
Войти
В вычислениях, постоянная структура данных представляет собой структуру данных , которая всегда сохраняет предыдущую версию самой себя при ее изменении. Такие структуры данных по сути являются неизменяемыми, поскольку их операции (визуально) не обновляют структуру на месте, а вместо этого всегда создают новую обновленную структуру. Этот термин был введен в статье Дрисколла, Сарнака, Слеатора и Тарджанса в 1986 г.
Структура данных частично постоянная, если доступны все версии, но можно изменять только самую новую версию. Структура данных полностью постоянная, если каждая версия может быть доступна и изменена. Если также существует операция слияния или слияния, которая может создать новую версию из двух предыдущих версий, структура данных называется непрерывно постоянная . Структуры, которые не являются постоянными, называются эфемерными.
Эти типы структур данных особенно распространены в логическом и функциональном программировании, поскольку языки в этих парадигмах препятствуют (или полностью запретить) использование изменяемых данных.
В модели частичной сохраняемости программист может запросить любую предыдущую версию структуры данных, но может обновлять только последнюю версию. Это подразумевает линейный порядок среди каждой версии структуры данных. В полностью персистентной модели и обновления, и запросы разрешены для любой версии структуры данных. В некоторых случаях характеристики производительности запросов или обновления более старых версий структуры данных могут ухудшаться, как это верно для структуры данных веревки. Кроме того, структура данных может называться конфлюентно-постоянной, если, помимо того, что она полностью постоянна, две версии одной и той же структуры данных могут быть объединены для формирования новой версии, которая остается полностью постоянной.
Одним из методов создания постоянной структуры данных является использование предоставленной платформой эфемерной структуры данных, такой как массив для хранения данные в структуре данных и скопируйте всю эту структуру данных, используя семантику копирования при записи для любых обновлений структуры данных. Это неэффективный метод, потому что вся структура данных резервного копирования должна копироваться для каждой записи, что приводит к худшим характеристикам производительности O (n · m) для m модификаций массива размера n.
Метод толстого узла состоит в том, чтобы записывать все изменения, внесенные в поля узла в самих узлах, без удаления старых значений полей. Для этого требуется, чтобы узлы были произвольно «толстыми». Другими словами, каждый толстый узел содержит ту же информацию и поля указателя , что и эфемерный узел, а также пространство для произвольного количества дополнительных значений поля. Каждое дополнительное значение поля имеет связанное имя поля и отметку версии, которая указывает версию, в которой указанное поле было изменено, чтобы иметь указанное значение. Кроме того, каждый толстый узел имеет свой штамп версии, указывающий версию, в которой узел был создан. Единственная цель узлов, имеющих отметки версии, - убедиться, что каждый узел содержит только одно значение на имя поля для каждой версии. Для навигации по структуре каждое исходное значение поля в узле имеет отметку версии, равную нулю.
При использовании метода толстого узла требуется O (1) места для каждой модификации: просто сохраните новые данные. Каждая модификация занимает O (1) дополнительного времени для сохранения модификации в конце истории модификаций. Это ограничение амортизированного времени при условии, что история изменений хранится в растущем массиве . При времени доступа правильная версия на каждом узле должна быть найдена по мере прохождения структуры. Если бы необходимо было произвести "m" модификаций, то каждая операция доступа имела бы замедление на O (log m) в результате затрат на поиск ближайшей модификации в массиве.
При использовании метода копирования пути копируются все узлы на пути к любому узлу, который должен быть изменен. Эти изменения затем должны быть каскадно возвращены через структуру данных: все узлы, указывающие на старый узел, должны быть изменены, чтобы вместо этого указывать на новый узел. Эти модификации вызывают новые каскадные изменения и так далее, пока не будет достигнут корневой узел.
При m модификациях это стоит O (log m) дополнительного времени поиска. Время и пространство модификации ограничены размером самого длинного пути в структуре данных и стоимостью обновления в эфемерной структуре данных. В сбалансированном двоичном дереве поиска без родительских указателей сложность времени модификации наихудшего случая равна O (log n + стоимость обновления). Однако в связанном списке сложность времени модификации наихудшего случая составляет O (n + стоимость обновления).
Sleator, Tarjan et al. придумал способ объединить методы толстых узлов и копирования пути, достигая O (1) замедления доступа и O (1) пространственной и временной сложности модификации.
В каждом узле хранится одно поле модификации. Это поле может содержать одну модификацию узла - либо модификацию одного из указателей, либо ключа узла, либо некоторой другой части специфичных для узла данных - и отметку времени, когда была применена эта модификация. Изначально поле модификации каждого узла пусто.
Каждый раз, когда к узлу обращаются, поле модификации проверяется, и его временная метка сравнивается со временем доступа. (Время доступа определяет версию рассматриваемой структуры данных.) Если поле модификации пусто или время доступа предшествует времени модификации, то поле модификации игнорируется и рассматривается только нормальная часть узла. С другой стороны, если время доступа превышает время модификации, тогда используется значение в поле модификации, переопределяя это значение в узле.
Изменение узла работает следующим образом. (Предполагается, что каждая модификация касается одного указателя или подобного поля.) Если поле модификации узла пусто, то оно заполняется модификацией. В противном случае поле модификации заполнено. Создается копия узла, но с использованием только последних значений. Модификация выполняется непосредственно на новом узле, без использования окна модификации. (Одно из полей нового узла перезаписывается, а поле его модификации остается пустым.) Наконец, это изменение каскадно передается родительскому узлу, точно так же, как копирование пути. (Это может включать в себя заполнение поля модификации родителя или рекурсивное создание копии родителя. Если у узла нет родителя - это корень, он добавляет новый корень в отсортированный массив корней.)
В этом алгоритме, в любой момент времени t, в структуре данных существует не более одного блока модификации со временем t. Таким образом, модификация во время t разбивает дерево на три части: одна часть содержит данные до момента t, другая часть содержит данные после времени t, а одна часть не была затронута модификацией.
Время и место для модификаций требуют амортизированного анализа. Для модификации требуется O (1) амортизированного пространства и O (1) амортизированного времени. Чтобы понять, почему, используйте потенциальную функцию ϕ, где ϕ (T) - количество полных активных узлов в T. Активные узлы T - это просто узлы, доступные из текущего корня в текущее время (то есть после последней модификации). Полные активные узлы - это активные узлы, чьи поля модификации заполнены.
Каждая модификация включает в себя некоторое количество копий, скажем k, за которым следует одно изменение в поле модификации. Рассмотрим каждую из k копий. Каждый требует O (1) пространства и времени, но уменьшает потенциальную функцию на единицу. (Во-первых, копируемый узел должен быть полным и активным, чтобы он вносил свой вклад в потенциальную функцию. Однако потенциальная функция будет отключена только в том случае, если старый узел недоступен в новом дереве. Но известно, что он недоступен в новом дереве - следующим шагом в алгоритме будет изменение родительского узла, чтобы он указывал на копию. Наконец, известно, что поле модификации копии пусто. Таким образом, заменен полный рабочий узел заменяется пустым живым узлом, и ϕ уменьшается на единицу.) Последний шаг заполняет поле модификации, которое стоит O (1) времени и увеличивает ϕ на единицу.
Собирая все вместе, изменение ϕ равно Δϕ = 1− k. Таким образом, алгоритм занимает O (k + Δϕ) = O (1) пространства и O (k + Δϕ +1) = O (1) раз
Возможно Простейшая постоянная структура данных - это односвязный список или список на основе cons, простой список объектов, каждый из которых несет ссылку на следующий в списке. Это постоянно, потому что можно взять конец списка, то есть последние k элементов для некоторых k, и перед ним могут быть добавлены новые узлы. Хвост не будет дублироваться, вместо этого он станет общим для старого и нового списков. Пока содержимое хвоста неизменяемо, это совместное использование будет невидимым для программы.
Многие распространенные структуры данных на основе ссылок, такие как красно-черные деревья, стеки и трепы, можно легко адаптировать для создания постоянная версия. Некоторым другим требуется немного больше усилий, например: queues, dequeues и расширения, включая (которые имеют дополнительную операцию O (1) min, возвращающую минимальный элемент) и (которые имеют дополнительная операция произвольного доступа с сублинейной, чаще всего логарифмической, сложностью).
Существуют также постоянные структуры данных, которые используют деструктивные операции, что делает невозможным их эффективную реализацию на чисто функциональных языках (например, Haskell вне специализированных монад, таких как состояние или ввод-вывод), но возможно на таких языках, как C или Java. Этих типов структур данных часто можно избежать с помощью другого дизайна. Одним из основных преимуществ использования чисто постоянных структур данных является то, что они часто лучше работают в многопоточных средах.
Односвязные связанные списки представляют собой простую структуру данных в функциональных языках. Некоторые языки, производные от ML, такие как Haskell, являются чисто функциональными, потому что после того, как узел в списке был выделен, его нельзя изменить, только скопировать, указать или уничтожить сборщик мусора, когда к нему ничего не относится. (Обратите внимание, что сам ML не является чисто функциональным, но поддерживает подмножество неразрушающих операций со списком, что также верно в диалектах функционального языка Lisp (LISt Processing), таких как Scheme и Racket.)
Рассмотрим два списка:
xs = [0, 1, 2] ys = [3, 4, 5]
Они будут представлены в памяти следующим образом:
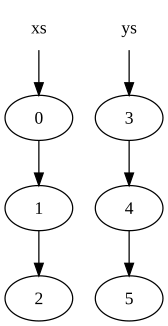
где кружок указывает узел в списке (стрелка вниз представляет второй элемент узла, который является указателем на другой узел).
Теперь объединение двух списков:
zs = xs ++ ys
приводит к следующей структуре памяти:

Обратите внимание, что узлы в списке xsбыли скопированы, но узлы в ysявляются общими. В результате исходные списки (xsи ys) сохраняются и не были изменены.
Причина копирования заключается в том, что последний узел в xs(узел, содержащий исходное значение 2) не может быть изменен так, чтобы указывать на начало ys, потому что это изменит значение xs.
. Рассмотрим двоичное дерево поиска, где каждый узел в дереве имеет рекурсивный инвариант, что все подузлы, содержащиеся в левом поддереве, имеют значение, которое меньше или равно значению, хранящемуся в узле, а подузлы, содержащиеся в правом поддереве, имеют значение, большее, чем значение, сохраненное в узел.
Например, набор данных
xs = [a, b, c, d, f, g, h]
может быть представлен следующим двоичным поиском tree:
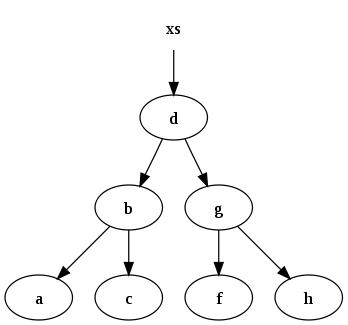
Функция, которая вставляет данные в двоичное дерево и поддерживает инвариант:
fun insert (x, E) = T (E, x, E) | insert (x, s as T (a, y, b)) = if x < y then T (insert (x, a), y, b) else if x>y then T (a, y, insert (x, b)) else s
После выполнения
ys = insert ("e", xs)Создается следующая конфигурация:
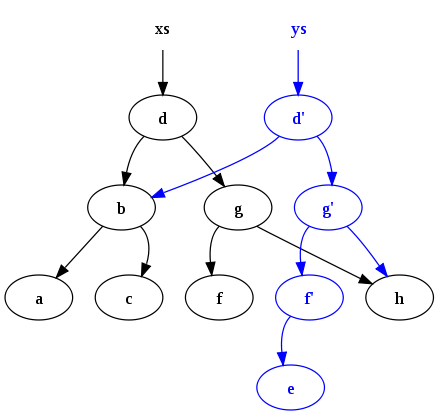
Обратите внимание на два момента: во-первых, исходное дерево (xs) сохраняется. Во-вторых, старое и новое дерево используют общие узлы. Таким постоянством и совместным использованием трудно управлять без какой-либо формы сборки мусора (GC) для автоматического освобождения узлов, которые не имеют живых ссылок, и поэтому GC - это функция, обычно встречающаяся в функциональном программировании. languages .
Отображенное дерево постоянного хеш-массива - это специализированный вариант сопоставленного массива хешей, который будет сохранять предыдущие версии самого себя при любых обновлениях. Он часто используется для реализации постоянной структуры данных карты общего назначения.
Попытки сопоставления хэш-массива были первоначально описаны в статье 2001 года под названием «Идеальные хеш-деревья». В этом документе представлена изменяемая хеш-таблица, где «время вставки, поиска и удаления небольшое и постоянное, независимо от размера набора ключей, операции - O (1). Небольшое время наихудшего случая для вставки, поиска и удаления операции могут быть гарантированы, и промахи обходятся дешевле, чем успешные поиски ». Затем эта структура данных была изменена Ричем Хикки, чтобы она стала полностью постоянной для использования в языке программирования Clojure.
Концептуально попытки сопоставления хэш-массива работают аналогично любым общим tree в том, что они хранят узлы иерархически и извлекают их, следуя пути вниз к конкретному элементу. Ключевое отличие состоит в том, что попытки сопоставления хэш-массива сначала используют хэш-функцию для преобразования своего ключа поиска в целое (обычно 32- или 64-разрядное). Затем определяется путь вниз по дереву с использованием срезов двоичного представления этого целого числа для индексации в разреженный массив на каждом уровне дерева. Листовые узлы дерева ведут себя аналогично сегментам, используемым для создания хэш-таблиц, и могут содержать или не содержать нескольких кандидатов в зависимости от коллизий хешей.
Большинство реализаций сопоставленных попыток постоянного хеш-массива используют коэффициент ветвления 32 в их реализации. Это означает, что на практике, хотя вставки, удаления и поиск в постоянном массиве хеш-массива, отображенном в дереве, имеют вычислительную сложность O (log n), для большинства приложений они фактически являются постоянным временем, поскольку для этого потребуется чрезвычайно большое количество записей. сделать любую операцию более десятка шагов.
Haskell - это чистый функциональный язык и, следовательно, не позволяет для мутации. Следовательно, все структуры данных на языке являются постоянными, поскольку невозможно не сохранить предыдущее состояние структуры данных с функциональной семантикой. Это связано с тем, что любое изменение в структуре данных, которое сделало бы предыдущие версии структуры данных недействительными, нарушило бы ссылочную прозрачность.
В своей стандартной библиотеке Haskell имеет эффективные постоянные реализации для связанных списков, карт (реализованных как деревья со сбалансированным размером), и Sets среди других.
Как и многие языки программирования в семействе Lisp, Clojure содержит реализацию связанного списка, но в отличие от других диалектов, его реализация Связанный список обеспечивает постоянство вместо того, чтобы быть постоянным по соглашению. Clojure также имеет синтаксические литералы для эффективных реализаций постоянных векторов, карт и наборов, основанных на попытках сопоставления постоянного хэш-массива. Эти структуры данных реализуют обязательные доступные только для чтения части среды коллекций Java.
Разработчики языка Clojure рекомендуют использовать постоянные структуры данных вместо изменяемых структур данных, потому что они имеют семантику значений, которая дает возможность свободно обмениваться ими между потоками с дешевыми псевдонимами, простыми в изготовлении и независимыми от языка.
Эти структуры данных составляют основу поддержки Clojure параллельных вычислений, поскольку они позволяют простые попытки выполнения операций для обхода гонки данных и атомарного сравнения и замены семантики.
Язык программирования Elm является чисто функциональным, как Haskell, что делает все его структуры данных постоянными по необходимости. Он содержит постоянные реализации связанных списков, а также постоянные массивы, словари и наборы.
Elm использует настраиваемую реализацию виртуального DOM, которая использует преимущества постоянного характера данных Elm. По состоянию на 2016 год разработчики Elm сообщили, что этот виртуальный DOM позволяет языку Elm отображать HTML быстрее, чем популярные JavaScript фреймворки React, Ember, и Angular.
Популярная среда внешнего интерфейса JavaScript React часто используется вместе с системой управления состоянием, которая реализует, популярной реализацией которой является библиотека JavaScript Redux. Библиотека Redux основана на шаблоне управления состоянием, используемом в языке программирования Elm, что означает, что она требует, чтобы пользователи обрабатывали все данные как постоянные. В результате проект Redux рекомендует, чтобы в определенных случаях пользователи использовали библиотеки для принудительных и эффективных постоянных структур данных. Сообщается, что это обеспечивает более высокую производительность, чем при сравнении или создании копий обычных объектов JavaScript.
Одна из таких библиотек постоянных структур данных Immutable.js основана на структурах данных, сделанных доступными и популяризованными Clojure и Scala. В документации Redux он упоминается как одна из возможных библиотек, которые могут обеспечить принудительную неизменяемость.
Язык программирования Scala способствует использованию постоянных структур данных для реализации программ с использованием " Объектно-функциональный стиль ». Scala содержит реализации многих постоянных структур данных, включая связанные списки, красно-черные деревья, а также попытки сопоставления постоянного хеш-массива, представленные в Clojure.
Поскольку постоянные структуры данных часто реализуются таким образом, что последовательные версии структуры данных совместно используют базовую память, эргономичное использование таких структур данных обычно требует некоторой формы автоматической системы сбора мусора, такой как подсчет ссылок или отметьте и проведите пальцем по. На некоторых платформах, где используются постоянные структуры данных, можно не использовать сборку мусора, что, хотя и может привести к утечкам памяти, в некоторых случаях может положительно повлиять на общую производительность приложения..
.