
Войти
В теоретической информатике и теория формального языка, обычный язык (также называемый рациональным языком ) - это формальный язык, который может быть выражен с помощью регулярное выражение в строгом смысле последнего понятия, используемого в теоретической информатике (в отличие от многих механизмов регулярных выражений, предоставляемых современными языками программирования, которые дополнены функциями, позволяющими распознавать языки что не может быть выражено классическим регулярным выражением).
В качестве альтернативы, обычный язык можно определить как язык, распознаваемый конечным автоматом. Эквивалентность регулярных выражений и конечных автоматов известна как теорема Клини (в честь американского математика Стивена Коула Клини ). В иерархии Хомского регулярные языки определены как языки, которые генерируются грамматиками типа 3 (регулярные грамматики ).
Обычные языки особенно полезны при анализе ввода и языке программирования.
Набор регулярных языков в алфавите Σ определяется рекурсивно следующим образом:
См. регулярное выражение за его синтаксис и семантику. Обратите внимание, что приведенные выше случаи являются определяющими правилами регулярного выражения.
Все конечные языки регулярны; в частности, пустая строка язык {ε} = Ø * является регулярным. Другие типичные примеры включают язык, состоящий из всех строк в алфавите {a, b}, которые содержат четное число as, или язык, состоящий из всех строк формы: несколько, за которыми следуют несколько b.
Простым примером нерегулярного языка является набор строк {ab | n ≥ 0}. Интуитивно это невозможно распознать с помощью конечного автомата, поскольку конечный автомат имеет конечную память и не может запомнить точное количество а. Методы для точного доказательства этого факта приведены ниже.
Регулярный язык удовлетворяет следующим эквивалентным свойствам:
Свойства 10. и 11. представляют собой чисто алгебраические подходы к определению регулярных языков; аналогичный набор утверждений можно сформулировать для моноида M ⊆ Σ. В этом случае эквивалентность над M приводит к понятию узнаваемого языка.
Некоторые авторы используют одно из вышеперечисленных свойств, отличное от «1». как альтернативное определение обычных языков.
Некоторые из приведенных выше эквивалентностей, особенно те, что относятся к первым четырем формализмам, в учебниках называют теоремой Клини. Какой именно из них (или какое подмножество) назвать таковыми, зависит от авторов. В одном учебнике эквивалентность регулярных выражений и NFA («1» и «2» выше) называется «теоремой Клини». Другой учебник называет эквивалентность регулярных выражений и DFA («1» и «3» выше) «теоремой Клини». Два других учебника сначала доказывают выразительную эквивалентность NFA и DFA («2» и «3»), а затем заявляют «теорему Клини» как эквивалентность между регулярными выражениями и конечными автоматами (последний, как говорят, описывает «узнаваемые языки»). Лингвистически ориентированный текст сначала приравнивает обычные грамматики («4.» выше) к DFA и NFA, называет языки, генерируемые (любым из) этими «регулярными», после чего вводит регулярные выражения, которые он называет «рациональными языками», и, наконец, утверждает «теорему Клини» как совпадение регулярных и рациональных языков. Другие авторы просто определяют «рациональное выражение» и «регулярные выражения» как синонимы и делают то же самое с «рациональными языками» и «регулярными языками».
Обычные языки: закрыто при различных операциях, то есть, если языки K и L регулярны, то это результат следующих операций:
Для двух детерминированных конечных автоматов A и B разрешимо, принимают ли они один и тот же язык. Как следствие, используя вышеупомянутые свойства замыкания, следующие проблемы также разрешимы для произвольно заданных детерминированных конечных автоматов A и B с принятыми языками L A и L B, соответственно:
Для регулярных выражений проблема универсальности NP-полная уже для одноэлементного алфавита. Для более крупных алфавитов эта проблема - PSPACE-complete. Если регулярные выражения расширены, чтобы разрешить также оператор возведения в квадрат, где «A» обозначает то же самое, что и «AA», по-прежнему могут быть описаны только регулярные языки, но проблема универсальности имеет экспоненциальную нижнюю границу пространства и фактически является полной для экспоненциальной пространство относительно полиномиального сокращения.
В теории вычислительной сложности иногда упоминается класс сложности всех обычных языков как REGULAR или REG и равно DSPACE (O (1)), проблемы решения, которые могут быть решены в постоянном пространстве ( используемое пространство не зависит от размера ввода). ОБЫЧНЫЙ ≠ AC, поскольку он (тривиально) содержит проблему четности для определения того, является ли количество 1 битов на входе четным или нечетным, и этой проблемы нет в AC . С другой стороны, REGULAR не содержит AC, потому что нерегулярный язык палиндромов или нестандартный язык 
, если язык не является регулярным, для распознавания требуется машина с размером не менее Ω (log log n) (где n - размер ввода). Другими словами, DSPACE (o (log log n)) соответствует классу обычных языков. На практике большинство нерегулярных задач решаются машинами, занимающими не менее логарифмического пространства.
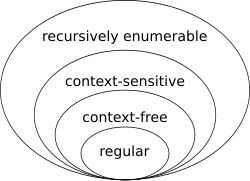 Обычный язык в классах иерархии Хомского.
Обычный язык в классах иерархии Хомского. Для размещения обычных языков в Иерархия Хомского, можно заметить, что каждый регулярный язык контекстно-свободный. Обратное неверно: например, язык, состоящий из всех строк, имеющих такое же количество букв a, что и b, является контекстно-независимым, но не регулярным. Чтобы доказать, что язык не является регулярным, часто используют теорему Майхилла – Нероде и лемму о накачке. Другие подходы включают использование закрывающих свойств обычных языков или количественное определение колмогоровской сложности.
Важные подклассы регулярных языков включают
Пусть 



Производящая функция языка L - это рациональная функция, если L регулярна. Следовательно, для каждого обычного языка 





Таким образом, нерегулярность некоторых языков 









Дзета-функция языка L равна

Дзета-функция обычного языка в общем случае не рациональна, но дзета-функция произвольного циклического языка такова.
Понятие регулярного языка было обобщено на бесконечные слова (см. ω-автоматы ) и деревья (см. древовидный автомат ).
Рациональный набор обобщает понятие (регулярного / рационального языка) на моноиды, которые не обязательно свободны. Точно так же понятие распознаваемого языка (с помощью конечного автомата) имеет тезку как распознаваемое множество над моноидом, который не обязательно является свободным. Говард Штраубинг отмечает в связи с этими фактами: «Термин« обычный язык »несколько неудачен. В статьях, на которые повлияла монография Эйленберга, часто используется термин «узнаваемый язык», который относится к поведению автоматов, или «рациональный язык», который относится к важным аналогиям между регулярными выражениями и рациональными степенными рядами. (Фактически, Эйленберг определяет рациональные и узнаваемые подмножества произвольных моноидов; эти два понятия, в общем, не совпадают.) Эта терминология, хотя и лучше мотивированная, никогда не прижилась, а «обычный язык» используется почти повсеместно ».
Рациональный ряд - еще одно обобщение, на этот раз в контексте формального степенного ряда над полукольцом. Этот подход порождает и взвешенные автоматы. В этом алгебраическом контексте регулярные языки (соответствующие логическим взвешенным рациональным выражениям) обычно называются рациональными языками. Также в этом контексте теорема Клини находит обобщение, называемое.
| journal =()