В обработке естественного языка скрытое распределение Дирихле (LDA ) - это генеративная статистическая модель, которая позволяет объяснять наборы наблюдений ненаблюдаемыми группами, которые объясняют, почему некоторые части данных похожи. Например, если наблюдения представляют собой слова, собранные в документы, он предполагает, что каждый документ представляет собой смесь небольшого количества тем и что присутствие каждого слова связано с одной из тем документа. LDA является примером тематической модели и относится к набору инструментов машинного обучения и, в более широком смысле, к набору инструментов искусственного интеллекта.
Содержание
- 1 История
- 2 Обзор
- 2.1 Эволюционная биология и биомедицина
- 2.2 Инженерия
- 3 Модель
- 3.1 Генеративный процесс
- 3.2 Определение
- 4 Заключение
- 4.1 Моделирование Монте-Карло
- 4.2 Вариационный Байес
- 4.3 Максимизация правдоподобия
- 4.4 Неизвестное количество популяций / тем
- 4.5 Альтернативные подходы
- 4.6 Аспекты вычислительных деталей
- 5 Связанные проблемы
- 5.1 Связанные модели
- 5.2 Пространственные модели
- 6 См. Также
- 7 Ссылки
- 8 Внешние ссылки
История
В контексте популяционной генетики, LDA был предложен Дж. К. Причард, М. Стивенс и П. Доннелли в 2000 году.
LDA применялось в машинном обучении Дэвидом Блей, Эндрю Нг и Майклом И. Джордан в 2003 году.
Обзор
Эволюционная биология и биомедицина
В эволюционной биологии и биомедицине модель используется для обнаружения присутствия структурированных генетическая изменчивость в группе лиц. Модель предполагает, что аллели, принадлежащие исследуемым людям, происходят из различных существующих или прошлых популяций. Модель и различные алгоритмы вывода позволяют ученым оценивать частоты аллелей в этих исходных популяциях и происхождение аллелей, переносимых исследуемыми людьми. Исходные популяции можно интерпретировать постфактум с точки зрения различных эволюционных сценариев. В ассоциативных исследованиях обнаружение наличия генетической структуры считается необходимым предварительным шагом, чтобы избежать смешения.
инженерии
Одним из примеров LDA в инженерии является автоматическая классификация документов и оцените их актуальность для различных тем.
В LDA каждый документ можно рассматривать как смесь различных разделов, где каждый документ считается имеющим набор разделов, назначенных ему через LDA. Это идентично вероятностному латентно-семантическому анализу (pLSA), за исключением того, что в LDA предполагается, что распределение тем имеет разреженный Dirichlet предшествующий. Редкие априорные значения Дирихле кодируют интуицию, что документы охватывают лишь небольшой набор тем и что в темах часто используется только небольшой набор слов. На практике это приводит к лучшему устранению неоднозначности слов и более точному распределению документов по темам. LDA - это обобщение модели pLSA, которая эквивалентна LDA при равномерном априорном распределении Дирихле.
Например, модель LDA может иметь разделы, которые можно классифицировать как CAT_related и DOG_related . Тема может генерировать различные слова, такие как молоко, мяуканье и котенок, которые могут быть классифицированы и интерпретированы зрителем как "CAT_related". Естественно, что само слово «кошка» будет иметь большую вероятность в данной теме. Тема, связанная с DOG_related, также имеет вероятность генерирования каждого слова: щенок, лай и кость могут иметь высокую вероятность. Слова без особой значимости, такие как «the» (см. функциональное слово ), будут иметь примерно одинаковую вероятность между классами (или могут быть помещены в отдельную категорию). Тема не имеет четкого определения ни семантически, ни эпистемологически. Выявляется на основе автоматического определения вероятности совпадения терминов. Лексическое слово может встречаться в нескольких темах с разной вероятностью, однако с разным типичным набором соседних слов в каждой теме.
Предполагается, что каждый документ охарактеризован определенным набором тем. Это похоже на стандартное допущение модели пакета слов и делает отдельные слова взаимозаменяемыми.
Модель
 Обозначение на пластине
Обозначение на пластине, представляющее модель LDA.
С обозначение на табличке, которое часто используется для представления вероятностных графических моделей (PGM), зависимости между многими переменными могут быть кратко зафиксированы. Ящики представляют собой «тарелки», представляющие реплики, которые являются повторяющимися объектами. Внешняя пластина представляет документы, а внутренняя пластина представляет повторяющиеся позиции слов в данном документе; каждая позиция связана с выбором темы и слова. Имена переменных определены следующим образом:
- M обозначает количество документов
- N - количество слов в данном документе (документ i имеет
 слов)
слов) - α - параметр предшествующего Дирихле в распределении тем по каждому документу
- β - параметр предшествующего Дирихле при распределении слов по темам
 - распределение тем для документа i
- распределение тем для документа i - это распределение слов для темы k
- это распределение слов для темы k - тема для j-го слова в документе i
- тема для j-го слова в документе i - это конкретное слово.
- это конкретное слово.
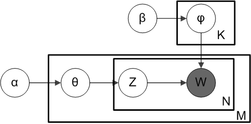
Обозначение на табличке для LDA с распределением тематических слов по Дирихле
Тот факт, что W выделен серым цветом, означает, что слова - единственные наблюдаемые переменные, а остальные переменные - скрытые переменные. Как было предложено в исходной статье, редкий априор Дирихле можно использовать для моделирования распределения тематических слов, следуя интуиции, что распределение вероятностей по словам в теме искажено, так что только небольшой набор слов имеет высокую вероятность. Полученная модель является наиболее широко применяемым вариантом LDA сегодня. Обозначение на табличке для этой модели показано справа, где  обозначает количество тем, а
обозначает количество тем, а  - это
- это  -мерные векторы, хранящие параметры тематического слова, распределенного по Дирихле. распределения (- количество слов в словаре).
-мерные векторы, хранящие параметры тематического слова, распределенного по Дирихле. распределения (- количество слов в словаре).
Полезно рассматривать сущности, представленные  и
и  как матрицы, созданные путем декомпозиции исходной матрицы документа-слова, представляющей корпус моделируемых документов. В этом представлении состоит из строк, определенных документами, и столбцов, определенных тем, а состоит из строк, определяемых темами, и столбцов, определяемых словами. Таким образом, относится к набору строк или векторов, каждый из который является распределением по словам, а
как матрицы, созданные путем декомпозиции исходной матрицы документа-слова, представляющей корпус моделируемых документов. В этом представлении состоит из строк, определенных документами, и столбцов, определенных тем, а состоит из строк, определяемых темами, и столбцов, определяемых словами. Таким образом, относится к набору строк или векторов, каждый из который является распределением по словам, а  относится к набору строк, каждая из которых представляет собой распределение по темам.
относится к набору строк, каждая из которых представляет собой распределение по темам.
Генерирующий процесс
Чтобы фактически вывести темы в корпусе, мы представляем генерирующий процесс, посредством которого создаются документы, так что мы можем сделать вывод или реконструировать их. Мы представляем себе порождающий процесс следующим образом. Документы представлены как случайные смеси по скрытым темам, где каждая тема характеризуется распределением по всем словам. LDA предполагает следующий процесс генерации для корпуса  , состоящего из
, состоящего из  документов, каждый длиной :
документов, каждый длиной :
1. Выберите  , где
, где  и
и  - это распределение Дирихле с симметричным параметром
- это распределение Дирихле с симметричным параметром  , который обычно является разреженным (
, который обычно является разреженным ( )
)
2. Выберите  , где
, где  и
и  обычно разреженные
обычно разреженные
3. Для каждого позиций слов  , где и
, где и 
- (a) Выберите тему

- (b) Выберите слово

(Обратите внимание, что полиномиальное распределение здесь относится к полиномиальному только с одним испытанием, которое также известно как категориальное распределение.)
Длина обрабатывается независимо от всех других переменных, генерирующих данные ( и
и  ). Нижний индекс часто опускается, как на диаграммах, показанных здесь.
). Нижний индекс часто опускается, как на диаграммах, показанных здесь.
Определение
Формальное описание LDA выглядит следующим образом:
Определение переменных в модели| Переменная | Тип | Значение |
|---|
| integer | количество тем (например, 50) |
| integer | количество слов в словаре (например, 50 000 или 1 000 000) |
| integer | количество документов |
 | integer | количество слов в документе d |
 | integer | общее количество слов во всех документах; сумма всех значений  , т.е. , т.е.  |
 | положительное вещественное число | предшествующий вес темы k в документ; обычно одинаково для всех тем; обычно число меньше 1, например 0.1, чтобы предпочесть редкое распределение тем, то есть несколько тем в документе |
 | K-мерный вектор положительных вещественных чисел | совокупность всех  значения, рассматриваемые как один вектор значения, рассматриваемые как один вектор |
 | положительное действительное | предшествующий вес слова w в теме; обычно одинаково для всех слов; обычно число намного меньше 1, например 0,001, чтобы строго предпочесть редкое распределение слов, то есть несколько слов на тему |
 | V-мерный вектор положительных вещественных чисел | совокупность всех  значений, рассматриваемых как один вектор значений, рассматриваемых как один вектор |
 | вероятность (действительное число от 0 до 1) | вероятность того, что слово w встречается в теме k |
 | V-мерный вектор вероятностей, который должен суммироваться в 1 | распределение слов в теме k |
 | вероятность (действительное число от 0 до 1) | вероятность появления темы k в документе d |
 | K-мерный вектор вероятностей, что в сумме должно составлять 1 | распределение тем в документе d |
 | целое число от 1 до K | идентичность темы слова w в документе d |
 | N-мерный вектор целых чисел от 1 до K | идентичность темы всех слов во всех документах |
 | целое число от 1 до V | идентичность слова w в документе d |
 | N-мерный вектор целых чисел от 1 до V | идентичность всех слов во всех документах |
Мы можем затем математически описать случайные величины следующим образом:

Вывод
Изучение различных распределений (набор тем, связанные с ними вероятности слов, тема каждого слова и конкретная смесь тем каждого документа) является проблемой статистического вывода.
моделирования Монте-Карло
Исходная статья Pritchard et al. использовали аппроксимацию апостериорного распределения методом Монте-Карло. Альтернативные предложения методов вывода включают выборку Гиббса.
Вариационный байесовский
В исходной статье ML использовалось вариационное байесовское приближение апостериорного распределения ;
максимизация правдоподобия
Прямая оптимизация вероятности с помощью алгоритма релаксации блоков оказывается быстрой альтернативой MCMC.
Неизвестное количество популяций / тем
На практике наиболее адекватное количество население или темы заранее не известны. Это можно оценить путем оценки апостериорного распределения с помощью [Обратимый скачок цепи Маркова Монте-Карло]
Альтернативные подходы
Альтернативные подходы включают распространение математического ожидания.
. Недавние исследования были сосредоточены на ускорение вывода скрытого распределения Дирихле для поддержки захвата огромного количества тем в большом количестве документов. Уравнение обновления свернутого пробоотборника Гиббса, упомянутое в предыдущем разделе, имеет естественную разреженность, которой можно воспользоваться. Интуитивно понятно, поскольку каждый документ содержит только подмножество тем  , а слово также появляется только в подмножестве тем
, а слово также появляется только в подмножестве тем  , приведенное выше уравнение обновления можно переписать, чтобы воспользоваться преимуществом этой разреженности.
, приведенное выше уравнение обновления можно переписать, чтобы воспользоваться преимуществом этой разреженности.

В этом В уравнении у нас есть три члена, два из которых являются разреженными, а другой - маленькими. Мы называем эти термины  и
и  соответственно. Теперь, если мы нормализуем каждый член путем суммирования по всем темам, мы получим:
соответственно. Теперь, если мы нормализуем каждый член путем суммирования по всем темам, мы получим:



Здесь мы видим, что  - это сумма тем, которые появляются в документе
- это сумма тем, которые появляются в документе  и
и  также является разреженным суммированием тем, которым присвоено слово по всему корпусу.
также является разреженным суммированием тем, которым присвоено слово по всему корпусу.  , с другой стороны, плотный, но из-за малых значений , значение очень мало по сравнению с двумя другими членами.
, с другой стороны, плотный, но из-за малых значений , значение очень мало по сравнению с двумя другими членами.
Теперь, при отборе темы, если мы выбираем случайную величину равномерно из  , мы можем проверить, в какую корзину приземляется наш образец. Поскольку невелик, мы вряд ли попадем в эту ведро; однако, если мы все же попадаем в эту корзину, выборка темы занимает
, мы можем проверить, в какую корзину приземляется наш образец. Поскольку невелик, мы вряд ли попадем в эту ведро; однако, если мы все же попадаем в эту корзину, выборка темы занимает  времени (так же, как и исходный сэмплер Collapsed Gibbs). Однако, если мы попадаем в две другие группы, нам нужно будет проверить только подмножество тем, если мы будем вести учет разреженных тем. Выбор темы можно выбрать из сегмента за
времени (так же, как и исходный сэмплер Collapsed Gibbs). Однако, если мы попадаем в две другие группы, нам нужно будет проверить только подмножество тем, если мы будем вести учет разреженных тем. Выбор темы можно выбрать из сегмента за  время, и тема может быть выбрана из сегмента в
время, и тема может быть выбрана из сегмента в  время, где и обозначает количество тем, назначенных текущий документ и текущий тип слова соответственно.
время, где и обозначает количество тем, назначенных текущий документ и текущий тип слова соответственно.
Обратите внимание, что после выборки каждой темы обновление этих сегментов - это все основные  арифметические операции.
арифметические операции.
Аспекты вычислительных деталей
Ниже приводится вывод уравнений для свернутой выборки Гиббса, что означает s и s будут интегрированы. Для простоты в этом выводе предполагается, что все документы имеют одинаковую длину  . Вывод также действителен, если длина документа различается.
. Вывод также действителен, если длина документа различается.
Согласно модели, полная вероятность модели равна:

где жирным шрифтом переменные обозначают векторную версию переменных. Во-первых,  и
и  должны быть интегрирован.
должны быть интегрирован.

Все независимы друг от друга и одинаковы для всех с. Таким образом, мы можем обрабатывать каждый и каждый отдельно. Теперь мы сосредоточимся только на части .

В дальнейшем мы можем сосредоточиться только на одном , а именно:

Фактически, это скрытая часть модели для  документ. Теперь мы заменим вероятности в приведенном выше уравнении истинным выражением распределения, чтобы записать явное уравнение.
документ. Теперь мы заменим вероятности в приведенном выше уравнении истинным выражением распределения, чтобы записать явное уравнение.

Пусть  будет количеством токенов слов в документ с тем же символом слова (
будет количеством токенов слов в документ с тем же символом слова ( слово в словаре), присвоенный
слово в словаре), присвоенный  тема. Итак, трехмерно. Если какое-либо из трех измерений не ограничено конкретным значением, мы используем точку в скобках
тема. Итак, трехмерно. Если какое-либо из трех измерений не ограничено конкретным значением, мы используем точку в скобках  для обозначения. Например,
для обозначения. Например,  обозначает количество токенов слов в документ, назначенный теме . Таким образом, большая правая часть приведенного выше уравнения может быть переписана как:
обозначает количество токенов слов в документ, назначенный теме . Таким образом, большая правая часть приведенного выше уравнения может быть переписана как:

Таким образом, формула интегрирования  может можно заменить на:
может можно заменить на:

Очевидно, уравнение внутри интегрирования имеет тот же вид, что и распределение Дирихле. Согласно распределению Дирихле,

Таким образом,
![{\ displaystyle {\ begin {a ligned} \ int _ {\ theta _ {j}} P (\ theta _ {j}; \ alpha) \ prod _ {t = 1} ^ {N} P (Z_ {j, t} \ mid \ theta _ {j}) \, d \ theta _ {j} = \ int _ {\ theta _ {j}} {\ frac {\ Gamma \ left (\ sum _ {i = 1} ^ {K} \ alpha _ {i} \ right)} {\ prod _ {i = 1} ^ {K} \ Gamma (\ alpha _ {i})}} \ prod _ {i = 1} ^ {K} \ theta _ {j, i} ^ {n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i} -1} \, d \ theta _ {j} \\ [8pt] = {} {\ frac {\ Гамма \ left (\ sum _ {i = 1} ^ {K} \ alpha _ {i} \ right)} {\ prod _ {i = 1} ^ {K} \ Gamma (\ alpha _ {i})} } {\ frac {\ prod _ {i = 1} ^ {K} \ Gamma (n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i})} {\ Gamma \ left (\ sum _ {i = 1} ^ {K} n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)}} \ int _ {\ theta _ {j}} {\ frac { \ Gamma \ left (\ sum _ {i = 1} ^ {K} n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)} {\ prod _ {i = 1} ^ {K} \ Gamma (n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i})}} \ prod _ {i = 1} ^ {K} \ theta _ {j, i} ^ {n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i} -1} \, d \ theta _ {j} \\ [8pt] = {} {\ frac {\ Gamma \ left (\ sum _ {i = 1} ^ {K} \ alpha _ {i} \ right)} {\ prod _ {i = 1} ^ {K} \ Gamma (\ alpha _ {i})}} { \ frac {\ prod _ {i = 1} ^ {K} \ Gamma (n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i})} {\ Gamma \ left (\ sum _ { i = 1} ^ {K} n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)}}. \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b0ca8f630b1bb40e60740fb26f4e3d6fc889a91e)
Теперь обратим внимание на часть. На самом деле происхождение части очень похоже на часть. Здесь мы лишь перечисляем этапы вывода:
![{\ displaystyle {\ begin {align} \ int _ {\ boldsymbol {\ varphi}} \ prod _ {i = 1} ^ {K} P (\ varphi _ {i}; \ beta) \ prod _ {j = 1} ^ {M} \ prod _ {t = 1} ^ {N} P (W_ {j, t} \ mid \ varphi _ {Z_ {j, t}}) \, d {\ boldsymbol {\ varphi}} \\ [8pt] = { } \ prod _ {i = 1} ^ {K} \ int _ {\ varphi _ {i}} P (\ varphi _ {i}; \ beta) \ prod _ {j = 1} ^ {M} \ prod _ {t = 1} ^ {N} P (W_ {j, t} \ mid \ varphi _ {Z_ {j, t}}) \, d \ varphi _ {i} \\ [8pt] = {} \ prod _ {i = 1} ^ {K} \ int _ {\ varphi _ {i}} {\ frac {\ Gamma \ left (\ sum _ {r = 1} ^ {V} \ beta _ {r } \ right)} {\ prod _ {r = 1} ^ {V} \ Gamma (\ beta _ {r})}} \ prod _ {r = 1} ^ {V} \ varphi _ {i, r} ^ {\ beta _ {r} -1} \ prod _ {r = 1} ^ {V} \ varphi _ {i, r} ^ {n _ {(\ cdot), r} ^ {i}} \, d \ varphi _ {i} \\ [8pt] = {} \ prod _ {i = 1} ^ {K} \ int _ {\ varphi _ {i}} {\ frac {\ Gamma \ left (\ sum _ {r = 1} ^ {V} \ beta _ {r} \ right)} {\ prod _ {r = 1} ^ {V} \ Gamma (\ beta _ {r})}} \ prod _ {r = 1} ^ {V} \ varphi _ {i, r} ^ {n _ {(\ cdot), r} ^ {i} + \ beta _ {r} -1} \, d \ varphi _ {i} \\ [8pt] = {} \ prod _ {i = 1} ^ {K} {\ frac {\ Gamma \ left (\ sum _ {r = 1} ^ {V} \ beta _ {r} \ right)} {\ prod _ {r = 1} ^ {V} \ Gamma (\ beta _ {r})}} {\ frac {\ prod _ {r = 1} ^ {V} \ Gamma (n _ {(\ cdot), r} ^ {i} + \ beta _ {r})} {\ Gamma \ left (\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {i} + \ beta _ {r} \ right)}}. \ End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f7c384ec331b3f57afe6041d314cf4a8a23078c8)
Для ясности здесь мы записываем окончательное уравнение как с  , так и с интегрировано:
, так и с интегрировано:

Здесь цель Гиббса Сэмплинга - аппроксимировать распределение из  . Поскольку
. Поскольку  неизменно для любого из Z, уравнения выборки Гиббса могут быть производное от
неизменно для любого из Z, уравнения выборки Гиббса могут быть производное от  непосредственно. Ключевым моментом является получение следующей условной вероятности:
непосредственно. Ключевым моментом является получение следующей условной вероятности:

где  обозначает
обозначает  скрытая переменная
скрытая переменная  word token в
word token в  документ. И далее мы предполагаем, что его словесным символом является слово
документ. И далее мы предполагаем, что его словесным символом является слово  в словаре.
в словаре.  обозначает все s, но . Обратите внимание, что выборке Гиббса необходимо только выбрать значение для , в соответствии с указанной выше вероятностью, нам не нужен точное значение
обозначает все s, но . Обратите внимание, что выборке Гиббса необходимо только выбрать значение для , в соответствии с указанной выше вероятностью, нам не нужен точное значение

, но отношения между вероятностями, которые может принимать значение. So, the above equation can be simplified as:
![{\ displaystyle {\ begin {align} P (Z _ {(m, n)} = v \ mid {\ boldsymbol {Z _ {- (m, n)}}}, {\ boldsymbol {W}}; \ alpha, \ beta) \\ [8pt] \ propto P (Z _ {( m, n)} = v, {\ boldsymbol {Z _ {- (m, n)}}}, {\ boldsymbol {W}}; \ alpha, \ beta) \\ [8pt] = \ left ({\ frac {\ Gamma \ left (\ sum _ {i = 1} ^ {K} \ alpha _ {i} \ right)} {\ prod _ {i = 1} ^ {K} \ Gamma (\ alpha _ {i })}} \ right) ^ {M} \ prod _ {j \ neq m} {\ frac {\ prod _ {i = 1} ^ {K} \ Gamma \ left (n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)} {\ Gamma \ left (\ sum _ {i = 1} ^ {K} n_ {j, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)}} \ left ({\ frac {\ Gamma \ left (\ sum _ {r = 1} ^ {V} \ beta _ {r} \ right)} {\ prod _ {r = 1 } ^ {V} \ Gamma (\ beta _ {r})}} \ right) ^ {K} \ prod _ {i = 1} ^ {K} \ prod _ {r \ neq v} \ Gamma \ left ( n _ {(\ cdot), r} ^ {i} + \ beta _ {r} \ right) {\ frac {\ prod _ {i = 1} ^ {K} \ Gamma \ left (n_ {m, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)} {\ Gamma \ left (\ sum _ {i = 1} ^ {K} n_ {m, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)}} \ prod _ {i = 1} ^ {K} {\ frac {\ Gamma \ left (n _ {(\ cdot), v} ^ {i} + \ b eta _ {v} \ right)} {\ Gamma \ left (\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {i} + \ beta _ {r} \ right) }} \\ [8pt] \ propto {\ frac {\ prod _ {i = 1} ^ {K} \ Gamma \ left (n_ {m, (\ cdot)} ^ {i} + \ alpha _ {i } \ right)} {\ Gamma \ left (\ sum _ {i = 1} ^ {K} n_ {m, (\ cdot)} ^ {i} + \ alpha _ {i} \ right)}} \ prod _ {i = 1} ^ {K} {\ frac {\ Gamma \ left (n _ {(\ cdot), v} ^ {i} + \ beta _ {v} \ right)} {\ Gamma \ left (\ сумма _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {i} + \ beta _ {r} \ right)}} \\ [8pt] \ propto \ prod _ {i = 1} ^ {K} \ Gamma \ left (n_ {m, (\ cdot)} ^ {i} + \ alpha _ {i} \ right) \ prod _ {i = 1} ^ {K} {\ frac { \ Gamma \ left (n _ {(\ cdot), v} ^ {i} + \ beta _ {v} \ right)} {\ Gamma \ left (\ sum _ {r = 1} ^ {V} n _ {( \ cdot), r} ^ {i} + \ beta _ {r} \ right)}}. \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7fe6d72364192958aa83fde4acd332d697a34a50)
Finally, let  be the same meaning as but with the excluded. The above equation can be further simplified leveraging the property of gamma function. We first split the summation and then merge it back to obtain a
be the same meaning as but with the excluded. The above equation can be further simplified leveraging the property of gamma function. We first split the summation and then merge it back to obtain a  -independent summation, which could be dropped:
-independent summation, which could be dropped:
![{\ displaystyle {\ begin {align} \ propto \ prod _ {i \ neq k} \ Гамма \ left (n_ {m, (\ cdot)} ^ {i, - (m, n)} + \ alpha _ {i} \ right) \ prod _ {i \ neq k} {\ frac {\ Gamma \ left (n _ {(\ cdot), v} ^ {i, - (m, n)} + \ beta _ {v} \ right)} {\ Gamma \ left (\ sum _ {r = 1} ^ {V } n _ {(\ cdot), r} ^ {i, - (m, n)} + \ beta _ {r} \ right)}} \ Gamma \ left (n_ {m, (\ cdot)} ^ {k, - (m, n)} + \ alpha _ {k} +1 \ right) {\ frac {\ Gamma \ left (n _ {(\ cdot), v} ^ {k, - (m, n)} + \ beta _ {v} +1 \ right)} {\ Gamma \ left (\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {k, - (m, n)} + \ beta _ {r} +1 \ right)}} \\ [8pt] = \ prod _ {i \ neq k} \ Gamma \ left (n_ {m, (\ cdot)} ^ {i, - (m, n)} + \ alpha _ {i} \ right) \ prod _ {i \ neq k} {\ frac {\ Gamma \ left (n _ {(\ cdot), v} ^ {i, - (m, n)} + \ beta _ {v} \ right)} {\ Gamma \ left (\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {i, - ( m, n)} + \ beta _ {r} \ right)}} \ Gamma \ left (n_ {m, (\ cdot)} ^ {k, - (m, n)} + \ alpha _ {k} \ справа) {\ frac {\ Gamma \ left (n _ {(\ cdot), v} ^ {k, - (m, n)} + \ beta _ {v} \ right)} {\ Gamma \ left (\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {k, - (m, n)} + \ beta _ {r} \ right)}} \ left (n_ {m, ( \ cdot)} ^ {k, - (m, n)} + \ alpha _ {k} +1 \ right) {\ frac {n _ {(\ cdot), v} ^ {k, - (m, n) } + \ beta _ {v} +1} {\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {k, - (m, n)} + \ beta _ {r } +1}} \\ [8pt] = \ prod _ {i} \ Gamma \ left (n_ {m, (\ cdot)} ^ {i, - (m, n)} + \ alpha _ {i} \ right) \ prod _ {i} {\ frac {\ Gamma \ left (n _ {(\ cdot), v} ^ {i, - (m, n)} + \ beta _ {v} \ right)} { \ Gamma \ left (\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {i, - (m, n)} + \ beta _ {r} \ right)}} \ слева (n_ {m, ( \ cdot)} ^ {k, - (m, n)} + \ alpha _ {k} +1 \ right) {\ frac {n _ {(\ cdot), v} ^ {k, - (m, n) } + \ beta _ {v} +1} {\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {k, - (m, n)} + \ beta _ {r } +1}} \\ [8pt] \ propto \ left (n_ {m, (\ cdot)} ^ {k, - (m, n)} + \ alpha _ {k} +1 \ right) {\ frac {n _ {(\ cdot), v} ^ {k, - (m, n)} + \ beta _ {v} +1} {\ sum _ {r = 1} ^ {V} n _ {(\ cdot), r} ^ {k, - (m, n)} + \ beta _ {r} +1}} \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b508981420a89f48579f0a12a5bd4d354f41f8c)
Обратите внимание, что та же формула выводится в статье о полиномиальном распределении Дирихле в рамках более общего обсуждения интегрирования априорных значений распределения Дирихле из Байесовская сеть.
Связанные проблемы
Связанные модели
Тематическое моделирование - классическое решение проблемы поиска информации с использованием связанных данных и технологии семантической паутины. К связанным моделям и методам относятся, среди прочего, скрытое семантическое индексирование, анализ независимых компонентов, вероятностное скрытое семантическое индексирование, неотрицательная матричная факторизация и Гамма-распределение Пуассона.
Модель LDA очень модульная и поэтому может быть легко расширена. Основная область интересов - моделирование отношений между темами. Это достигается за счет использования другого распределения на симплексе вместо Дирихле. Модель коррелированных тем следует этому подходу, создавая структуру корреляции между темами с использованием логистического нормального распределения вместо Дирихле. Другое расширение - иерархический LDA (hLDA), где темы объединяются в иерархию с помощью вложенного процесса Китайский ресторан, структура которого извлекается из данных. LDA также может быть расширено до корпуса, в котором документ включает два типа информации (например, слова и имена), как в. Непараметрические расширения LDA включают иерархическую модель процесса Дирихле, которая позволяет неограниченному количеству тем и извлекать их из данных.
Как отмечалось ранее, pLSA аналогичен LDA. Модель LDA - это, по сути, байесовская версия модели pLSA. Байесовская формулировка обычно лучше работает с небольшими наборами данных, потому что байесовские методы позволяют избежать переобучения данных. Для очень больших наборов данных результаты двух моделей имеют тенденцию сходиться. Одно отличие состоит в том, что pLSA использует переменную для представления документа в обучающем наборе. Итак, в pLSA, когда представлен документ, который модель еще не видела, мы фиксируем  - вероятность слова под темами - должны быть изучены из обучающей выборки и использовать тот же алгоритм EM для вывода
- вероятность слова под темами - должны быть изучены из обучающей выборки и использовать тот же алгоритм EM для вывода  - тема распределение под . Блей утверждает, что этот шаг является обманом, поскольку вы, по сути, перестраиваете модель в соответствии с новыми данными.
- тема распределение под . Блей утверждает, что этот шаг является обманом, поскольку вы, по сути, перестраиваете модель в соответствии с новыми данными.
Пространственные модели
В эволюционной биологии часто естественно предположить, что географическое положение наблюдаемых особей несут некоторую информацию об их предках. Это рациональный вариант различных моделей генетических данных с географической привязкой.
Варианты LDA использовались для автоматического разделения естественных изображений на категории, такие как «спальня» или «лес», путем обработки изображения как документа., и небольшие участки изображения в виде слов; одна из вариаций называется.
См. также
Ссылки
Внешние ссылки
- jLDADMM Пакет Java для моделирования тем на обычных или коротких текстах. jLDADMM включает в себя реализации тематической модели LDA и полиномиальной смеси Дирихле, состоящей из одной темы для каждого документа. jLDADMM также предоставляет реализацию для оценки кластеризации документов для сравнения тематических моделей.
- Пакет Java для моделирования коротких текстовых тем (https://github.com/qiang2100/STTM ). STTM включает следующие алгоритмы: Полиномиальная смесь Дирихле (DMM) на конференции KDD2014, Тематическая модель Битерма (BTM) в журнале TKDE2016, Сетевая тематическая модель Word (WNTM) в журнале KAIS2018, Тематическая модель на основе псевдодокументов (PTM) на конференции KDD2016, Тематическая модель на основе самоагрегации (SATM) на конференции IJCAI2015, (ETM) на конференции PAKDD2017, Обобщенная модель полиномиальной смеси Дирихле (GPU-DMM) на основе обобщенной урны Поля (GPU) на конференции SIGIR2016, Generalized P´olya Urn (GPU)) основанная на Пуассоне модель полиномиальной смеси Дирихле (GPU-PDMM) в журнале TIS2017 и модель скрытых функций с DMM (LF-DMM) в журнале TACL2015. STTM также включает шесть корпусов коротких текстов для оценки. STTM представляет три аспекта оценки производительности алгоритмов (т. Е. Согласованность тем, кластеризацию и классификацию).
- Лекция, в которой рассматриваются некоторые из обозначений в этой статье: LDA и видео по тематическому моделированию Лекция Дэвида Блея или та же лекция на YouTube
- Д. Библиография Mimno LDA Исчерпывающий список ресурсов, связанных с LDA (включая документы и некоторые реализации)
- Gensim, Python + NumPy реализация онлайн-LDA для входных данных, превышающих доступную RAM.
- topicmodels и lda - это два пакета R для анализа LDA.
- «Анализ текста с помощью R», включая методы LDA, видеопрезентация для Октябрь 2011 г. Встреча группы пользователей R в Лос-Анджелесе
- MALLET Пакет на основе Java с открытым исходным кодом от Массачусетского университета в Амхерсте для тематического моделирования с помощью LDA, также имеет независимо разработанный графический интерфейс, инструмент тематического моделирования
- LDA в Mahout реализация LDA с использованием MapReduce на платформе Hadoop
- Руководство по скрытому распределению Дирихле (LDA) для платформы машинных вычислений Infer.NET Microsoft Research C # Machine Learning Framework
- LDA в Spark : Начиная с версии 1.3.0, Apache Spark также включает реализацию LDA
- LDA, exampleLDA Реализация MATLAB

 Обозначение на пластине, представляющее модель LDA.
Обозначение на пластине, представляющее модель LDA.