные срабатывания.
Было проведено исследование для проверки эффективности подобия программное обеспечение для обнаружения в условиях высшего образования. В одной части исследования одной группе студентов было поручено написать работу. Эти студенты сначала узнали о плагиате и проинформировали, что их работа должна проходить через систему обнаружения сходства контента. Второй группе студентов было поручено написать работу без какой-либо информации о плагиате. Исследователи ожидали найти более низкие показатели в первой группе, но обнаружили примерно одинаковые показатели плагиата в обеих группах.
На рисунке ниже представлена классификация всех подходов к обнаружению, используемых в настоящее время для компьютеров. -с помощью обнаружения сходства контента. Подходы характеризуются типом выполняемой ими оценки сходства: глобальным или локальным. Подходы к оценке глобального сходства используют характеристики, взятые из более крупных частей текста или документа в целом, для вычисления сходства, в то время как локальные методы проверяют только предварительно выбранные сегменты текста в качестве входных.
 Классификация компьютерных методов обнаружения плагиата
Классификация компьютерных методов обнаружения плагиата Снятие отпечатков пальцев в настоящее время является наиболее широко применяемым подходом к обнаружению сходства контента. Этот метод формирует репрезентативные дайджесты документов, выбирая из них набор нескольких подстрок (n-граммов ). Наборы представляют собой отпечатки пальцев, а их элементы называются мелкими деталями. Подозрительный документ проверяется на плагиат, вычисляя его отпечаток пальца и запрашивая детали с предварительно вычисленным указателем отпечатков пальцев для всех документов справочной коллекции. Совпадение мелких деталей с другими документами указывает на общие текстовые сегменты и предполагает потенциальный плагиат, если они превышают выбранный порог схожести. Вычислительные ресурсы и время являются ограничивающими факторами для снятия отпечатков пальцев, поэтому этот метод обычно сравнивает только подмножество мелочей, чтобы ускорить вычисления и позволить проверки в очень большой коллекции, такой как Интернет.
Сопоставление строк - распространенный подход, используемый в информатике. Применительно к проблеме обнаружения плагиата документы сравниваются на предмет дословного наложения текста. Для решения этой задачи было предложено множество методов, некоторые из которых были адаптированы для обнаружения внешнего плагиата. Проверка подозрительного документа в этом параметре требует вычисления и хранения эффективно сопоставимых представлений для всех документов в эталонной коллекции, чтобы сравнить их попарно. Обычно для этой задачи использовались модели суффиксных документов, такие как суффиксные деревья или суффиксные векторы. Тем не менее сопоставление подстрок остается дорогостоящим с точки зрения вычислений, что делает его нежизнеспособным решением для проверки больших коллекций документов.
Анализ пакета слов представляет собой внедрение вектора поиск пространства, традиционная концепция IR, в область обнаружения сходства контента. Документы представлены в виде одного или нескольких векторов, например для разных частей документа, которые используются для вычисления попарного сходства. Вычисление подобия затем может основываться на традиционной косинусной мере сходства или на более сложных показателях подобия.
Обнаружение плагиата на основе цитирования (CbPD) основывается на анализ цитирования, и это единственный подход к обнаружению плагиата, который не полагается на текстовое сходство. CbPD изучает цитирование и справочную информацию в текстах, чтобы идентифицировать аналогичные шаблоны в последовательностях цитирования. Таким образом, этот подход подходит для научных текстов или других академических документов, содержащих цитаты. Анализ цитирования для выявления плагиата - относительно молодая концепция. Он не был принят коммерческим программным обеспечением, но существует первый прототип системы обнаружения плагиата на основе цитирования. Сходный порядок и близость цитирований в изученных документах являются основными критериями, используемыми для вычисления сходства шаблонов цитирования. Шаблоны цитирования представляют собой подпоследовательности, не только содержащие ссылки, общие для сравниваемых документов. Факторы, в том числе абсолютное количество или относительная доля общих цитирований в шаблоне, а также вероятность того, что ссылки одновременно встречаются в документе, также учитываются для количественной оценки степени сходства шаблонов.
Стилометрия включает статистические методы для количественной оценки уникального стиля письма автора и в основном используется для установления авторства или обнаружения внутреннего плагиата. Выявление плагиата с помощью атрибуции авторства требует проверки, совпадает ли стиль написания подозрительного документа, который предположительно написан определенным автором, со стилем письма, написанного тем же автором. С другой стороны, обнаружение внутреннего плагиата позволяет выявить плагиат на основе внутренних доказательств в подозрительном документе, не сравнивая его с другими документами. Это выполняется путем построения и сравнения стилометрических моделей для различных текстовых сегментов подозрительного документа, а отрывки, стилистически отличающиеся от других, помечаются как потенциально плагиат / нарушенные. Несмотря на то, что их легко извлечь, символы n-граммы оказались одними из лучших стилометрических характеристик для обнаружения внутреннего плагиата.
Сравнительные оценки систем обнаружения сходства контента показывают, что их производительность зависит от типа имеющегося плагиата (см. Рисунок). За исключением анализа шаблонов цитирования, все подходы к обнаружению полагаются на текстовое сходство. Поэтому симптоматично, что точность обнаружения уменьшается по мере того, как скрывается больше случаев плагиата.
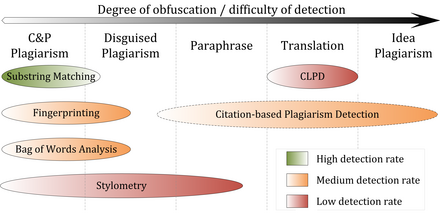 Эффективность обнаружения CaPD зависит от типа имеющегося плагиата
Эффективность обнаружения CaPD зависит от типа имеющегося плагиата Дословные копии, также известные как плагиат «копирование и вставка» (c p), или явное нарушение авторских прав, или скромно замаскированные случаи плагиата могут быть обнаружены с высокой точностью текущим внешним PDS если источник доступен для программы. В частности, процедуры сопоставления подстроки обеспечивают хорошую производительность для плагиата c p, поскольку они обычно используют модели документов без потерь, такие как суффиксные деревья. Производительность систем, использующих дактилоскопию или анализ пакетов слов при обнаружении копий, зависит от потери информации, вызванной используемой моделью документа. Применяя гибкие стратегии фрагментирования и выбора, они лучше способны обнаруживать умеренные формы замаскированного плагиата по сравнению с процедурами сопоставления подстрок.
Обнаружение внутреннего плагиата с использованием стилометрии может в некоторой степени преодолеть границы текстового сходства путем сравнения языкового сходства. Учитывая, что стилистические различия между плагиатом и исходными сегментами значительны и могут быть надежно идентифицированы, стилометрия может помочь в выявлении замаскированного и перефразированного плагиата. Стилометрические сравнения, вероятно, потерпят неудачу в тех случаях, когда сегменты сильно перефразированы до такой степени, что они больше напоминают личный стиль письма плагиатора, или если текст был составлен несколькими авторами. Результаты Международных конкурсов по обнаружению плагиата, проведенных в 2009, 2010 и 2011 годах, а также эксперименты, проведенные Штейном, показывают, что стилометрический анализ работает надежно только для документов длиной в несколько тысяч или десятков тысяч слов, что ограничивает применимость метода к настройкам CaPD.
Все большее количество исследований проводится по методам и системам, способным обнаруживать транслированный плагиат. В настоящее время обнаружение межъязыкового плагиата (CLPD) не рассматривается как зрелая технология, и соответствующие системы не смогли достичь удовлетворительных результатов обнаружения на практике.
Обнаружение плагиата на основе цитирования с использованием анализа шаблонов цитирования позволяет определение более сильных перефразировок и переводов с более высокими показателями успеха по сравнению с другими подходами к обнаружению, поскольку это не зависит от текстовых характеристик. Однако, поскольку анализ схемы цитирования зависит от наличия достаточной информации о цитировании, он ограничивается академическими текстами. Он по-прежнему уступает подходам на основе текста в обнаружении более коротких отрывков с плагиатом, которые типичны для случаев плагиата с копированием и вставкой или встряхиванием и вставкой; последнее относится к смешиванию слегка измененных фрагментов из разных источников.
Дизайн программного обеспечения для определения сходства контента для использования с текстовыми документами характеризуется рядом факторов:
| Фактор | Описание и альтернативы |
|---|---|
| Объем поиска | В общедоступном Интернете с использованием поисковых систем / институциональных баз данных / локальных системно-зависимых баз данных. |
| Время анализа | Задержка между отображением документа отправлено и время, когда результаты станут доступны. |
| Объем документов / Пакетная обработка | Количество документов, которые система может обработать за единицу времени. |
| Проверять интенсивность | Как часто и для каких типов документов фрагменты (абзацы, предложения, последовательности слов фиксированной длины) запрашивают системой внешние ресурсы, такие как поисковые системы. |
| Тип алгоритма сравнения | Алгоритмы, которые определяют способ, которым система использует для сравнения документов друг с другом. |
| Точность и отзыв | Количество документов, правильно отмеченных как плагиат, по сравнению с общим количеством помеченных документов, и к общему количеству документов, которые были фактически плагиатом. Высокая точность означает, что было обнаружено несколько ложных срабатываний, а высокий уровень отзыва означает, что несколько ложных отрицательных результатов остались необнаруженными. |
Большинство крупномасштабных систем обнаружения плагиата используют большие внутренние базы данных ( в дополнение к другим ресурсам), которые растут с каждым дополнительным документом, представленным на анализ. Однако некоторые считают эту функцию нарушением авторских прав учащихся.
Плагиат в исходном коде компьютера также встречается часто и требует других инструментов, чем те, которые используются для сравнения текста в документе.. Значительные исследования были посвящены академическому плагиату исходного кода.
Отличительным аспектом плагиата исходного кода является отсутствие фабрик для сочинений, которые можно найти в традиционном плагиате. Поскольку большинство заданий по программированию предполагают, что студенты будут писать программы с очень конкретными требованиями, очень сложно найти существующие программы, которые им уже соответствуют. Поскольку интегрировать внешний код зачастую сложнее, чем писать его с нуля, большинство студентов, занимающихся плагиатом, предпочитают делать это у своих сверстников.
Согласно Рою и Корди, алгоритмы обнаружения сходства исходного кода могут быть классифицированы как основанные на
Предыдущая классификация была разработана для рефакторинга кода, а не для обнаружения академического плагиата (важная цель рефакторинга - избежать дублирования кода, называемого в литературе клонами кода ). Вышеупомянутые подходы эффективны против разных уровней сходства; Сходство низкого уровня относится к идентичному тексту, в то время как сходство высокого уровня может быть связано с аналогичными спецификациями. В академической среде, когда ожидается, что все студенты будут кодировать в соответствии с одними и теми же спецификациями, ожидается полностью функционально эквивалентный код (с высокоуровневым сходством), и только низкоуровневое сходство рассматривается как доказательство обмана.
Были задокументированы различные сложности при использовании программного обеспечения сопоставления текста при использовании для обнаружения плагиата. Одна из наиболее распространенных проблем, задокументированных центрами, посвящена вопросу прав интеллектуальной собственности. Основной аргумент заключается в том, что материалы должны быть добавлены в базу данных, чтобы TMS могла эффективно определить соответствие, но добавление материалов пользователей в такую базу данных может нарушить их права интеллектуальной собственности. Этот вопрос поднимался в ряде судебных дел.
Дополнительная сложность при использовании TMS заключается в том, что программа находит только точные совпадения с другим текстом. Он не учитывает плохо перефразированные работы, например, или практику плагиата с использованием достаточного количества замен слов, чтобы ускользнуть от программного обеспечения для обнаружения, что известно как rogeting.