
Войти
В обработке естественного языка, сущность, связывающая, также обозначается как связывание именованных сущностей (NEL), разрешение неоднозначности именованных сущностей (NED), распознавание именованных сущностей и устранение неоднозначности (NERD) или нормализация именованных сущностей (NEN) - это задача присвоения уникальной идентичности сущностям (например, известным лицам, местам или компаниям), упомянутым в тексте. Например, учитывая предложение «Париж - столица Франции», идея состоит в том, чтобы определить, что «Париж» относится к городу Париж, а не к Пэрис Хилтон или любому другому. субъект, который можно было бы назвать "Париж". Связывание сущностей отличается от распознавания именованных сущностей (NER) тем, что NER идентифицирует появление именованных сущностей в тексте, но не определяет, какой это конкретный объект (см. Отличия от других методов ).
 При связывании сущностей каждая именованная сущность связана с уникальным идентификатором. Часто этот идентификатор соответствует странице Википедии.
При связывании сущностей каждая именованная сущность связана с уникальным идентификатором. Часто этот идентификатор соответствует странице Википедии. .
При связывании объектов слова интересы (имена лиц, местоположений и компаний) отображаются из входящего текста в соответствующие уникальные сущности в целевой базе знаний. Интересующие слова называются именованными объектами (NE), упоминаниями или поверхностными формами. Целевая база знаний зависит от предполагаемого приложения, но для систем связывания сущностей, предназначенных для работы с текстом в открытом домене, обычно используются базы знаний, полученные из Википедии (например, Викиданные или DBpedia ). В этом случае каждая отдельная страница Википедии рассматривается как отдельный объект. Методы связывания сущностей, которые сопоставляют именованные сущности с сущностями Википедии, также называются викификацией .
Если снова рассмотреть пример предложения «Париж - столица Франции», ожидаемый результат системы связывания сущностей будет Париж и Франция. Эти универсальные указатели ресурсов (URL-адреса) могут использоваться как уникальные универсальные идентификаторы ресурсов (URI) для сущностей в базе знаний. Использование другой базы знаний вернет разные URI, но для баз знаний, созданных на основе Википедии, существуют однозначные сопоставления URI.
В большинстве случаев базы знаний создаются вручную, но в приложениях с большим размером текстовые корпуса доступны, база знаний может быть выведена автоматически из доступного текста.
Связывание сущностей - важный шаг для соединения веб-данных с базами знаний, что полезно для аннотирования огромного количества сырые и часто зашумленные данные в сети и вносят свой вклад в видение семантической сети. Помимо связывания сущностей, существуют другие важные шаги, включая, помимо прочего, извлечение событий, связывание событий и т. Д.
Связывание сущностей полезно в полях, которые должны извлекать абстрактные представления из текст, как это бывает при анализе текста, рекомендательных системах, семантическом поиске и чат-ботах. Во всех этих полях понятия, относящиеся к приложению, отделены от текста и других не имеющих смысла данных.
Например, типичной задачей, выполняемой поисковыми системами, является поиск похожих документов. к одному, указанному в качестве входных данных, или для поиска дополнительной информации о лицах, упомянутых в нем. Рассмотрим предложение, содержащее выражение «столица Франции»: без привязки сущностей поисковая система, просматривающая содержание документов, не сможет напрямую получить документы, содержащие слово «Париж», что приведет к так называемому ложноотрицательные (FN). Хуже того, поисковая система может выдавать ложные совпадения (или ложные срабатывания (FP)), например, при поиске документов, в которых упоминается «Франция» как страна.
Существует множество подходов, ортогональных связыванию сущностей, для извлечения документов, подобных входному документу. Например, скрытый семантический анализ (LSA) или сравнение внедрений документов, полученных с помощью doc2vec. Однако эти методы не позволяют использовать такой же детализированный контроль, который предлагается при связывании сущностей, поскольку они будут возвращать другие документы вместо создания высокоуровневых представлений исходного. Например, получение схематической информации о "Париже", представленной информационными блоками Википедии, было бы гораздо менее простым, а иногда и невозможным, в зависимости от сложности запроса.
Более того, связывание сущностей имеет был использован для повышения производительности систем поиска информации и повышения производительности поиска в электронных библиотеках. Связывание сущностей также является ключевым входом для семантического поиска.
Система связывания сущностей должна иметь дело с рядом проблем, прежде чем ее можно будет использовать в реальных приложениях. Некоторые из этих проблем присущи задаче связывания сущностей, например неоднозначность текста, в то время как другие, такие как масштабируемость и время выполнения, становятся актуальными при рассмотрении использования таких систем в реальной жизни.
NIL. Понять, когда возвращать прогноз NILнепросто, и было предложено много разных подходов; например, путем установления порога некоторой степени достоверности в системе связывания сущностей или путем добавления дополнительной сущности NILв базу знаний, которая обрабатывается так же, как и другие сущности. Более того, в некоторых случаях предоставление неверного, но связанного прогноза связи между объектами может быть лучше, чем полное отсутствие результата с точки зрения конечного пользователя.Связывание объектов также известно как устранение неоднозначности именованных сущностей (NED) и глубоко связан с викификацией и связью записей. Определения часто размыты и незначительно различаются у разных авторов: Alhelbawy et al. рассматривать связывание сущностей как более широкую версию NED, поскольку NED должен предполагать, что сущность, которая правильно соответствует определенному упоминанию сущности с текстовым именем, находится в базе знаний. Системы связывания сущностей могут иметь дело со случаями, когда в справочной базе знаний отсутствует запись для названной сущности. Другие авторы не делают такого различия и используют эти два имени как взаимозаменяемые.
Париж - столица Франции.
[Париж ] Город - это столица [Франция ] Страна.
Париж - столица Франции. Это также самый большой город во Франции.
Связывание сущностей было горячей темой в промышленности и академических кругах в последнее десятилетие. Однако на сегодняшний день большинство существующих проблем все еще не решены, и было предложено множество систем связывания сущностей с сильно различающимися сильными и слабыми сторонами.
В общих чертах, современные системы связывания сущностей могут быть разделены на две категории:
Часто системы связывания сущностей не могут быть строго отнесены к какой-либо из категорий, но они используют графы знаний, которые были обогащены дополнительными текстовыми функциями, извлеченными, например, из текстовых корпусов, которые использовались для построения самих графов знаний.
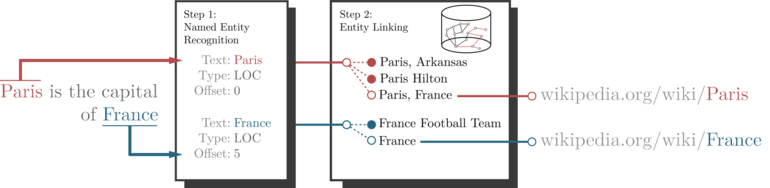 Представление основных шагов в алгоритме связывания сущностей. Большинство алгоритмов связывания сущностей состоят из начального этапа распознавания именованных сущностей, на котором именованные сущности находятся в исходном тексте (здесь, Париж и Франция), и последующего шага, на котором каждая именованная сущность связана с соответствующим ей уникальным идентификатором ( здесь, страница в Википедии). Этот последний шаг часто выполняется путем создания небольшого набора идентификаторов кандидатов для каждой именованной сущности и путем выбора наиболее многообещающего кандидата в отношении выбранной метрики.
Представление основных шагов в алгоритме связывания сущностей. Большинство алгоритмов связывания сущностей состоят из начального этапа распознавания именованных сущностей, на котором именованные сущности находятся в исходном тексте (здесь, Париж и Франция), и последующего шага, на котором каждая именованная сущность связана с соответствующим ей уникальным идентификатором ( здесь, страница в Википедии). Этот последний шаг часто выполняется путем создания небольшого набора идентификаторов кандидатов для каждой именованной сущности и путем выбора наиболее многообещающего кандидата в отношении выбранной метрики. Основная работа Кучерсан в 2007 году предложил одну из первых систем связывания сущностей, появившихся в литературе, и решил задачу викификации, связывая текстовые упоминания со страницами Википедии. Эта система разделяет страницы на страницы сущностей, значений или списков, используемых для присвоения категорий каждой сущности. Набор сущностей, представленных на каждой странице сущности, используется для построения контекста сущности. Последний этап связывания сущностей - это коллективное устранение неоднозначности, выполняемое путем сравнения двоичных векторов, полученных из созданных вручную функций, и из контекста каждой сущности. Система связывания сущностей Cucerzan все еще используется в качестве основы для многих недавних работ.
Работа Rao et al. это хорошо известная статья в области связывания сущностей. Авторы предлагают двухэтапный алгоритм для связывания именованных сущностей с сущностями в целевой базе знаний. Сначала выбирается набор объектов-кандидатов с использованием сопоставления строк, сокращений и известных псевдонимов. Затем лучшая ссылка среди кандидатов выбирается с помощью ранжирующей машины векторов поддержки (SVM), которая использует лингвистические особенности.
Последние системы, такие как предложенная Цаем и др., Используют вложения слов, полученные с помощью модели skip-gram в качестве языковых функций, и могут применяться к любому языку, если предоставляется большой корпус для построения встраиваемых слов. Как и в большинстве систем связывания сущностей, связывание выполняется в два этапа, с первоначальным выбором объектов-кандидатов и SVM с линейным ранжированием в качестве второго этапа.
Были опробованы различные подходы к решению проблемы неоднозначности сущностей. В оригинальном подходе Милна и Виттена контролируемое обучение используется с использованием якорных текстов объектов Википедии в качестве обучающих данных. Другие подходы также собирали данные обучения на основе однозначных синонимов. Kulkarni et al. использовали общее свойство, состоящее в том, что тематически согласованные документы относятся к сущностям, принадлежащим к сильно связанным типам.
Современные системы связывания сущностей не ограничивают свой анализ текстовыми функциями, созданными из входных документов или текстовые корпуса, но использовать большие графы знаний, созданные на основе баз знаний, таких как Википедия. Эти системы извлекают сложные функции, которые используют топологию графа знаний или многоступенчатые связи между объектами, которые могут быть скрыты простым анализом текста. Более того, создание многоязычных систем связывания на основе обработки естественного языка (NLP) по своей сути сложно, так как требует либо больших текстовых корпусов, которые часто отсутствуют для многих языков, либо созданных вручную правил грамматики, которые сильно различаются. среди языков. Han et al. предложить создание графа неоднозначности (подграф базы знаний, содержащий объекты-кандидаты). Этот график используется для чисто коллективной процедуры ранжирования, которая находит наиболее подходящую ссылку для каждого текстового упоминания.
Еще один известный подход к связыванию сущностей - AIDA, который использует серию сложных алгоритмов графа и жадный алгоритм, который идентифицирует последовательные упоминания в плотном подграфе, также учитывая сходство контекста и особенности важности вершин для выполнения коллективного устранения неоднозначности. 74>
Ранжирование графика (или ранжирование вершин) обозначает такие алгоритмы, как PageRank (PR) и поиск по темам, вызванный гиперссылками (HITS), цель которых - присвоить оценку каждая вершина, которая представляет ее относительную важность в общем графике. Система связывания сущностей, представленная в Alhelbawy et al. использует PageRank для связывания собирательных сущностей в графе устранения неоднозначности и для понимания того, какие сущности более тесно связаны друг с другом и представляют собой лучшую связь.
Математические выражения (символы и формулы) могут быть связаны с семантическими объектами (например, статьи Википедии или элементы Викиданных ), помеченные их значениями на естественном языке. Это важно для устранения неоднозначности, поскольку символы могут иметь разные значения (например, "E" может быть "энергией" или "ожидаемым значением" и т. Д.). Процесс связывания математических сущностей можно упростить и ускорить с помощью рекомендаций по аннотации, например, с помощью системы «AnnoMathTeX», размещенной на Wikimedia.