Эта статья о блочном шифре. Для использования в других целях, см
M8 (значения).
В криптографии, M8 является блочный шифр разработанный Hitachi в 1999 году Алгоритм ведет переговоры, введенных в 1997 M6, с измененной длиной ключа, который увеличенным до 64 бит или более. Этот шифр работает с сетью Фейстеля и предназначен для достижения высокой производительности на небольших устройствах или 32-битных устройствах. Например, при использовании круглого числа = 10 скорость шифрования составляет 32 Мбит / с для выделенного оборудования с 6K воротами и тактовой частотой 25 МГц или 208 Мбит / с для программы, которая использует язык C и Pentium-I 266 МГц. Из-за открытости описания его не следует использовать в открытом программном обеспечении или программном обеспечении от разных поставщиков.
СОДЕРЖАНИЕ
- 1 Структура алгоритма
- 1.1 Базовая структура
- 1.2 Структура основных функций
- 1.3 Ключевой график
- 1.4 Шифрование
- 1.5 Расшифровка
- 2 режима работы
- 3 Криптоанализ
- 4 См. Также
- 5 ссылки
Структура алгоритма
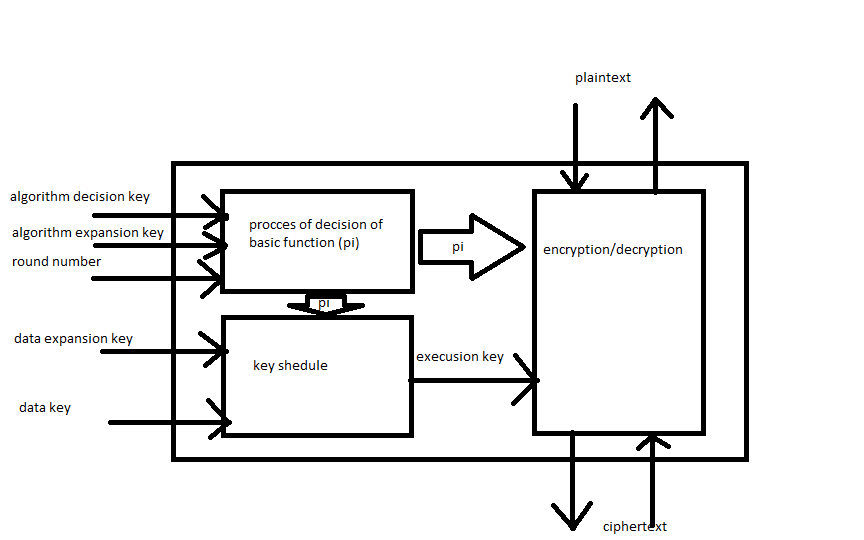
Базовая структура
Структурные характеристики заключаются в том, что шифр основан на блоке подстановки-перестановки, таком как DES. Существует 3 вида вычислений: 32-битное круговое вращение, сложение по модулю 2 32 и 32 -битное XOR. Фактическая функция может быть разной в каждом раунде. Ключ используется для вычисления с использованием его значения и определяет фактическую функцию в каждом раунде.
После процесса принятия решения, в котором используются круглые числа, ключи решения и раскрытия, алгоритм получает базовую функцию (e π) или (d π). Затем он используется либо планировщиком ключей (который также принимает ключ расширения на 256 ключей и ключ данных 64 бит), который производит ключ выполнения 256 бит и блок шифрования / дешифрования.
Ключ решения алгоритма состоит из 24 бит. Первые 9 битов определяют вычисления: 0 означает сложение по модулю 2 32, 1 означает побитовое исключающее ИЛИ. Остальные 3 блока по 5 бит определяют левое круговое вращение. Ключ раскрытия алгоритма включает 3 блока по 32 бита, которые определяют α, β и γ.
Разница между базовой функцией только в порядке перестановок: (e π) делает это в конце, (d π) - в начале блока расчета.
Структура основных функций
В структуре имеется 9 блоков вычислений и 3 необязательных блока вращения левого круга. Он имеет 64-битный размер блока, а также 64-битную длину ключа. Это шифр Фейстеля с S-блоками, которые зависят от большого ключа исполнения. Вначале есть перестановка для (d π). Затем алгоритм берет первый блок открытого текста и выполняет вычисление 1 с использованием K L, затем он (необязательно) выполняет вращение и переходит к вычислению 2. Он повторяется, но вместо K L используется α. Затем он использует β для выполнения кал. 5. Затем алгоритм делает расчеты и вращение, были описаны ранее, но с использованием K R. Далее, используется γ для вычисления calc.8, и полученный результат вычисляется с другим блоком открытого текста. В заключение алгоритм переставляет блоки. Для (e π) это то же самое, за исключением порядка перестановки и вычисления блоков.
Ключевой график
Ключ исполнения получается из 256-битного ключа расширения ключа, который делится на 2 идентичных набора из четырех 64-битных блоков K0 – K3, и 64-битного ключа данных. Каждый блок ключа расширения используется для вычисления с 32-битным ключом данных по (e Π [0-7]) и дает восемь 32-битных блоков ключа расширения на выходе.
Шифрование
Полученный ключ расширения делится на 4-х парный блок по 32 бита. Этот блок делится на 32 бита левого и правого диапазона. Он используется для вычислений с 64-битными блоками открытого текста с использованием 4 последовательных шагов. Затем полученный зашифрованный текст снова шифруется с использованием тех же пар блоков ключа раскрытия и тех же этапов цикла.
Расшифровка
Для расшифровки зашифрованного текста достаточно проделать ту же операцию, но с использованием другой базовой функции.
Режимы работы
Как определено в ISO 8372 или ISO / IEC 101116, существует 4 применимых режима:
- Режим электронной кодовой книги ( ECB )
- Самый простой режим шифрования. Использование этого открытого текста делится на блоки, которые шифруются отдельно. Недостатком метода является отсутствие диффузии. Это означает, что на сгенерированные блоки зашифрованного текста не влияют предыдущие блоки зашифрованного текста, так что связь между блоками открытого текста и их результирующими блоками зашифрованного текста плохо скрыта. Это делает этот режим работы уязвимым для атак повторного воспроизведения и атак с использованием известного открытого текста. Он считается небезопасным и не рекомендуется для использования в криптографических протоколах.
- Режим цепочки блоков шифров ( CBC )
- В этом режиме каждый блок открытого текста перед шифрованием подвергается операции XOR с предыдущим. Каждый блок будет зависеть от всех предыдущих блоков, и он должен использоваться вектор инициализации в первом блоке, чтобы сделать каждое сообщение уникальным.
- Режим Cipher Feedback ( CFB )
- Этот режим, близкий родственник CBC, превращает блочный шифр в самосинхронизирующийся потоковый шифр. Операция очень похожа; в частности, расшифровка CFB практически идентична шифрованию CBC, выполняемому в обратном порядке.
- Режим обратной связи по выходу ( OFB )
- В этом режиме блочный шифр превращается в синхронный потоковый шифр. Он генерирует блоки ключевого потока, которые затем подвергаются операции XOR с блоками открытого текста для получения зашифрованного текста. Как и в случае с другими потоковыми шифрами, изменение бита в зашифрованном тексте приводит к изменению бита в открытом тексте в том же месте. Это свойство позволяет многим кодам с исправлением ошибок нормально работать, даже если они были применены до шифрования. Из-за симметрии операции XOR шифрование и дешифрование абсолютно одинаковы.
Криптоанализ
- В клавише M8 определяются как объекты расчета, так и круглые числа. Если враждебный человек знает структуру каждого раунда, можно будет оценить M8, используя обычные методы. По оценке Hitachi, существует вероятность, что, если у него меньше 10 раундов, будет проще зашифровать M8, чем DES. Поэтому рекомендуется использоватьgt; 10 раундов. Криптографическая стойкость увеличивается по мере увеличения количества раундов, но необходимо помнить, что скорость шифрования будет уменьшаться обратно пропорционально круглым числам. Если структура раундов неизвестна, есть только способ выполнить исчерпывающий поиск, который будет неэффективен из-за огромного количества вариаций функции раунда. Таким образом, необходимо найти компромисс между скоростью и безопасностью алгоритма.
- Как и M6, он чувствителен к современному криптоанализу, который был предложен в 1999 году Джоном Келси, Брюсом Шнайером и Дэвидом Вагнером. Это форма криптоанализа с разделением, которая использует неравномерность работы шифра над классами эквивалентности (классами конгруэнтности) по модулю n. Эти атаки использовали свойства двоичного сложения и вращения битов по простому модулю Ферма. Один известный открытый текст позволяет восстановить ключ примерно с 2 35 пробными шифровками; "несколько десятков" известных открытых текстов сокращают это примерно до 2 31.
- Из-за слабого расписания ключей M8 может быть дешифрован для атаки методом « скользящего», который требует менее известного открытого текста, чем mod n криптоанализа, но меньшего количества вычислений. Предположим, что шифр имеет n бит и использует планировщик ключей, который состоит из K 1 -K M в качестве ключей любой длины. Этот метод шифрования разбивается на идентичные функции перестановки F шифра. Эта функция может состоять из более чем 1 раунда шифрования, это определяется расписанием ключей. Например, если шифр использует чередующееся расписание ключей, которое переключается между K 1 и K 2, есть 2 раунда в F. Каждый K i появится хотя бы один раз. В зависимости от характеристик шифра на следующем шаге будет собрано 2 n / 2 пар открытого текста и зашифрованного текста. По парадоксу дня рождения, не должно требоваться больше этого числа. Затем эти пары, обозначенные как, используются для поиска "скользящих" пар, которые обозначаются как. Каждая «скользящая» пара имеет свойство и. Пара «скользящая» получила свое название потому, что «скользила» по одному шифрованию. Это можно представить как результат применения однократной функции F. Как только эта пара идентифицирована, ключ может быть легко извлечен из этой пары, и шифр будет взломан из-за уязвимости к атакам с использованием известного открытого текста. Процесс поиска скользящей пары может быть разным, но выполняется по той же базовой схеме. Один использует тот факт, что относительно легко извлечь ключ из только один итерации F. Выберите любую пару пар открытый текст-зашифрованный текст и проверьте, какие ключи соответствуют и. Если эти ключи совпадают, это скользящая пара; в противном случае переходите к следующей паре. При использовании открытого текста-зашифрованного текста ожидается одна пара слайдов. Количество ложных срабатываний зависит от структуры алгоритма. Число ложных срабатываний можно уменьшить, применяя ключи к разным парам сообщение-шифрключ, потому что для хорошего шифра очень мала вероятность того, что неправильный ключ может правильно зашифроватьgt; 2 сообщений. Иногда структура шифра значительно сокращает количество необходимых пар открытый текст-зашифрованный текст и, следовательно, также требует большого объема работы. Самым наглядным из этих примеров является шифр Фейстеля, использующий расписание циклических ключей. Причина этого заключается в том, что поиск ведется по запросу. Это сокращает количество возможных парных сообщений с до (поскольку половина сообщения является фиксированной), и поэтому для поиска скользящей пары требуется самое большее количество пар открытый текст-зашифрованный текст.









Смотрите также
Рекомендации
- «Регистровая запись ISO / IEC9979-0020» (PDF). Профессор Крис Митчелл, Группа информационной безопасности, Роял Холлоуэй, Лондонский университет. ISO / IEC 9979 Регистр криптографических алгоритмов.
- «Mod n Cryptanalysis, с приложениями против RC5P и M6» (PDF). Дж. Келси, Б. Шнайер и Д. Вагнер. Быстрое шифрование программного обеспечения, Материалы шестого международного семинара (март 1999 г.), Springer-Verlag, 1999 г., стр. 139–155.
- Е. К. Гроссман и Б. Такерман (1977). «Анализ шифра типа Фейстеля, ослабленного отсутствием вращающегося ключа». Отчет об исследовании IBM Thomas J. Watson RC 6375. Цитировать журнал требует
|journal= ( помощь ) - Генри Бекер и Фред Пайпер (1982). Шифровальные системы: защита коммуникаций. Джон Вили и сыновья. С. 263–267. ISBN 0-471-89192-4. (содержит резюме статьи Гроссмана и Такермана)
- Алекс Бирюков и Давид Вагнер (март 1999 г.). Атаки на слайды ( PDF / PostScript ). 6-й Международный семинар по быстрому программному шифрованию (FSE '99). Рим : Springer-Verlag. С. 245–259. Проверено 3 сентября 2007.
- Алекс Бирюков и Давид Вагнер (май 2000 г.). Расширенные атаки на слайды (PDF / PostScript). Достижения в криптологии, Труды EUROCRYPT 2000. Брюгге : Springer-Verlag. С. 589–606. Проверено 3 сентября 2007.
- С. Фуруя (декабрь 2001 г.). Слайд-атаки с использованием криптоанализа известного открытого текста (PDF). 4-я Международная конференция по информационной безопасности и криптологии (ICISC 2001). Сеул : Springer-Verlag. С. 214–225. Архивировано из оригинального (PDF) 26 сентября 2007 года. Проверено 3 сентября 2007.
- Эли Бихам (1994). «Новые типы криптоаналитических атак с использованием связанных ключей» (PDF / PostScript). Журнал криптологии. 7 (4): 229–246. DOI : 10.1007 / bf00203965. ISSN 0933-2790. Проверено 3 сентября 2007.
- М. Сиет, Дж. Пирет, Дж. Кискватер (2002). «Атаки по связанным клавишам и слайдам: анализ, связи и улучшения» (PDF / PostScript). Проверено 4 сентября 2007. Цитировать журнал требует
|journal= ( помощь ) CS1 maint: несколько имен: список авторов ( ссылка )
