
Войти
В информатике, дерево поиска - это древовидная структура данных, используемая для поиска конкретных ключей из набора. Чтобы дерево функционировало как дерево поиска, ключ для каждого узла должен быть больше, чем любые ключи в поддеревьях слева, и меньше, чем любые ключи в поддеревьях справа.
Преимущество деревьев поиска состоит в том, что их эффективное время поиска в данном дереве достаточно сбалансировано, то есть листья на обоих концах имеют сопоставимую глубину. Существуют различные структуры данных дерева поиска, некоторые из которых также позволяют эффективно вставлять и удалять элементы, которые затем должны поддерживать баланс дерева.
Деревья поиска часто используются для реализации ассоциативного массива. Алгоритм дерева поиска использует ключ из пары «ключ-значение» для поиска местоположения, а затем приложение сохраняет всю пару «ключ-значение» в этом конкретном месте.
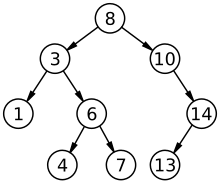 Дерево двоичного поиска
Дерево двоичного поиска Дерево двоичного поиска - это структура данных на основе узлов, где каждый узел содержит ключ и два поддерева, слева и справа. Для всех узлов ключ левого поддерева должен быть меньше ключа узла, а ключ правого поддерева должен быть больше ключа узла. Все эти поддеревья должны квалифицироваться как деревья двоичного поиска.
Наихудший случай временной сложности для поиска в двоичном дереве поиска - это высота дерева, которая может составлять всего O (log n) для дерево с n элементами.
B-деревья являются обобщением двоичных деревьев поиска в том смысле, что они могут иметь переменное количество поддеревьев в каждом узле. Хотя у дочерних узлов есть предопределенный диапазон, они не обязательно будут заполнены данными, а это означает, что B-деревья потенциально могут тратить некоторое пространство. Преимущество состоит в том, что B-деревья не нужно повторно балансировать так часто, как другие самобалансирующиеся деревья.
Из-за переменного диапазона длины их узлов B-деревья оптимизированы для систем, которые читают большие блоки. данных, они также обычно используются в базах данных.
Сложность поиска в B-дереве составляет O (log n).
(a, b) -дерево - это дерево поиска, все листья которого имеют одинаковую глубину. Каждый узел имеет не менее a потомков и не более b потомков, в то время как корень имеет не менее 2 потомков и не более b потомков.
aи b можно определить по следующей формуле:
Временная сложность поиска (a, b) -дерева составляет O (log n).
Тернарное дерево поиска - это тип дерева, которое может иметь 3 узла: малый ребенок, равный ребенок и старший ребенок. Каждый узел хранит один символ, а само дерево упорядочено так же, как и двоичное дерево поиска, за исключением возможного третьего узла.
Поиск в троичном дереве поиска включает передачу строки , чтобы проверить, содержит ли ее какой-либо путь.
Временная сложность поиска сбалансированного троичного дерева поиска составляет O (log n).
Предполагая, что дерево упорядочено, мы можем взять ключ и попытаться найти его в дереве. Следующие алгоритмы обобщены для деревьев двоичного поиска, но ту же идею можно применить к деревьям других форматов.
поисково-рекурсивный (ключ, узел), если узел имеет значение NULL вернуть EMPTY_TREE, если ключ <узел. ключ return search-recursive (key, node.left) else if key>node.key return search-recursive (key, node.right) elsereturn узел
searchIterative (ключ, узел) currentNode: = node, в то время как currentNode не равен NULL, если currentNode.key = key return currentNode else if currentNode.key>key currentNode: = currentNode.left else currentNode: = currentNode.right
В отсортированном дереве минимум находится в крайнем левом узле, а максимум - в крайнем правом узле.
findMinimum (node) если узел имеет значение NULL return EMPTY_TREE min: = node, а min.left не равно NULL min: = min.left return min.key
findMaximum (node), если node имеет значение NULL return EMPTY_TREE max: = node в то время как max.right не NULL max: = max.right return max.key
