Конструкция Неймана - это частотный метод для построения интервала с уровнем достоверности  таким образом, что если мы повторим эксперимент много раз, интервал будет содержать истинное значение некоторого параметра в дробной части
таким образом, что если мы повторим эксперимент много раз, интервал будет содержать истинное значение некоторого параметра в дробной части  времени. Он назван в честь Ежи Неймана.
времени. Он назван в честь Ежи Неймана.
Содержание
- 1 Теория
- 2 Вероятность покрытия
- 3 Реализация
- 4 Классический пример
- 5 Другой пример
- 6 См. Также
- 7 Ссылки
Теория
Предположим  - случайные величины с объединенным pdf
- случайные величины с объединенным pdf  , который зависит от k неизвестных параметров. Для удобства пусть
, который зависит от k неизвестных параметров. Для удобства пусть  будет пространством выборки, определяемым n случайными величинами, и затем определим точку выборки в пространстве выборки как
будет пространством выборки, определяемым n случайными величинами, и затем определим точку выборки в пространстве выборки как  . Нейман первоначально предложил определить две функции
. Нейман первоначально предложил определить две функции  и
и  так, что для любой точки выборки
так, что для любой точки выборки  ,
,


- L и U однозначны и определены.
Учитывая наблюдение,  , вероятность того, что
, вероятность того, что  находится между
находится между  и
и  определяется как
определяется как  с вероятностью Только
с вероятностью Только  или
или  . Эти вычисленные вероятности не позволяют сделать значимый вывод о , поскольку вероятность равна нулю или единице. Кроме того, в соответствии с частотной конструкцией параметры модели являются неизвестными константами и не могут быть случайными величинами. Например, если
. Эти вычисленные вероятности не позволяют сделать значимый вывод о , поскольку вероятность равна нулю или единице. Кроме того, в соответствии с частотной конструкцией параметры модели являются неизвестными константами и не могут быть случайными величинами. Например, если  , то
, то  . Аналогично, если
. Аналогично, если  , то
, то 
Как описывает Нейман в своей статье 1937 года, предположим, что мы рассматриваем все точки в пространстве выборки, то есть , которые представляют собой систему случайных величин, определяемую объединенным PDF-файлом, описанным выше. Поскольку  и
и  являются функциями они тоже являются случайными величинами, и можно исследовать значение следующего утверждения вероятности:.
являются функциями они тоже являются случайными величинами, и можно исследовать значение следующего утверждения вероятности:.
- В рамках частотной конструкции параметры модели являются неизвестными константами и не могут быть случайными величинами. Рассматривая все точки выборки в пространстве выборки как случайные величины, определенные вышеупомянутым объединенным PDF-файлом, то есть все
 можно показать, что и являются функциями случайных величин и, следовательно, случайных величин. Следовательно, можно посмотреть на вероятность
можно показать, что и являются функциями случайных величин и, следовательно, случайных величин. Следовательно, можно посмотреть на вероятность  и
и  для некоторых . Если
для некоторых . Если  - истинное значение , мы можем определить и так, чтобы вероятность
- истинное значение , мы можем определить и так, чтобы вероятность  и
и  равно предварительно заданному уровню достоверности
равно предварительно заданному уровню достоверности  .
.
То есть  где
где  где и верхний и нижний доверительные границы для
где и верхний и нижний доверительные границы для
Вероятность охвата
Вероятность охвата,  , для конструкции Неймана - частота расчетов Предполагается, что доверительный интервал содержит фактическое интересующее значение. Обычно вероятность охвата устанавливается равной
, для конструкции Неймана - частота расчетов Предполагается, что доверительный интервал содержит фактическое интересующее значение. Обычно вероятность охвата устанавливается равной  достоверности. Для построения Неймана вероятность покрытия устанавливается равной некоторому значению , где
достоверности. Для построения Неймана вероятность покрытия устанавливается равной некоторому значению , где
Реализация
Конструкция Неймана может быть выполнена путем выполнения нескольких экспериментов, которые создают наборы данных, соответствующие заданному значению параметра. Эксперименты проводятся с использованием традиционных методов, а пространство подобранных значений параметров составляет полосу, из которой может быть выбран доверительный интервал.
Классический пример
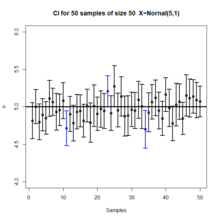
График 50 доверительных интервалов из 50 выборок, созданных из нормального распределения.
Предположим, ~ , где
, где  и
и  - неизвестные константы, для которых мы хотим оценить . Мы можем определить (2) функции с одним значением, и , которые определены описанным выше процессом, так что заранее заданный уровень достоверности и случайная выборка
- неизвестные константы, для которых мы хотим оценить . Мы можем определить (2) функции с одним значением, и , которые определены описанным выше процессом, так что заранее заданный уровень достоверности и случайная выборка  =(
=( )
)


- где
 ,
, 
- и
 следует в распределении с (n-1) степенями свободы. ~t
следует в распределении с (n-1) степенями свободы. ~t
Другой пример
 - случайные переменные iid, и пусть
- случайные переменные iid, и пусть  . Предположим,
. Предположим,  . Теперь построим доверительный интервал с уровнем достоверности . Мы знаем, что
. Теперь построим доверительный интервал с уровнем достоверности . Мы знаем, что  достаточно для
достаточно для  . Итак,
. Итак,



Это дает  доверительный интервал для где,
доверительный интервал для где,

 .
.
См. Также
Ссылки

 График 50 доверительных интервалов из 50 выборок, созданных из нормального распределения.
График 50 доверительных интервалов из 50 выборок, созданных из нормального распределения.