В теории формальных языков используется лемма о накачке для обычных языков - это лемма, которая описывает существенное свойство всех регулярных языков. Неформально это говорит о том, что все достаточно длинные слова в обычном языке могут быть перекачаны, т. Е. Средняя часть слова повторяется произвольное количество раз, чтобы создать новое слово, которое также находится в том же языке.
В частности, лемма о накачке говорит, что для любого регулярного языка  существует константа
существует константа  такое, что любое слово
такое, что любое слово  в длиной не менее можно разделить на три подстроки,
в длиной не менее можно разделить на три подстроки,  , где средняя часть
, где средняя часть  не должно быть пустым, например, слова
не должно быть пустым, например, слова  , построенный путем повторения ноль или более раз все еще в . Этот процесс повторения известен как «накачивание». Кроме того, лемма о накачке гарантирует, что длина
, построенный путем повторения ноль или более раз все еще в . Этот процесс повторения известен как «накачивание». Кроме того, лемма о накачке гарантирует, что длина  будет не более , что накладывает ограничение на способы, которыми может быть разделен. Конечные языки пусто удовлетворяют лемме перекачки, имея , равную максимальной длине строки в плюс один.
будет не более , что накладывает ограничение на способы, которыми может быть разделен. Конечные языки пусто удовлетворяют лемме перекачки, имея , равную максимальной длине строки в плюс один.
Лемма о перекачке полезна для опровержения регулярности конкретного рассматриваемого языка. Впервые это было доказано Майклом Рабином и Даной Скотт в 1959 году, а вскоре вновь обнаружено Иегошуа Бар-Хиллелем, Мишей А. Перлес и Эли Шамир в 1961 году, как упрощение их леммы о перекачке для контекстно-свободных языков.
Содержание
- 1 Формальное утверждение
- 2 Использование леммы
- 3 Доказательство леммы о накачке
- 4 Общая версия леммы о накачке для регулярных языков
- 5 Обратное к лемме неверно
- 6 См. Также
- 7 Примечания
- 8 Ссылки
Формальное утверждение
Пусть будет обычным языком. Тогда существует целое число  , зависящее только от такое, что каждая строка в длиной не менее (называется «длина накачки») может быть записано как (т. Е. можно разделить на три подстроки), удовлетворяющие следующим условиям:
, зависящее только от такое, что каждая строка в длиной не менее (называется «длина накачки») может быть записано как (т. Е. можно разделить на три подстроки), удовлетворяющие следующим условиям:



- это подстрока, которую можно перекачивать (удалять или повторять любое количество раз, и результирующая строка всегда находится в ). (1) означает, что цикл , который нужно прокачивать, должен иметь длину не менее единицы; (2) означает, что цикл должен выполняться в пределах первых символов .  должен быть меньше, чем (заключение (1) и (2)), но кроме этого, есть не является ограничением для
должен быть меньше, чем (заключение (1) и (2)), но кроме этого, есть не является ограничением для  и
и  .
.
Простыми словами, для любого обычного языка , любое достаточно длинное слово (в ) можно разделить на 3 части. т.е. , так что все строки  для
для  также находятся в .
также находятся в .
Ниже приводится формальное выражение леммы о накачке.

Использование леммы
Лемма о накачке часто используется для доказательства того, что конкретный язык не является регулярным: доказательство от противоречия (регулярности языка) может состоять из отображения слова (необходимой длины) в язык, в котором отсутствует свойство, описанное в лемме о накачке.
Например, язык  по алфавиту
по алфавиту  может быть показано как нерегулярное следующим образом:
может быть показано как нерегулярное следующим образом:
Пусть  и
и  используется в формальном выражении для леммы о накачке выше. Мы предполагаем, что существует некоторая константа . Пусть в задается как
используется в формальном выражении для леммы о накачке выше. Мы предполагаем, что существует некоторая константа . Пусть в задается как  , которая является строкой длиннее, чем . По лемме о накачке должно быть некоторое разложение с и такой, что
, которая является строкой длиннее, чем . По лемме о накачке должно быть некоторое разложение с и такой, что  в для каждого
в для каждого  . Использование , мы знаем, что состоит только из экземпляров
. Использование , мы знаем, что состоит только из экземпляров  . Более того, поскольку , он содержит по крайней мере один экземпляр буквы . Теперь прокачиваем вверх:
. Более того, поскольку , он содержит по крайней мере один экземпляр буквы . Теперь прокачиваем вверх:  имеет больше экземпляров буквы , чем буква
имеет больше экземпляров буквы , чем буква  , поскольку мы добавили несколько экземпляров без добавления экземпляров . Следовательно, не находится в . Мы пришли к противоречию. Следовательно, предположение, что является регулярным (т.е. существует такой ), должно быть неверным. Следовательно, не является регулярным.
, поскольку мы добавили несколько экземпляров без добавления экземпляров . Следовательно, не находится в . Мы пришли к противоречию. Следовательно, предположение, что является регулярным (т.е. существует такой ), должно быть неверным. Следовательно, не является регулярным.
Доказательство того, что язык сбалансированных (т.е. правильно вложенных) скобок не является регулярным, следует той же идее. Для существует строка сбалансированных круглых скобок, которая начинается с более чем левых скобок, так что будет состоять полностью из левых скобок. Повторяя , мы можем создать строку, которая не содержит одинакового количества левых и правых круглых скобок, и поэтому их нельзя сбалансировать.
Доказательство леммы о накачке

Идея доказательства: всякий раз, когда достаточно длинная
строка xyz распознается
конечным автоматом, он должен достичь некоторого состояния (

) дважды. Следовательно, после повторения ("прокачки") средней части
сколь угодно часто (xyyz, xyyyz,...) слово все равно будет распознаваться.
Для каждого На регулярном языке существует конечный автомат (FSA), который принимает этот язык. Подсчитывается количество состояний в таком FSA, и этот счет используется как длина накачки . Для строки длиной не менее пусть  будет начальным состоянием и пусть
будет начальным состоянием и пусть  - последовательность следующих состояний, посещенных как строка испускается. Поскольку FSA имеет только состояний, в этой последовательности
- последовательность следующих состояний, посещенных как строка испускается. Поскольку FSA имеет только состояний, в этой последовательности  посещенных состояний должны быть по крайней мере одно состояние, которое повторяется. Напишите
посещенных состояний должны быть по крайней мере одно состояние, которое повторяется. Напишите  для такого состояния. Переходы, которые переводят машину от первой встречи состояния ко второй встрече состояния соответствует некоторой строке. Эта строка называется в лемме, и поскольку машина будет соответствовать строке без части , или если строка повторяется любое количество раз, условия леммы удовлетворяются.
для такого состояния. Переходы, которые переводят машину от первой встречи состояния ко второй встрече состояния соответствует некоторой строке. Эта строка называется в лемме, и поскольку машина будет соответствовать строке без части , или если строка повторяется любое количество раз, условия леммы удовлетворяются.
Например, на следующем изображении показан FSA.
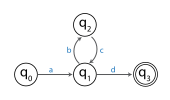
FSA принимает строку: abcd . Так как эта строка имеет длину, по меньшей мере, равную количеству состояний, которое равно четырем, принцип ячейки указывает, что должно быть по крайней мере одно повторяющееся состояние среди начального состояния и следующих четырех посещенных состояний. В этом примере только  является повторяющимся состоянием. Поскольку подстрока bc выполняет переходы, которые начинаются в состоянии и заканчиваются в состоянии , эта часть может быть повторена, и FSA все равно примет, выдав строку abcbcd . В качестве альтернативы, часть bc может быть удалена, и FSA все равно согласится предоставить строку ad . В терминах леммы о накачке строка abcd разбивается на часть a, a часть bc и часть d.
является повторяющимся состоянием. Поскольку подстрока bc выполняет переходы, которые начинаются в состоянии и заканчиваются в состоянии , эта часть может быть повторена, и FSA все равно примет, выдав строку abcbcd . В качестве альтернативы, часть bc может быть удалена, и FSA все равно согласится предоставить строку ad . В терминах леммы о накачке строка abcd разбивается на часть a, a часть bc и часть d.
Общая версия леммы о прокачке для обычных языков
Если язык является регулярным, то существует число ( длина накачки) так, чтобы каждая строка  в с | w | ≥ p можно записать в виде
в с | w | ≥ p можно записать в виде

со строками , и такие, что , и
 находится в для каждого целого числа .
находится в для каждого целого числа .
Отсюда для стандартной версии выше следует особый случай, с обоими  и
и  - пустая строка.
- пустая строка.
Поскольку общая версия предъявляет более строгие требования к языку, ее можно использовать для доказательства нерегулярности многих других языков, таких как  .
.
Обратное утверждение леммы неверно
Хотя лемма о накачке утверждает, что все регулярные языки удовлетворяют описанным выше условиям, обратное утверждение неверно: язык, который удовлетворяет этим условиям, может все же быть нерегулярным. Другими словами, как исходная, так и общая версия леммы о накачке дают необходимое, но не достаточное условие, чтобы язык был регулярным.
Например, рассмотрим следующий язык:
 .
.
Другими словами, содержит все строки в алфавите  с подстрокой длиной 3, включающей повторяющийся символ, а также все строки в этом алфавите, где ровно 1/7 символов строки - тройки. Это нестандартный язык, но его все еще можно «накачать» с помощью
с подстрокой длиной 3, включающей повторяющийся символ, а также все строки в этом алфавите, где ровно 1/7 символов строки - тройки. Это нестандартный язык, но его все еще можно «накачать» с помощью  . Предположим, что некоторая строка s имеет длину не менее 5. Тогда, поскольку в алфавите всего четыре символа, по крайней мере два из первых пяти символов в строке должны быть дубликатами. Они разделены максимум тремя символами.
. Предположим, что некоторая строка s имеет длину не менее 5. Тогда, поскольку в алфавите всего четыре символа, по крайней мере два из первых пяти символов в строке должны быть дубликатами. Они разделены максимум тремя символами.
- Если повторяющиеся символы разделены 0 или 1 символами, перекачайте один из двух других символов в строке, что не повлияет на подстроку, содержащую дубликаты.
- Если повторяющиеся символы разделены 2 или 3 символа, прокачивайте 2 символа, разделяющих их. При перекачивании вниз или вверх создается подстрока размером 3, содержащая 2 повторяющихся символа.
- Второе условие гарантирует, что не является правильным: рассмотрим строку
 . Эта строка находится в точно тогда, когда
. Эта строка находится в точно тогда, когда  и, следовательно, не является регулярным по теореме Майхилла – Нероде.
и, следовательно, не является регулярным по теореме Майхилла – Нероде.
Теорема Майхилла – Нероде предоставляет тест, который точно характеризует обычные языки. Типичный метод доказательства того, что язык является регулярным, состоит в построении либо конечного автомата, либо регулярного выражения для языка.
См. Также
Примечания
- ^Рабин, Майкл ; Скотт, Дана (апрель 1959 г.). «Конечные автоматы и проблемы их решения» (PDF). Журнал исследований и разработок IBM. 3 (2): 114–125. doi : 10.1147 / ряд.32.0114. Архивировано 14 декабря 2010 г. CS1 maint: непригодный url (ссылка ) Здесь: Лемма 8, стр.119
- ^Бар-Гилель, Ю. ; Perles, M.; Шамир, Э. (1961), «О формальных свойствах грамматик простой фразеологической структуры», Zeitschrift für Phonetik, Sprachwissenschaft und Kommunikationsforschung, 14 (2): 143–172
- ^Джон Э. Хопкрофт; Раджив Мотвани; Джеффри Д. Ульман (2003). Введение в теорию автоматов, языки и вычисления. Эддисон Уэсли. Здесь: Раздел 4.6, с.166
- ^Берстель, Жан; Лаув, Аарон; Ройтенауэр, Кристоф; Салиола, Франко В. (2009). Комбинаторика слов. Слова Кристоффеля и их повторы. Серия монографий CRM. 27 . Провиденс, Род-Айленд: Американское математическое общество. п. 86. ISBN 978-0-8218-4480-9. Zbl 1161.68043.
- ^Савич, Уолтер (1982). Абстрактные машины и грамматики. п. 49. ISBN 978-0-316-77161-0.
- ^Джон Э. Хопкрофт и Джеффри Д. Уллман (1979). Введение в теорию автоматов, языки и вычисления. Ридинг / МА: Эддисон-Уэсли. ISBN 978-0-201-02988-8.Здесь: стр. 72, упражнение 3.2 (которое дает несколько менее общую версию, требующую | w | = p) и 3.3
Ссылки
- Lawson, Mark V. (2004). Конечные автоматы. Чепмен и Холл / CRC. ISBN 978-1-58488-255-8. Zbl 1086.68074.
- Сипсер, Майкл (1997). «1.4: Нерегулярные языки». Введение в теорию вычислений. PWS Publishing. С. 77–83. ISBN 978-0-534-94728-6. Zbl 1169.68300.
- Хопкрофт, Джон Э. ; Уллман, Джеффри Д. (1979). Введение в теорию автоматов, языки и вычисления. Ридинг, Массачусетс: издательство Addison-Wesley Publishing. ISBN 978-0-201-02988-8. Zbl 0426.68001.(см. Главу 3.)
- Бахадыр Хусаинов; Анил Нероде (6 декабря 2012 г.). Теория автоматов и ее приложения. Springer Science Business Media. ISBN 978-1-4612-0171-7.

 Идея доказательства: всякий раз, когда достаточно длинная строка xyz распознается конечным автоматом, он должен достичь некоторого состояния (
Идея доказательства: всякий раз, когда достаточно длинная строка xyz распознается конечным автоматом, он должен достичь некоторого состояния (