
Войти
 | |
| Автор (ы) | |
|---|---|
| Разработчик (и) | Apache Software Foundation |
| Первый выпуск | Январь 2011 г.; 9 лет назад (2011-01) |
| Стабильный выпуск | 2.6.0 / 3 августа 2020 г.; 2 месяца назад (2020-08-03) |
| Репозиторий | |
| Написано на | Scala, Java |
| Операционная система | Межплатформенность |
| Тип | Потоковая обработка, Брокер сообщений |
| Лицензия | Лицензия Apache 2.0 |
| Веб-сайт | kafka.apache.org |
Apache Kafka - это программная платформа с открытым исходным кодом потоковая обработка, разработанная Apache Software Foundation, написано на Scala и Java. Проект направлен на создание унифицированной платформы с высокой пропускной способностью и малой задержкой для обработки потоков данных в реальном времени. Kafka может подключаться к внешним системам (для импорта / экспорта данных) через Kafka Connect и предоставляет Kafka Streams, библиотеку обработки потоков Java. Kafka использует бинарный протокол на основе TCP, который оптимизирован для повышения эффективности и опирается на абстракцию «набор сообщений», которая естественным образом группирует сообщения вместе, чтобы уменьшить накладные расходы на передачу данных по сети. Это «приводит к большим сетевым пакетам, большим последовательным операциям с диском, непрерывным блокам памяти [...], что позволяет Kafka преобразовывать импульсный поток случайных записей сообщений в линейные записи».
Первоначально Kafka был разработан LinkedIn, а затем был открыт в начале 2011 года. Выход из Apache Incubator произошел 23 октября 2012. Джей Крепс назвал программу в честь автора Франца Кафки, потому что это «система, оптимизированная для письма», и ему понравилась работа Кафки.
Apache Kafka основан на журнале фиксации и позволяет пользователям подписываться на него и публиковать данные в любом количестве систем или приложений реального времени. Примеры приложений включают управление подбором пассажиров и водителей в Uber, предоставление аналитики в реальном времени и профилактическое обслуживание для умного дома British Gas, а также выполнение множества задач в режиме реального времени. сервисы во всем LinkedIn.
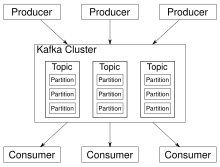 Обзор Kafka
Обзор Kafka Kafka хранит сообщения типа "ключ-значение", которые поступают из произвольно большого числа процессов, называемых производителями. Данные можно разделить на разные «разделы» в разных «темах». Внутри раздела сообщения строго упорядочены по смещению (позиции сообщения в разделе), индексируются и сохраняются вместе с отметкой времени. Другие процессы, называемые «потребителями», могут читать сообщения из разделов. Для потоковой обработки Kafka предлагает Streams API, который позволяет писать приложения Java, которые потребляют данные из Kafka и записывают результаты обратно в Kafka. Apache Kafka также работает с внешними системами обработки потоков, такими как Apache Apex, Apache Flink, Apache Spark, Apache Storm и . Apache NiFi.
Kafka работает в кластере из одного или нескольких серверов (называемых брокерами), и разделы всех тем распределены по узлам кластера. Кроме того, разделы реплицируются на нескольких брокеров. Эта архитектура позволяет Kafka доставлять массивные потоки сообщений отказоустойчивым способом и позволила ему заменить некоторые традиционные системы обмена сообщениями, такие как Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP) и т. Д. Начиная с выпуска 0.11.0.0, Kafka предлагает транзакционные записи, которые обеспечивают однократную потоковую обработку с использованием Streams API.
Kafka поддерживает два типа тем: обычные и сжатые. Обычные темы можно настроить с указанием времени хранения или ограничения пространства. Если есть записи, которые старше указанного времени хранения или если для раздела превышено ограничение на пространство, Kafka может удалить старые данные, чтобы освободить место для хранения. По умолчанию темы настроены со сроком хранения 7 дней, но также можно хранить данные неограниченное время. Для сжатых тем записи не истекают из-за ограничений по времени или пространству. Вместо этого Kafka рассматривает более поздние сообщения как обновления более старого сообщения с тем же ключом и гарантирует, что никогда не удалит последнее сообщение для каждого ключа. Пользователи могут полностью удалить сообщения, написав так называемое сообщение-захоронение с нулевым значением для определенного ключа.
В Kafka есть пять основных API:
API-интерфейсы потребителя и производителя основаны на протоколе обмена сообщениями Kafka и предлагают эталонную реализацию для клиентов-потребителей и производителей Kafka в Java. Базовый протокол обмена сообщениями - это двоичный протокол, который разработчики могут использовать для написания своих собственных клиентов-потребителей или производителей на любом языке программирования. Это разблокирует Kafka из экосистемы виртуальной машины Java (JVM). Список доступных клиентов, отличных от Java, содержится в вики-странице Apache Kafka.
Kafka Connect (или Connect API) - это платформа для импорта / экспорта данных из / в другие системы. Он был добавлен в выпуск Kafka 0.9.0.0 и внутренне использует API-интерфейс производителя и потребителя. Сама платформа Connect выполняет так называемые «коннекторы», реализующие фактическую логику для чтения / записи данных из других систем. API Connect определяет программный интерфейс, который необходимо реализовать для создания настраиваемого коннектора. Уже доступно множество коннекторов с открытым исходным кодом и коммерческих соединителей для популярных систем данных. Однако сам Apache Kafka не включает готовые соединители.
Kafka Streams (или Streams API) - это библиотека потоковой обработки, написанная на Java. Он был добавлен в выпуске Kafka 0.10.0.0. Библиотека позволяет разрабатывать приложения для потоковой обработки с отслеживанием состояния, которые являются масштабируемыми, эластичными и полностью отказоустойчивыми. Основным API является потоковая обработка предметно-ориентированного языка (DSL), который предлагает высокоуровневые операторы, такие как фильтр, карта, группировка, управление окнами, агрегация, объединения и понятие таблицы. Кроме того, API процессора можно использовать для реализации пользовательских операторов для более низкоуровневого подхода к разработке. DSL и Processor API также могут быть смешаны. Для обработки потока с отслеживанием состояния Kafka Streams использует RocksDB для поддержания состояния локального оператора. Поскольку RocksDB может записывать данные на диск, поддерживаемое состояние может быть больше доступной основной памяти. Для обеспечения отказоустойчивости все обновления локальных хранилищ состояний также записываются в тему кластера Kafka. Это позволяет воссоздать состояние, прочитав эти темы и загрузив все данные в RocksDB.
До версии 0.9.x брокеры Kafka обратно совместимы только со старыми клиентами. Начиная с Kafka 0.10.0.0, брокеры также совместимы с новыми клиентами. Если новый клиент подключается к более старому брокеру, он может использовать только те функции, которые поддерживает брокер. Для Streams API полная совместимость начинается с версии 0.10.1.0: приложение Kafka Streams 0.10.1.0 несовместимо с брокерами 0.10.0 или более ранней версии.
Мониторинг сквозной производительности требует отслеживания показателей от брокеров, потребителей и производителей в дополнение к мониторингу ZooKeeper, который Kafka использует для координации между потребителями.. В настоящее время существует несколько платформ мониторинга для отслеживания производительности Kafka: либо с открытым исходным кодом, как LinkedIn, Burrow, либо платными, как Datadog и Deep.BI. В дополнение к этим платформам сбор данных Kafka также может выполняться с помощью инструментов, обычно поставляемых с Java, включая JConsole.