
Войти
В компьютерном хранилище, стандартные уровни RAID составляют базовый набор конфигураций RAID (избыточный массив независимых дисков), в которых используются методы чередования, зеркалирования. или четность для создания больших надежных хранилищ данных с нескольких компьютеров общего назначения жестких дисков (HDD). Наиболее распространенными типами являются RAID 0 (чередование), RAID 1 (зеркалирование) и его варианты, RAID 5 (распределенная четность) и RAID 6 (двойная четность). Уровни RAID и связанные с ними форматы данных стандартизированы Промышленной ассоциацией сетей хранения данных (SNIA) в стандарте Common RAID Disk Drive Format (DDF). Числовые значения служат только в качестве идентификаторов и не обозначают производительность, надежность, генерацию или какой-либо другой показатель.
Хотя большинство уровней RAID могут обеспечить хорошую защиту и восстановление после аппаратных дефектов или дефектных секторов / ошибок чтения (серьезных ошибок), они не обеспечивают никакой защиты от потери данных из-за катастрофических сбоев. (пожар, вода) или программные ошибки, такие как ошибка пользователя, сбой программного обеспечения или заражение вредоносным ПО. Для ценных данных RAID - это только один из строительных блоков более крупной схемы предотвращения потери данных и восстановления - он не может заменить план резервного копирования.
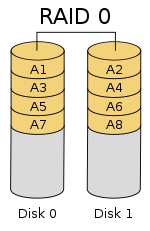 Схема настройки RAID 0
Схема настройки RAID 0 RAID 0 (также известная как полоса набор или чередующийся том) разделяет («полосы ») данные равномерно по двум или более дискам, без информации четности, избыточности или отказоустойчивости. Поскольку RAID 0 не обеспечивает отказоустойчивости или избыточности, отказ одного диска приведет к отказу всего массива; в результате чередования данных по всем дискам сбой приведет к полной потере данных. Эта конфигурация обычно реализуется с заданной скоростью. RAID 0 обычно используется для повышения производительности, хотя его также можно использовать как способ создания большого логического тома из двух или более физических дисков.
Можно настроить RAID 0. создается с дисками разного размера, но пространство для хранения, добавляемое к массиву каждым диском, ограничено размером самого маленького диска. Например, если диск на 120 ГБ чередуется с диском на 320 ГБ, размер массива будет 120 ГБ × 2 = 240 ГБ. Однако некоторые реализации RAID позволяют использовать оставшиеся 200 ГБ для других целей.
На схеме в этом разделе показано, как данные распределяются по полосам Ax на двух дисках, с A1: A2 в качестве первой полосы, A3: A4 в качестве второй и т. Д. После определения размера полосы во время создание массива RAID 0, его необходимо поддерживать постоянно. Поскольку доступ к полосам осуществляется параллельно, массив RAID 0 с n дисками выглядит как один большой диск со скоростью передачи данных, в n раз превышающей скорость одного диска.
Массив RAID 0 из n дисков обеспечивает скорость чтения и записи данных, в n раз превышающую скорость отдельных дисков, но без избыточности данных. В результате RAID 0 в основном используется в приложениях, требующих высокой производительности и допускающих более низкую надежность, например, в научных вычислениях или компьютерных играх.
Некоторые тесты настольных приложений показывают RAID 0 будет немного лучше, чем у одного диска. В другой статье были рассмотрены эти утверждения и сделан вывод о том, что «чередование не всегда увеличивает производительность (в определенных ситуациях оно фактически будет медленнее, чем настройка без RAID), но в большинстве случаев это приведет к значительному повышению производительности». Синтетические тесты показывают различные уровни повышения производительности при использовании нескольких жестких дисков или твердотельных накопителей в конфигурации RAID 0 по сравнению с производительностью одного диска. Однако некоторые синтетические тесты также показывают падение производительности для того же сравнения.
 Схема настройки RAID 1
Схема настройки RAID 1 RAID 1 состоит из точной копии (или зеркало ) набора данных на двух или более дисках; Классическая зеркальная пара RAID 1 состоит из двух дисков. Эта конфигурация не предлагает четности, чередования или распределения дискового пространства на нескольких дисках, поскольку данные зеркально отражаются на всех дисках, принадлежащих массиву, а размер массива может быть равен размеру самого маленького диска-члена. Этот макет полезен, когда производительность или надежность чтения более важны, чем производительность записи или результирующая емкость хранилища данных.
Массив будет продолжать работать, пока работает хотя бы один диск-член.
Любой запрос на чтение может обслуживаться и обрабатываться любым диском в массиве; таким образом, в зависимости от характера нагрузки ввода-вывода, производительность произвольного чтения массива RAID 1 может равняться сумме производительности каждого члена, в то время как производительность записи остается на уровне одного диска. Однако, если в массиве RAID 1 используются диски с разной скоростью, общая производительность записи равна скорости самого медленного диска.
Синтетические тесты показывают различные уровни повышения производительности при использовании нескольких жестких дисков или твердотельных накопителей. конфигурация RAID 1 по сравнению с производительностью одного диска. Однако некоторые синтетические тесты также показывают падение производительности для того же сравнения.
 Схема настройки RAID 2
Схема настройки RAID 2 RAID 2, который редко используется на практике, разбивает данные на бит (а не блочный) уровень и использует код Хэмминга для исправления ошибок. Диски синхронизируются контроллером для вращения с одинаковой угловой ориентацией (они достигают индекса одновременно), поэтому обычно он не может обслуживать несколько запросов одновременно. Однако, в зависимости от высокой скорости кода Хэмминга, многие шпиндели будут работать параллельно для одновременной передачи данных, так что возможны «очень высокие скорости передачи данных», как, например, в DataVault, где Одновременно передавалось 32 бита данных.
Поскольку на всех жестких дисках реализована внутренняя коррекция ошибок, сложность внешнего кода Хэмминга не давала большого преимущества перед контролем четности, поэтому RAID 2 применялся редко; это единственный исходный уровень RAID, который в настоящее время не используется.
 Схема настройки RAID 3 из шестибайтовых блоков и двух байтов четности, показаны два блока данных разного цвета.
Схема настройки RAID 3 из шестибайтовых блоков и двух байтов четности, показаны два блока данных разного цвета. RAID 3, который редко используется на практике, состоит из чередования уровней байтов с выделенным диском четности. Одной из характеристик RAID 3 является то, что он, как правило, не может обслуживать несколько запросов одновременно, что происходит из-за того, что любой отдельный блок данных по определению будет распределен по всем членам набора и будет находиться в одном и том же физическом месте на каждом диске. Следовательно, любая операция ввода-вывода требует активности на каждом диске и обычно требует синхронизированных шпинделей.
Это делает его подходящим для приложений, требующих максимальной скорости передачи при длительном последовательном чтении и записи, например, для редактирования несжатого видео. Приложения, выполняющие небольшие операции чтения и записи из случайных мест на диске, получат наихудшую производительность за пределами этого уровня.
Требование, чтобы все диски вращались синхронно (в шаге блокировки ), добавляло конструктивных соображений, которые обеспечивали нет существенных преимуществ перед другими уровнями RAID. И RAID 3, и RAID 4 были быстро заменены на RAID 5. RAID 3 обычно реализовывался аппаратно, и проблемы с производительностью решались за счет использования больших дисковых кешей.
 Диаграмма 1: Настройка RAID 4 с выделенными четность диск, каждый цвет которого представляет группу блоков в соответствующем блоке четность (полоса)
Диаграмма 1: Настройка RAID 4 с выделенными четность диск, каждый цвет которого представляет группу блоков в соответствующем блоке четность (полоса) RAID 4 состоит из блока -уровня чередование с выделенным диском четности. Благодаря своей структуре RAID 4 обеспечивает хорошую производительность случайного чтения, в то время как производительность случайной записи низка из-за необходимости записи всех данных четности на один диск.
На диаграмме 1 чтение запрос блока A1 будет обслуживаться диском 0. Одновременный запрос чтения для блока B1 должен ждать, но запрос чтения для B2 может одновременно обслуживаться диском 1.
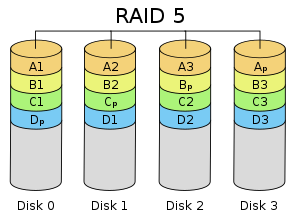 Схема RAID 5 настройка с распределенной четностью , где каждый цвет представляет группу блоков в соответствующем блоке четности (полоса). Эта диаграмма показывает левый асимметричный алгоритм
Схема RAID 5 настройка с распределенной четностью , где каждый цвет представляет группу блоков в соответствующем блоке четности (полоса). Эта диаграмма показывает левый асимметричный алгоритм RAID 5, состоящий из чередования на уровне блоков с распределенной четностью. В отличие от RAID 4, информация о четности распределяется между дисками. Для работы требуется наличие всех приводов, кроме одного. При выходе из строя одного диска последующие чтения могут быть рассчитаны на основе распределенной четности, так что данные не будут потеряны. Для RAID 5 требуется как минимум три диска.
По сравнению с RAID 4 распределенная четность в RAID 5 выравнивает нагрузку на выделенный диск четности среди всех участников RAID. Кроме того, производительность записи увеличивается, поскольку все члены RAID участвуют в обслуживании запросов на запись. Хотя это будет не так эффективно, как установка с чередованием (RAID 0), поскольку четность все еще должна быть записана, это больше не является узким местом.
Поскольку расчет четности выполняется на полном чередовании, небольшие изменения в усиление записи в массиве: в худшем случае, когда должен быть записан единственный логический сектор, необходимо прочитать исходный сектор и соответствующий сектор четности, исходные данные удаляются из четности, новые данные вычисляются в четности и записываются как новый сектор данных, так и новый сектор четности.
 Схема настройки RAID 6, которая идентична RAID 5, за исключением добавления второго блока четности
Схема настройки RAID 6, которая идентична RAID 5, за исключением добавления второго блока четности RAID 6 расширяет RAID 5, добавляя еще один четность блок; таким образом, он использует чередование уровней блоков с двумя блоками четности, распределенными по всем дискам-участникам.
Согласно Ассоциации сетей хранения данных (SNIA), определение RAID 6: «Любой форма RAID, которая может продолжать выполнять запросы чтения и записи ко всем виртуальным дискам RAID-массива при наличии любых двух одновременных сбоев дисков. Несколько методов, включая вычисления данных двойной проверки (четность и Рид-Соломон ), данные двойной ортогональной проверки на четность и диагональную четность, были использованы для реализации RAID уровня 6. "
RAID 6 не имеет потери производительности для операций чтения, но имеет снижение производительности операций записи из-за накладных расходов, связанных с вычислениями четности. Производительность сильно различается в зависимости от того, как RAID 6 реализован в архитектуре хранилища производителя - в программном обеспечении, встроенном ПО или с помощью встроенного ПО и специализированных ASIC для интенсивных вычислений четности. RAID 6 может читать с той же скоростью, что и RAID 5, с тем же количеством физических дисков.
Когда используется диагональный или ортогональный двойной контроль четности, для операций записи необходимо второе вычисление четности. Это вдвое увеличивает накладные расходы ЦП для записи RAID-6 по сравнению с уровнями RAID с одинарной четностью. Когда используется код Рида-Соломона, вычисление второй четности не требуется. Преимущество Reed Solomon заключается в том, что вся информация избыточности может содержаться в пределах заданной полосы.
Предположим, мы хотим распределить наши данные по 








Если мы используем небольшое количество фрагментов 
 где
где  обозначает оператор XOR. Второе значение четности аналогично, но с битовым сдвигом каждого блока данных на разную величину. Запись
обозначает оператор XOR. Второе значение четности аналогично, но с битовым сдвигом каждого блока данных на разную величину. Запись  , мы определяем
, мы определяем  В случае отказа одного диска данные могут быть пересчитаны из точно так же, как в случае с RAID 5. Мы покажем, что мы также можем восстановить после одновременного отказа 2 дисков. Если мы потеряем блок данных и , мы сможем восстановить а остальные данные с использованием того факта, что
В случае отказа одного диска данные могут быть пересчитаны из точно так же, как в случае с RAID 5. Мы покажем, что мы также можем восстановить после одновременного отказа 2 дисков. Если мы потеряем блок данных и , мы сможем восстановить а остальные данные с использованием того факта, что  . Предположим, что в системе из
. Предположим, что в системе из  фрагментов диск, содержащий фрагмент
фрагментов диск, содержащий фрагмент  , имеет не удалось. Мы можем вычислить
, имеет не удалось. Мы можем вычислить 
и восстановить потерянные данные 

 На поразрядном уровне это представляет систему
На поразрядном уровне это представляет систему  уравнений в неизвестных, которые однозначно определяют потерянные данные.
уравнений в неизвестных, которые однозначно определяют потерянные данные. Эта система больше не будет работать при использовании большего количества дисков 


Можно поддерживать гораздо большее количество дисков, выбрав четность действовать более осторожно. Проблема, с которой мы сталкиваемся, заключается в том, чтобы гарантировать, что система уравнений над конечным полем 


![{\ displaystyle F_ {2} [x] / (p (x))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5a94539f2b3a0114d3e0d1f244a9a4a657b0995d)



A генератор поля - это такой элемент поля, что 


Как и раньше, первая контрольная сумма 


Если один блок данных потерян, ситуация аналогична предыдущей. В случае потери двух блоков данных мы можем вычислить формулы восстановления алгебраически. Предположим, что 






Мы можем решить для 


В отличие от P, вычисление Q относительно интенсивно загружает процессор, поскольку включает в себя умножение многочленов в
В следующей таблице представлен обзор некоторых соображений для стандартных уровней RAID. В каждом случае:
| Уровень | Описание | Минимальное количество дисков | Эффективное использование пространства | Отказоустойчивость | Скорость чтения | Скорость записи |
|---|---|---|---|---|---|---|
| как фактор для одного диска | ||||||
| RAID 0 | блочный уровень чередование без четности или зеркалирование | 2 | 1 | Нет | n | n |
| RAID 1 | Зеркальное отображение без четности или чередования | 2 | 1 / n | n - 1 отказов дисков | n | 1 |
| RAID 2 | Чередование битового уровня с кодом Хэмминга для исправления ошибок | 3 | 1 - 1 / n log 2 (n + 1) | Сбой одного диска | Зависит | Зависит |
| RAID 3 | Чередование байтов с выделенной четностью | 3 | 1 - 1 / n | Отказ одного диска | n - 1 | n - 1 |
| RAID 4 | Чередование на уровне блоков с выделенной четностью | 3 | 1 - 1 / n | Отказ одного диска | n - 1 | n - 1 |
| RAID 5 | Чередование на уровне блоков с распределенной четностью | 3 | 1 - 1 / n | Отказ одного диска | n | один сектор: 1/4. заполнено stripe: n - 1 |
| RAID 6 | Чередование на уровне блоков с двойной распределенной четностью | 4 | 1-2 / n | Два сбоя диска | n | один сектор: 1/6. полная полоса: n - 2 |
При измерении производительности ввода-вывода пяти файловых систем с пятью конфигурациями хранения - один SSD, RAID 0, RAID 1, RAID 10 и RAID 5 это было показано, что F2FS на RAID 0 и RAID 5 с восемью твердотельными накопителями превосходит EXT4 в 5 и 50 раз соответственно. Измерения также показывают, что RAID-контроллер может быть значительным узким местом при создании RAID-системы с высокоскоростными твердотельными накопителями.
Комбинации двух или более стандартных уровней RAID. Они также известны как RAID 0 + 1 или RAID 01, RAID 0 + 3 или RAID 03, RAID 1 + 0 или RAID 10, RAID 5 + 0 или RAID 50, RAID 6 + 0 или RAID 60 и RAID 10 + 0. или RAID 100.
В дополнение к стандартным и вложенным уровням RAID альтернативы включают нестандартные уровни RAID и не-RAID архитектуры дисков. Архитектуры дисков без RAID обозначаются аналогичными терминами и акронимами, в частности, JBOD («просто набор дисков»), SPAN / BIG и MAID. («массив бездействующих дисков»).
.