
Войти
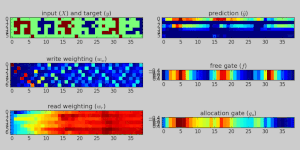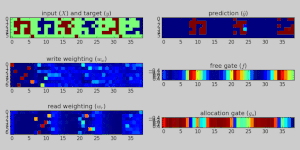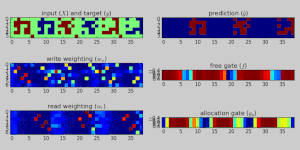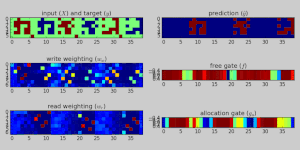 Дифференцируемый нейронный компьютер, обученный хранить и вспоминать плотные двоичные числа. Показано выполнение эталонного задания во время обучения. Вверху слева: вход (красный) и цель (синий) в виде 5-битных слов и 1-битного сигнала прерывания. Вверху справа: результат модели.
Дифференцируемый нейронный компьютер, обученный хранить и вспоминать плотные двоичные числа. Показано выполнение эталонного задания во время обучения. Вверху слева: вход (красный) и цель (синий) в виде 5-битных слов и 1-битного сигнала прерывания. Вверху справа: результат модели. В искусственном интеллекте, дифференцируемый нейронный компьютер (DNC ) - это нейронная сеть с расширенной памятью архитектура (MANN), которая обычно (не по определению) повторяется в своей реализации. Модель была опубликована в 2016 году Алексом Грейвсом и др. из DeepMind.
DNC косвенно черпает вдохновение в архитектуре фон-Неймана, что делает его более эффективным, чем обычные архитектуры в задачах, которые в основном являются алгоритмическими, которые невозможно изучить, найдя границу принятия решения.
До сих пор DNC было продемонстрировано, что он справляется только с относительно простыми задачами, которые можно решить с помощью обычного программирования. Но DNC не нужно программировать для каждой задачи, их можно обучить. Эта концентрация внимания позволяет пользователю последовательно загружать сложные структуры данных, такие как графики, и вызывать их для дальнейшего использования. Кроме того, они могут изучить аспекты символического мышления и применить его к рабочей памяти. Исследователи, опубликовавшие этот метод, видят обещание, что DNC можно обучить для выполнения сложных, структурированных задач и работы с приложениями с большими данными, которые требуют каких-то рассуждений, таких как создание видео-комментариев или семантический анализ текста.
DNC может быть обученным ориентироваться в системах скоростного транспорта и применять эту сеть к другой системе. Нейронной сети без памяти, как правило, придется изучать каждую транзитную систему с нуля. В задачах обхода графа и обработки последовательностей с контролируемым обучением DNC работали лучше, чем альтернативы, такие как долговременная краткосрочная память или нейронная машина Тьюринга. Используя подход обучения с подкреплением к задаче головоломки с блоками, вдохновленный SHRDLU, DNC прошел обучение по учебной программе и научился составлять план. Он работал лучше, чем традиционная рекуррентная нейронная сеть.
 Схема системы DNC
Схема системы DNC Сети DNC были представлены как расширение нейронной машины Тьюринга (NTM) с добавлением механизмов внимания к памяти, которые контролируют, где хранится память, и временного внимания, которое записывает порядок событий. Эта структура позволяет DNC быть более надежным и абстрактным, чем NTM, и при этом выполнять задачи, которые имеют более долгосрочные зависимости, чем некоторые предшественники, такие как Long Short Term Memory (LSTM ). Память, которая представляет собой просто матрицу, может быть распределена динамически и доступна неограниченное время. DNC является дифференцируемым сквозным (дифференцируемым каждый подкомпонент модели, следовательно, и вся модель). Это позволяет их эффективно оптимизировать с помощью градиентного спуска.
Модель DNC похожа на архитектуру фон Неймана, а из-за возможности изменения размера памяти она полная по Тьюрингу.
DNC, как было изначально опубликовано
| Независимые переменные | |
 | Входной вектор |
 | Целевой вектор |
| Контроллер | |
![{\ displaystyle {\ boldsymbol {\ chi}} _ {t} = [\ mathbf {x} _ {t}; \ mathbf {r} _ {t-1} ^ {1}; \ cdots; \ mathbf {r} _ {t-1} ^ {R}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8dec60603b7024ea42c602067cf7fed7184851d5) | Входная матрица контроллера |
| Глубокая (многоуровневая) LSTM |  |
![{\ displaystyle \ mathbf {i} _ {t} ^ {l} = \ sigma (W_ {i} ^ { l} [{\ boldsymbol {\ chi}} _ {t}; \ mathbf {h} _ {t-1} ^ {l}; \ mathbf {h} _ {t} ^ {l-1}] + \ mathbf {b} _ {я} ^ {l})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f7b63c2194165c25155e0604360a17406eaa1d42) | Вектор входных вентилей |
![{\ displaystyle \ mathbf {o} _ {t} ^ {l} = \ sigma (W_ {o} ^ {l} [{\ boldsymbol {\ chi}} _ {t }; \ mathbf {h} _ {t-1} ^ {l}; \ mathbf {h} _ {t} ^ {l-1}] + \ mathbf {b} _ {o} ^ {l})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8cb063978596affe73a9754909bd30027c7eadaa) | Выходной вентильный вектор |
![{\ displaystyle \ mathbf {f} _ {t} ^ {l} = \ sigma (W_ {f} ^ {l} [ {\ boldsymbol {\ chi}} _ {t}; \ mathbf {h} _ {t-1} ^ {l}; \ mathbf {h} _ {t} ^ {l-1}] + \ mathbf {b } _ {f} ^ {l})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6af4718cebc04481991be06b7b6f6b8e67bdb373) | Забыть вектор гейта |
![{\ displaystyle \ mathbf {s} _ {t} ^ {l} = \ mathbf {f} _ {t} ^ {l} \ mathbf {s} _ {t-1} ^ {l} + \ mathbf {i} _ {t} ^ {l} \ tanh (W_ {s} ^ {l} [{\ boldsymbol {\ chi}} _ {t}; \ mathbf {h} _ {t-1} ^ {l }; \ mathbf {h} _ {t} ^ {l-1}] + \ mathbf {b} _ {s} ^ {l})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5fe84e8845b67ed46b34d744eca147c7461221e7) | Вектор состояния ворот,.  |
 | Вектор скрытых ворот,.  |
![{\ displaystyle \ mathbf {y} _ {t} = W_ {y} [\ mathbf {h} _ {t} ^ {1}; \ cdots; \ mathbf {h} _ {t} ^ {L}] + W_ {r} [\ mathbf {r} _ {t} ^ {1}; \ cdots; \ mathbf {r} _ {t} ^ { R}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4bc0db0d3169aa2e87d3391a99e4eeee2b13f8e6) | Вектор вывода DNC |
| Читать Записать головки | |
![{\ displaystyle \ xi _ { t} = W _ {\ xi} [h_ {t} ^ {1}; \ cdots; h_ {t} ^ {L}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbc8895544c4fbcc010baf73d02e985eed299cc4) | Параметры интерфейса |
![{\ displaystyle = [\ mathbf {k} _ {t} ^ {r, 1}; \ cdots; \ mathbf {k} _ {t} ^ {r, R}; {\ hat {\ beta}} _ {t} ^ {r, 1}; \ cdots; {\ hat {\ beta}} _ {t} ^ {r, R}; \ mathbf {k} _ {t} ^ {w}; {\ hat {\ beta _ {t} ^ {w}} }; \ mathbf {\ hat {e}} _ {t}; \ mathbf {v} _ {t}; {\ hat {f_ {t} ^ {1}}}; \ cdots; {\ hat {f_ { t} ^ {R}}}; {\ hat {g}} _ {t} ^ {a}; {\ hat {g}} _ {t} ^ {w}; {\ hat {\ boldsymbol {\ pi }}} _ {t} ^ {1}; \ cdots; {\ hat {\ boldsymbol {\ pi}}} _ {t} ^ {R}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cef0e819e7e10264b43fba029646a5800fa8c39a) | |
| Считывание головок |  |
 | Чтение ключей |
 | Прочитать силу |
 | Свободные ворота |
 | Режимы чтения,.  |
| Записать голову | |
 | Записать ключ |
 | Сила записи |
 | Удалить вектор |
 | Записать вектор |
 | Шлюз распределения |
 | Шлюз записи |
| Память | |
 | Матрица памяти,. Матрица единиц  |
 | Вектор использования |
![{\ displaystyle \ mathbf {p} _ {t} = \ left (1- \ sum _ {i} \ mathbf {w} _ {t} ^ {w} [i] \ right) \ mathbf {p } _ {t-1} + \ mathbf {w} _ {t} ^ {w}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f30fcef519fd4b5cc521fe641b6847c7b389d6a4) | Взвешивание приоритета,.  |
![{\ displaystyle L_ {t} = (\ mathbf {1} - \ mathbf {I}) \ left [(1- \ mathbf {w} _ {t} ^ {w} [i] - \ mathbf {w} _ {t} ^ {j}) L_ {t-1} [я, j] + \ mathbf {w} _ {t} ^ {w} [i] \ mathbf {p} _ {t-1} ^ {j} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aed8ceffa8beba9c2fbb79da953ecaf28f49b8e9) | Матрица временных связей,.  |
![{\ displaystyle \ mathbf {w} _ {t} ^ {w} = g_ {t} ^ {w} [g_ {t} ^ {a} \ mathbf {a} _ {t} + (1-g_ { t} ^ {a}) \ mathbf {c} _ {t} ^ {w}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c018c70b48693438bb51ab44c2c9546949af2721) | Записать взвешивание |
![{\ Displaystyle \ м athbf {w} _ {t} ^ {r, i} = {\ boldsymbol {\ pi}} _ {t} ^ {i} [1] \ mathbf {b} _ {t} ^ {i} + {\ boldsymbol {\ pi}} _ {t} ^ {i} [2] c_ {t} ^ {r, i} + {\ boldsymbol {\ pi}} _ {t} ^ {i} [3] f_ {t } ^ {i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c77968fbcc47e7d60c4b9509a0993a9c94adb96f) | Считывание взвешивания |
 | Считать векторы |
![{\ displaystyle {\ mathcal {C}} (M, \ mathbf {k}, \ beta) [i] = {\ frac {\ exp \ {{\ mathcal {D}} (\ mathbf {k}, M [i, \ cdot]) \ beta \}} {\ sum _ {j} \ exp \ { {\ mathcal {D}} (\ mathbf {k}, M [j, \ cdot]) \ beta \}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5b03a46eac32e1a351b9e5f517313219bf25edc5) | Адресация на основе содержимого,. ключ поиска  , сила ключа , сила ключа  |
 | Индексы  ,., отсортированные в порядке возрастания использования ,., отсортированные в порядке возрастания использования |
![{\ displaystyle \ mathbf {a} _ {t} [\ phi _ {t} [j]] = (1- \ mathbf {u} _ {t} [\ phi _ { t} [j]]) \ prod _ {i = 1} ^ {j-1} \ mathbf {u} _ {t} [ \ phi _ {t} [я]]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8475e422543891326eab54ae0c866d8359849c22) | Распределение веса |
 | Запись веса содержимого |
 | Прочитать взвешивание содержимого |
 | Прямое взвешивание |
 | Обратное взвешивание |
 | Вектор сохранения памяти |
| Определения | |
 | Матрица весов, вектор смещения |
 | Матрица нулей, матрица единиц, единичная матрица |
 | Элементное умножение |
 | Косинусное сходство |
 | сигмовидная функция |
 | Функция Oneplus |
 для j = 1,…, K. для j = 1,…, K. | Функция Softmax |
Усовершенствования включают адресацию разреженной памяти, которая уменьшает временную и пространственную сложность в тысячи раз. Это может быть достигнуто с помощью алгоритма приблизительного ближайшего соседа, такого как хеширование с учетом местоположения, или случайного дерева kd, например Fast Library for Approximate Neighbours from UBC. Добавление времени адаптивных вычислений (ACT) отделяет время вычислений от времени данных, которое использует тот факт, что длина проблемы и сложность проблемы не всегда одинаковы. Обучение с использованием синтетических градиентов работает значительно лучше, чем Обратное распространение во времени (BPTT). Устойчивость может быть улучшена с помощью нормализации слоев и обхода исключения в качестве регуляризации.