
Войти
В истории компьютерного оборудования, некоторые ранние сокращенные наборы команд компьютер центральные процессоры (ЦП RISC) использовали очень похожее архитектурное решение, теперь называемое классическим конвейером RISC . Этими процессорами были: MIPS, SPARC, Motorola 88000, а позже - условный CPU DLX, изобретенный для образовательных целей.
Каждая из этих классических скалярных RISC-схем выбирает и пытается выполнить одну инструкцию за цикл. Основной общей концепцией каждого проекта является пятиэтапный конвейер выполнения команд. Во время работы каждый этап конвейера работает по одной инструкции за раз. Каждый из этих этапов состоит из набора триггеров для удержания состояния и комбинационной логики, которая работает на выходах этих триггеров.
 Базовый пятиступенчатый конвейер в машине RISC (IF = Instruction Fetch, ID = Instruction Decode, EX = Execute, MEM = доступ к памяти, WB = обратная запись в регистр). Вертикальная ось - последовательные инструкции; горизонтальная ось - время. Таким образом, в зеленом столбце самая ранняя инструкция находится на стадии WB, а последняя инструкция выполняет выборку команды.
Базовый пятиступенчатый конвейер в машине RISC (IF = Instruction Fetch, ID = Instruction Decode, EX = Execute, MEM = доступ к памяти, WB = обратная запись в регистр). Вертикальная ось - последовательные инструкции; горизонтальная ось - время. Таким образом, в зеленом столбце самая ранняя инструкция находится на стадии WB, а последняя инструкция выполняет выборку команды. Инструкции находятся в памяти, для чтения которой требуется один цикл. Эта память может быть выделенной SRAM или кэшем инструкций Cache. Термин «задержка» часто используется в информатике и означает время от начала операции до ее завершения. Таким образом, выборка команды имеет задержку в один тактовый цикл (при использовании SRAM с одним циклом или если инструкция была в кэше). Таким образом, во время этапа выборки инструкций из памяти команд выбирается 32-битная инструкция.
Программный счетчик, или ПК, представляет собой регистр, который содержит адрес, представленный в памяти команд. В начале цикла адрес представляется в память команд. Затем во время цикла инструкция считывается из памяти инструкций, и в то же время выполняется расчет для определения следующего ПК. Расчет следующего ПК выполняется путем увеличения ПК на 4 и выбора того, следует ли использовать его в качестве следующего ПК или, альтернативно, использовать результат вычисления перехода / перехода в качестве следующего ПК. Обратите внимание, что в классическом RISC все инструкции имеют одинаковую длину. (Это то, что отделяет RISC от CISC). В исходных проектах RISC размер инструкции составляет 4 байта, поэтому всегда добавляйте 4 к адресу инструкции, но не используйте PC + 4 в случае принятого перехода, перехода или исключения (см. с задержкой филиалы, ниже). (Обратите внимание, что некоторые современные машины используют более сложные алгоритмы (прогнозирование и прогнозирование целевого перехода ), чтобы угадать адрес следующей инструкции.)
Еще одна вещь, которая отличает первые машины RISC от более ранних машин CISC, заключается в том, что RISC не имеет микрокода. В случае микрокодированных инструкций CISC, после выборки из кэша инструкций, биты инструкции сдвигаются вниз по конвейеру, где простая комбинационная логика на каждом этапе конвейера создает управляющие сигналы для канала данных непосредственно из битов инструкций. В этих проектах CISC очень мало декодирования выполняется на этапе, традиционно называемом этапом декодирования. Следствием этого отсутствия декодирования является необходимость использования большего количества битов инструкции для определения того, что делает инструкция. Это оставляет меньше битов для таких вещей, как индексы регистров.
Все инструкции MIPS, SPARC и DLX имеют не более двух входов регистров. На этапе декодирования индексы этих двух регистров идентифицируются в инструкции, и индексы представляются в регистровую память как адрес. Таким образом, два названных регистра считываются из файла регистров . В дизайне MIPS регистровый файл имел 32 записи.
В то же время, когда файл регистров читается, логика выдачи команд на этом этапе определяет, готов ли конвейер к выполнению инструкции на этом этапе. В противном случае логика проблемы приводит к остановке как этапа выборки инструкций, так и этапа декодирования. В цикле остановки входные триггеры не принимают новые биты, поэтому в течение этого цикла новые вычисления не производятся.
Если декодированная инструкция является переходом или переходом, целевой адрес перехода или перехода вычисляется параллельно с чтением файла регистров. Условие ветвления вычисляется в следующем цикле (после чтения файла регистров), и если ветвление выполняется или если инструкция является переходом, ПК на первом этапе назначается цель ветвления, а не увеличенному ПК, который был вычислен. Некоторые архитектуры использовали арифметический логический блок (ALU) на этапе выполнения за счет небольшого снижения пропускной способности команд.
На этапе декодирования потребовалось довольно много оборудования: MIPS имеет возможность ветвления, если два регистра равны, поэтому 32-битное дерево AND запускается последовательно после чтения файла регистров, создавая очень длинный критический путь через этот этап (что означает меньшее количество циклов в секунду). Кроме того, для вычисления цели перехода обычно требовалось 16-битное сложение и 14-битный инкремент. Разрешение ветвления на этапе декодирования позволило получить только штраф за неправильное предсказание ветвления за один цикл. Поскольку ветви очень часто брались (и, следовательно, предсказывались неверно), было очень важно сохранить низкий штраф.
На этапе Execute происходит фактическое вычисление. Обычно этот каскад состоит из ALU, а также битового шифтера. Он также может включать множитель и делитель нескольких циклов.
ALU отвечает за выполнение логических операций (and, or, not, nand, nor, xor, xnor), а также за выполнение целочисленного сложения и вычитания. Помимо результата, ALU обычно предоставляет биты состояния, например, был ли результат 0 или произошло ли переполнение.
Битовый сдвигатель отвечает за сдвиг и поворот.
Инструкции на этих простых RISC-машинах можно разделить на три класса задержки в зависимости от типа операции:
Если требуется доступ к памяти данных, это делается на этом этапе.
На этом этапе результаты выполнения инструкций с задержкой одного цикла просто перенаправляются на следующий этап. Такая пересылка гарантирует, что как одно-, так и двухтактные инструкции всегда записывают свои результаты на одном и том же этапе конвейера, так что можно использовать только один порт записи в файл регистров, и он всегда доступен.
Для кэширования данных с прямым отображением и виртуальных тегов используются самые простые из многочисленных организаций кэширования данных, две SRAM, одна для хранения данных, а другая для хранения теги.
На этом этапе как одиночные, так и двухцикловые инструкции записывают свои результаты в регистровый файл. Обратите внимание, что два разных этапа обращаются к регистровому файлу одновременно - этап декодирования считывает два исходных регистра, в то время как этап обратной записи записывает регистр назначения предыдущей инструкции. Для настоящего кремния это может быть опасно (подробнее об опасностях см. Ниже). Это потому, что один из исходных регистров, считываемых при декодировании, может быть таким же, как регистр назначения, записываемый при обратной записи. Когда это происходит, то одни и те же ячейки памяти в регистровом файле читаются и записываются одновременно. На кремнии многие реализации ячеек памяти не будут работать правильно при одновременном чтении и записи.
Хеннесси и Паттерсон придумали термин опасность для ситуаций, когда инструкции в конвейере приводят к неправильным ответам.
Структурные опасности возникают, когда две инструкции могут пытаться использовать одни и те же ресурсы в одно и то же время. Классические конвейеры RISC избегали этих опасностей, копируя оборудование. В частности, инструкции перехода могли использовать ALU для вычисления целевого адреса перехода. Если бы ALU использовался для этой цели на этапе декодирования, инструкция ALU, за которой следует ветвление, увидела бы, что обе инструкции попытались использовать ALU одновременно. Этот конфликт легко разрешить, сконструировав специализированный сумматор целевых переходов на этапе декодирования.
Опасности данных возникают, когда инструкция, составленная вслепую, будет пытаться использовать данные до того, как данные будут доступны в регистровом файле.
В классическом конвейере RISC опасностей данных избегают в одним из двух способов:
Обход также известен как пересылка операндов.
Предположим, ЦП выполняет следующий фрагмент кода:
SUB r3, r4 ->r10; Записывает r3 - r4 в r10 И r10, r3 ->r11; Записывает r10 и r3 в r11
Этапы выборки и декодирования инструкций отправляют вторую инструкцию на один цикл после первой. Они текут по конвейеру, как показано на этой диаграмме:

В простом конвейере, без учета опасностей, опасность данных прогрессирует следующим образом:
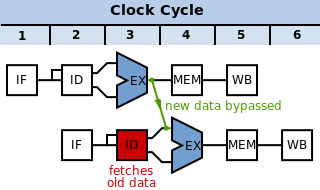
В цикле 3 инструкция SUBвычисляет новое значение для r10. В том же цикле декодируется операция И, и значение r10выбирается из файла регистров. Однако инструкция SUBеще не записала свой результат в r10. Обратная запись обычно происходит в цикле 5 (зеленая рамка). Следовательно, значение, прочитанное из регистрового файла и переданное в ALU (на этапе Execute операции AND, красный прямоугольник) неверно.
Вместо этого мы должны передать данные, которые были вычислены с помощью SUB, обратно на этап Execute (то есть в красный кружок на диаграмме) операции ANDперед обычно пишется обратно. Решение этой проблемы - пара байпасных мультиплексоров. Эти мультиплексоры находятся в конце этапа декодирования, и их выходы с флопами являются входами для ALU. Каждый мультиплексор выбирает между:
Идо тех пор, пока данные не будут готовы.Логика этапа декодирования сравнивает регистры, записанные инструкциями на этапах выполнения и доступа конвейера в регистры, считываемые инструкцией на этапе декодирования, и заставляют мультиплексоры выбирать самые последние данные. Эти обходные мультиплексоры позволяют конвейеру выполнять простые инструкции с задержкой, равной только ALU, мультиплексору и триггеру. Без мультиплексоров задержка записи, а затем чтения файла регистров должна была бы быть включена в задержку этих инструкций.
Обратите внимание, что данные могут быть переданы только вперед во времени - данные не могут быть возвращены на более ранний этап, если они еще не были обработаны. В приведенном выше случае данные передаются вперед (к тому времени, когда ANDбудет готов для регистрации в ALU, SUBуже вычислил его).
Однако следует учитывать следующие инструкции:
LD adr ->r10 AND r10, r3 ->r11
Данные, считанные с адреса adrне присутствует в кэше данных до завершения этапа доступа к памяти инструкции LD. К этому времени инструкция Иуже проходит через АЛУ. Чтобы решить эту проблему, потребовалось бы, чтобы данные из памяти были переданы назад во времени на вход ALU. Это невозможно. Решение состоит в том, чтобы задержать выполнение инструкции Ина один цикл. Опасность данных обнаруживается на этапе декодирования, а этапы выборки и декодирования застопорены - им не разрешается сбрасывать свои входные данные и поэтому они остаются в одном и том же состоянии в течение цикла. На этапах выполнения, доступа и обратной записи ниже по потоку обнаруживается дополнительная инструкция без операции (NOP), вставленная между инструкциями LDи И.
Этот NOP называется конвейером пузырем, поскольку он плавает в конвейере, как воздушный пузырь, занимая ресурсы, но не давая полезных результатов. Аппаратное обеспечение для обнаружения опасности данных и остановки конвейера до устранения опасности называется блокировкой конвейера .
| Обход назад во времени | Проблема решена с помощью пузыря |
 |  |
Блокировка конвейера не должна быть однако используется с любой пересылкой данных. Первый пример SUB, за которым следует ANDи второй пример LD, за которым следует AND, могут быть решены путем остановки первого этапа. на три цикла до тех пор, пока не будет достигнута обратная запись и данные в регистровом файлеверны, в результате чего на этапе декодирования ANDбудет выбрано правильное значение регистра. Это приводит к значительному снижению производительности, так как процессор много времени тратит на то, чтобы ничего не обрабатывать, но тактовые частоты можно увеличить, поскольку логика пересылки меньше, чем нужно ждать.
Эту опасность для данных можно довольно легко обнаружить, когда машинный код программы написан компилятором. Машина Stanford MIPS полагалась на компилятор, чтобы добавить инструкции NOP в этом случае, вместо того, чтобы иметь схему для обнаружения и (что более утомительно) остановки первых двух этапов конвейера. Отсюда и название MIPS: микропроцессор без взаимосвязанных этапов конвейера. Оказалось, что дополнительные инструкции NOP, добавленные компилятором, расширили двоичные файлы программы настолько, что снизилась частота попаданий в кэш инструкций. Аппаратное обеспечение, хотя и дорогое, было возвращено в более поздние разработки, чтобы улучшить процент попаданий в кэш команд, после чего аббревиатура перестала иметь смысл.
Опасности управления вызваны условным и безусловным переходом. Классический конвейер RISC разрешает переходы на этапе декодирования, что означает, что повторение разрешения переходов длится два цикла. Есть три следствия:
Существует четыре схемы для решения этой проблемы производительности с ветвями:
Отложенные переходы вызывали споры, во-первых, из-за сложности их семантики. Отложенная ветвь указывает, что переход в новое место происходит после следующей инструкции. Эта следующая инструкция неизбежно загружается кешем инструкций после перехода.
Отложенные переходы критиковались как плохой краткосрочный выбор в дизайне ISA:
Предположим, что 32- bit RISC обрабатывает инструкцию ADD, которая складывает два больших числа, и результат не умещается в 32 бита. Что происходит?
Самое простое решение, предоставляемое большинством архитектур, - это арифметика обертывания. У чисел, превышающих максимально возможное закодированное значение, самые старшие биты обрезаются до тех пор, пока они не подходят. В обычной системе счисления 3000000000 + 3000000000 = 6000000000. При беззнаковой 32-битной арифметике обертывания 3000000000 + 3000000000 = 1705032704 (6000000000 mod 2 ^ 32). Это может показаться не очень полезным. Самым большим преимуществом арифметики с оболочкой является то, что каждая операция дает четко определенный результат.
Но программист, особенно если он программирует на языке, поддерживающем большие целые числа (например, Lisp или Scheme ), может не