Экономическая модель
Модель лидерства Штакельберга - это стратегическая игра в экономике, в котором сначала движется фирма-лидер, а затем последовательно движутся фирмы-последователи. Он назван в честь немецкого экономиста Генриха Фрайхера фон Штакельберга, который опубликовал (Marktform und Gleichgewicht) в 1934 году, в котором описал эту модель.
В терминах теории игр игроки в этой игре - лидер и последователь, и они соревнуются в количестве. Лидера Штакельберга иногда называют лидером рынка.
Есть еще некоторые ограничения на поддержание равновесия по Штакельбергу. Лидер должен знать ex ante, что ведомый наблюдает за его действием. Последователь не должен иметь никаких средств для совершения действий будущего лидера, не принадлежащего Штакельбергу, и лидер должен это знать. В самом деле, если бы «последователь» мог совершить действие лидера по Штакельбергу и «лидер» знал бы об этом, лучшим ответом лидера было бы разыграть действие последователя по Штакельбергу.
Фирмы могут участвовать в соревновании по Штакельбергу, если у них есть какое-то преимущество, позволяющее им двигаться вперед. В более общем смысле лидер должен обладать приверженностью властью. Наблюдаемое движение вперед - наиболее очевидное средство приверженности: как только лидер сделал свой ход, он не может его отменить - он привержен этому действию. Движение первым может быть возможным, если лидер был существующей монополией отрасли, а последователь - новым участником. Сохранение избыточных мощностей - еще одно средство принятия обязательств.
Содержание
- 1 Подигра: идеальное равновесие по Нэшу
- 2 Экономический анализ
- 3 Достоверные и неправдоподобные угрозы со стороны последователя
- 4 Штакельберг по сравнению с Курно
- 4.1 Теоретическая часть игры соображения
- 5 Сравнение с другими моделями олигополии
- 6 Приложения
- 7 См. также
- 8 Ссылки
Идеальное равновесие по Нэшу в подиграх
Модель Штакельберга может быть решена, чтобы найти подигра идеальное равновесие по Нэшу или равновесие (SPNE), то есть профиль стратегии, который лучше всего подходит каждому игроку, учитывая стратегии другого игрока и который предполагает, что каждый игрок играет в равновесии по Нэшу в каждом подигра.
В самых общих чертах, пусть функция цены для (дуополии) отрасли будет  ; цена - это просто функция общего (отраслевого) выпуска, поэтому
; цена - это просто функция общего (отраслевого) выпуска, поэтому  где нижний индекс 1 представляет лидера, а 2 - ведомого. Предположим, фирма
где нижний индекс 1 представляет лидера, а 2 - ведомого. Предположим, фирма  имеет структуру затрат
имеет структуру затрат  . Модель решается методом обратной индукции. Лидер считает, какой лучший ответ ведомого, то есть как он будет реагировать после того, как увидит количество лидера. Затем лидер выбирает количество, которое максимизирует его выигрыш, ожидая предсказанной реакции ведомого. Последователь действительно наблюдает за этим и в состоянии равновесия выбирает ожидаемое количество в качестве ответа.
. Модель решается методом обратной индукции. Лидер считает, какой лучший ответ ведомого, то есть как он будет реагировать после того, как увидит количество лидера. Затем лидер выбирает количество, которое максимизирует его выигрыш, ожидая предсказанной реакции ведомого. Последователь действительно наблюдает за этим и в состоянии равновесия выбирает ожидаемое количество в качестве ответа.
Чтобы вычислить SPNE, сначала должны быть вычислены функции наилучшего отклика ведомого (вычисление смещается "назад" из-за обратной индукции).
Прибыль фирмы 2 (последователя) - это выручка за вычетом затрат. Выручка - это произведение цены и количества, а стоимость определяется структурой затрат фирмы, поэтому прибыль составляет:  . Лучший ответ - найти значение
. Лучший ответ - найти значение  , которое максимизирует
, которое максимизирует  при заданном
при заданном  , т. е. при заданном выпуске лидера (фирмы 1) найден выпуск, который максимизирует прибыль ведомого. Следовательно, максимум относительно равен быть найденным. Сначала дифференцируйте относительно :
, т. е. при заданном выпуске лидера (фирмы 1) найден выпуск, который максимизирует прибыль ведомого. Следовательно, максимум относительно равен быть найденным. Сначала дифференцируйте относительно :

Установка на ноль для максимизации:

Значения , которые удовлетворяют этому уравнению, являются наилучшими ответами. Рассмотрена функция наилучшего отклика лидера. Эта функция рассчитывается путем рассмотрения выхода ведомого как функции выхода лидера, как только что вычисленного.
Прибыль фирмы 1 (лидера) составляет  , где
, где  - количество ведомого как функция количество лидера, а именно вычисленная выше функция. Лучший ответ - найти значение , которое максимизирует
- количество ведомого как функция количество лидера, а именно вычисленная выше функция. Лучший ответ - найти значение , которое максимизирует  с учетом , т. е. с учетом наилучшей функции отклика последователя (фирмы 2), результат, который максимизирует найдена прибыль лидера. Следовательно, максимум по отношению к равен быть найденным. Сначала дифференцируем относительно :
с учетом , т. е. с учетом наилучшей функции отклика последователя (фирмы 2), результат, который максимизирует найдена прибыль лидера. Следовательно, максимум по отношению к равен быть найденным. Сначала дифференцируем относительно :

Обнуление для максимизации:

Примеры
Следующий пример является очень общим. Он предполагает обобщенную линейную структуру спроса

и налагает некоторые ограничения на структуру затрат для простоты, так что проблема может быть решена.
 и
и 
для простоты вычислений.
Прибыль последователя:

Задача максимизации разрешается к (из общего случая):



Рассмотрим задачу лидера:

Замена на из задачи последователя:


Проблема максимизации разрешается к (из общего случая):

Теперь решение для дает  , оптимальное действие лидера:
, оптимальное действие лидера:

Это лучший ответ лидера на реакцию подчиненного в равновесии. Фактическое значение ведомого теперь можно найти, введя его в вычисленную ранее функцию реакции:


Все равновесия Нэша равны  . Ясно (если принять предельные издержки равными нулю, т. Е. Затраты по существу игнорируются), что лидер имеет значительное преимущество. Интуитивно понятно, что если бы лидер был не лучше, чем последователь, он бы просто принял стратегию конкуренции Курно.
. Ясно (если принять предельные издержки равными нулю, т. Е. Затраты по существу игнорируются), что лидер имеет значительное преимущество. Интуитивно понятно, что если бы лидер был не лучше, чем последователь, он бы просто принял стратегию конкуренции Курно.
Вставка количества последователя  обратно в функцию наилучшего ответа лидера не даст
обратно в функцию наилучшего ответа лидера не даст  . Это потому, что, как только лидер взял на себя обязательство по выпуску и наблюдал за последователями, он всегда хочет уменьшить свой результат постфактум. Однако его неспособность сделать это позволяет ему получать более высокую прибыль, чем при использовании курса.
. Это потому, что, как только лидер взял на себя обязательство по выпуску и наблюдал за последователями, он всегда хочет уменьшить свой результат постфактум. Однако его неспособность сделать это позволяет ему получать более высокую прибыль, чем при использовании курса.
Экономический анализ
Представление в развернутой форме часто используется для анализа модели Штакельберга лидер-последователь. Модель, также называемая «деревом решений », показывает комбинацию результатов и выплат, которые имеют обе фирмы в игре Штакельберга.
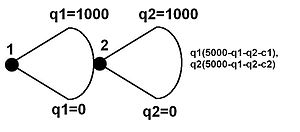
Игра Штакельберга, представленная в
расширенной форме Изображение слева изображена в развернутой форме игра Штакельберга. Выплаты показаны справа. Этот пример довольно простой. Существует базовая структура затрат, включающая только предельные затраты (не существует фиксированных затрат ). Функция спроса линейна, а эластичность спроса по цене равна 1. Однако это демонстрирует преимущество лидера.
Последователь хочет выбрать , чтобы максимизировать свой выигрыш  . Если взять производную первого порядка и приравнять ее к нулю (для максимизации), получим
. Если взять производную первого порядка и приравнять ее к нулю (для максимизации), получим  как максимальное значение .
как максимальное значение .
Лидер хочет выбрать , чтобы максимизировать выигрыш  . Однако в равновесии он знает, что ведомый выберет , как указано выше. Фактически лидер хочет максимизировать свой выигрыш
. Однако в равновесии он знает, что ведомый выберет , как указано выше. Фактически лидер хочет максимизировать свой выигрыш  (заменяя для функции наилучшего отклика ведомого). Путем дифференциации максимальный выигрыш определяется как
(заменяя для функции наилучшего отклика ведомого). Путем дифференциации максимальный выигрыш определяется как  . Подавая это в функцию наилучшего отклика ведомого, получаем
. Подавая это в функцию наилучшего отклика ведомого, получаем  . Предположим, что предельные издержки были равны для фирм (так что лидер не имеет никакого рыночного преимущества, кроме первого шага) и, в частности,
. Предположим, что предельные издержки были равны для фирм (так что лидер не имеет никакого рыночного преимущества, кроме первого шага) и, в частности,  . Лидер произведет 2000, а ведомый произведет 1000. Это даст лидеру прибыль (выплату) в размере двух миллионов, а ведомому - прибыль в один миллион. Просто двигаясь первым, лидер получает в два раза больше прибыли, чем последователь. Однако прибыль Курно здесь составляет 1,78 миллиона долларов за штуку (строго:
. Лидер произведет 2000, а ведомый произведет 1000. Это даст лидеру прибыль (выплату) в размере двух миллионов, а ведомому - прибыль в один миллион. Просто двигаясь первым, лидер получает в два раза больше прибыли, чем последователь. Однако прибыль Курно здесь составляет 1,78 миллиона долларов за штуку (строго:  за штуку), поэтому лидер не многого добился, а ведомый проиграл. Однако это зависит от конкретного примера. Могут быть случаи, когда руководитель Штакельберга имеет огромные выгоды помимо прибыли Курно, приближающейся к монопольной прибыли (например, если у лидера также было большое преимущество в структуре затрат, возможно, из-за лучшей производственной функции ). Также могут быть случаи, когда последователь действительно получает более высокую прибыль, чем лидер, но только потому, что, скажем, он имеет гораздо более низкие затраты. Такое поведение постоянно работает на дуополистических рынках, даже если фирмы асимметричны.
за штуку), поэтому лидер не многого добился, а ведомый проиграл. Однако это зависит от конкретного примера. Могут быть случаи, когда руководитель Штакельберга имеет огромные выгоды помимо прибыли Курно, приближающейся к монопольной прибыли (например, если у лидера также было большое преимущество в структуре затрат, возможно, из-за лучшей производственной функции ). Также могут быть случаи, когда последователь действительно получает более высокую прибыль, чем лидер, но только потому, что, скажем, он имеет гораздо более низкие затраты. Такое поведение постоянно работает на дуополистических рынках, даже если фирмы асимметричны.
Достоверные и ненадежные угрозы со стороны ведомого
Если после того, как лидер выбрал свое равновесное количество, ведомый отклонился от равновесия и выбрал какое-то неоптимальное количество, это не только повредило бы сам, но это также могло повредить лидеру. Если последователь выберет гораздо большее количество, чем его лучший ответ, рыночная цена упадет, а прибыль лидера пострадает, возможно, ниже прибыли уровня Курно. В этом случае ведомый может объявить лидеру до начала игры, что, если лидер не выберет равновесное количество Курно, ведомый выберет отклоняющееся количество, которое повлияет на прибыль лидера. В конце концов, количество, выбранное лидером в равновесии, является оптимальным только в том случае, если ведомый также играет в равновесии. Однако лидеру ничего не угрожает. После того, как лидер выбрал свое равновесное количество, для ведомого было бы иррационально отклоняться, потому что это тоже могло бы пострадать. После того, как лидер сделал выбор, последователь будет лучше играть по пути равновесия. Следовательно, такая угроза со стороны последователя не вызывает доверия.
Однако в (бесконечно) повторяющейся игре Штакельберга ведомый может принять стратегию наказания, при которой он угрожает наказать лидера в следующем периоде, если он не выберет неоптимальную стратегию в текущем периоде. Эта угроза может быть правдоподобной, потому что для ведомого может быть рациональным наказать в следующем периоде, чтобы после этого лидер выбирал количества Курно.
Сравнение Штакельберга с Курно
Модели Штакельберга и Курно похожи, потому что в обоих случаях конкуренция заключается в количестве. Однако, как видно, первый ход дает лидеру Штакельберга решающее преимущество. Также существует важное предположение о совершенной информации в игре Штакельберга: ведомый должен соблюдать количество, выбранное лидером, в противном случае игра сводится к Курно. При неполной информации описанные выше угрозы могут быть достоверными. Если ведомый не может наблюдать за движением лидера, то для него уже не является иррациональным выбирать, скажем, количественный уровень Курно (по сути, это равновесное действие). Однако может оказаться, что имеется неполная информация, и ведомый не может наблюдать за движением лидера, потому что для ведомого нерационально не наблюдать, если он может, после того, как лидер переместился. Если он может наблюдать, он будет так делать, чтобы принять оптимальное решение. Любая угроза со стороны последователя, утверждающего, что он не будет наблюдать, даже если это будет возможно, столь же недостоверна, как и указанные выше. Это пример того, как слишком много информации причиняет вред игроку. В соревновании Курно именно одновременность игры (несовершенство знаний) приводит к тому, что ни один из игроков (при прочих равных условиях ) не оказывается в невыгодном положении.
Теоретические соображения по игре
Как уже упоминалось, несовершенная информация в лидерской игре сводится к соревнованию Курно. Однако некоторые профили стратегии Курно поддерживаются как равновесие по Нэшу, но могут быть устранены как невероятные угрозы (как описано выше) путем применения концепции решения из совершенства подыгры. В самом деле, именно это делает профиль стратегии Курно равновесием по Нэшу в игре Штакельберга, что не позволяет ему быть совершенной подигрой.
Рассмотрим игру Штакельберга (то есть игру, которая удовлетворяет описанным выше требованиям для поддержания равновесия по Штакельбергу), в которой по какой-то причине лидер считает, что какое бы действие он ни предпринял, ведомый выберет количество Курно (возможно, лидер считает, что последователь иррационален). Если лидер сыграл действие Штакельберга, (он считает), что ведомый сыграет Курно. Следовательно, для лидера играть Штакельберга неоптимально. Фактически, его лучший ответ (по определению равновесия Курно) - это играть количеством Курно. Как только он это сделает, лучший ответ соратника - сыграть Курно.
Рассмотрим следующие профили стратегии: лидер играет Курно; ведомый играет Курно, если лидер играет Курно, а ведомый играет Штакельберга, если лидер играет Штакельберга, и если лидер играет что-то еще, ведомый играет произвольную стратегию (следовательно, это фактически описывает несколько профилей). Этот профиль представляет собой равновесие по Нэшу. Как указывалось выше, игра по пути равновесия - лучший ответ на лучший ответ. Однако игра Курно была бы не лучшим ответом лидера, если бы его последователь играл Штакельберга, если бы он (лидер) играл Штакельберга. В этом случае лучшим ответом лидера будет игра Штакельберга. Следовательно, что делает этот профиль (или, скорее, эти профили) равновесием по Нэшу (или, скорее, равновесием по Нэшу), так это тот факт, что ведомый будет играть не-Штакельберга, если бы лидер играл Штакельберга.
Однако сам этот факт (что последователь играл бы не по Штакельбергу, если бы лидер играл Штакельберга) означает, что этот профиль не является равновесием по Нэшу для вспомогательной игры, начинающейся, когда лидер уже играл по Штакельбергу ( подигра вне равновесного пути). Если лидер уже сыграл Штакельберга, лучший ответ ведомого - это сыграть Штакельберга (и, следовательно, это единственное действие, которое приводит к равновесию по Нэшу в этой подигре). Следовательно, профиль стратегии, которым является Курно, не идеален для подигр.
Сравнение с другими моделями олигополии
По сравнению с другими моделями олигополии,
- Совокупный результат Штакельберга больше, чем совокупный результат Курно, но меньше совокупного Бертрана выход.
- Цена Штакельберга ниже, чем цена Курно, но больше, чем цена Бертрана.
- Потребительский излишек Штакельберга больше, чем потребительский излишек Курно, но ниже, чем потребительский излишек Бертрана.
- Совокупный объем производства по Штакельбергу больше, чем чистая монополия или картель, но меньше, чем идеально конкурентоспособный объем производства.
- Цена Штакельберга равна ниже, чем цена чистой монополии или картеля, но выше, чем идеально конкурентоспособная цена.
Приложения
Концепция Штакельберга была распространена на динамические игры Штакельберга. См. Simaan и Cruz (1973a, 1973b). С добавлением времени в качестве измерения были обнаружены явления, которые не встречаются в статических играх, такие как нарушение принципа оптимальности лидером, Симаном и Крузом (1973b). Обзор приложений дифференциальных игр Штакельберга к цепочке поставок и каналам сбыта см. В He et al. (2007). В последние годы игры Stackelberg внесли большой вклад в область безопасности, где для сотрудников службы безопасности важно защищать какой-либо ценный ресурс и искать для него любые потенциальные угрозы. Именно здесь персонал службы безопасности (лидер) сначала должен разработать свою стратегию, чтобы независимо от стратегии, принятой вором (последователем), ресурс оставался в безопасности.
См. Также
Ссылки
- H. фон Штакельберг, Структура рынка и равновесие: 1-е издание, перевод на английский, Bazin, Urch Hill, Springer 2011, XIV, 134 стр., ISBN 978-3-642-12585- 0
- М. Симан, Дж. Б. Круз мл., О стратегии Штакельберга в играх с ненулевой суммой, Журнал теории оптимизации и приложений, т. 11, No. 5, May 1973, pp. 533–555.
- M. Симан, Дж. Б. Круз младший, Дополнительные аспекты стратегии Штакельберга в играх с ненулевой суммой, Журнал теории оптимизации и приложений, т. 11, No. 6, June 1973, pp. 613–626.
- He, X., Prasad, A., Sethi, SP, and Gutierrez, G. (2007) A Обзор дифференциальных игровых моделей Штакельберга в каналах поставок и маркетинга, Журнал системной науки и системной инженерии (JSSSE), 16 (4), декабрь 2007 г., стр. 385–413. Доступно на https://ssrn.com/abstract=1069162
- Fudenberg, D. and Tirole, J. (1993) Game Theory, MIT Press. (см. главу 3, раздел 1)
- Гиббонс, Р. (1992) Пособие по теории игр, Harvester-Wheatsheaf. (см. главу 2, раздел 1B)
- Осборн, MJ и Рубинштейн, A. (1994) Курс теории игр, MIT Press (см. стр. 97-98)
- Oligoply Theory made Simple, глава 6 книги Surfing Economics, автор Хью Диксон.

 Игра Штакельберга, представленная в расширенной форме
Игра Штакельберга, представленная в расширенной форме