
Войти
Дерево альтернативных решений (ADTree) - это метод машинного обучения для классификации. Он обобщает деревья решений и имеет связи с повышением.
. ADTree состоит из чередования узлов решений, которые задают условие предиката, и узлов прогнозирования, которые содержат одно число. Экземпляр классифицируется с помощью ADTree, следуя всем путям, для которых все узлы решения истинны, и суммируя все пройденные узлы прогнозирования.
ADTrees были представлены Йоавом Фройндом и Лью Мэйсоном. Однако представленный алгоритм содержал несколько типографских ошибок. Разъяснения и оптимизации были позже представлены Бернхардом Пфарингером, Джеффри Холмсом и Ричардом Киркби. Реализации доступны в Weka и JBoost.
Исходные алгоритмы повышения обычно использовали либо пни принятия решений, либо деревья решений в качестве слабых гипотез. Например, при повышении точек принятия решения создается набор 
Повышение уровня простого ученика приводит к неструктурированному набору гипотез
Другой важной особенностью алгоритмов с усилением является то, что данным дается различное распределение на каждой итерации. Экземплярам, которые неправильно классифицированы, присваивается больший вес, а точно классифицированным экземплярам - уменьшенный вес.
Дерево альтернативных решений состоит из узлов решений и узлов прогнозирования. Узлы принятия решений определяют условие предиката. Узлы прогноза содержат одно число. ADTrees всегда имеют узлы прогнозирования как корневые, так и конечные. Экземпляр классифицируется ADTree, следуя всем путям, для которых все узлы решения истинны, и суммируя все пройденные узлы прогнозирования. Это отличается от бинарных деревьев классификации, таких как CART (Дерево классификации и регрессии ) или C4.5, в которых экземпляр следует только по одному пути через дерево.
Следующее дерево было построено с использованием JBoost в наборе данных спамба (доступно в репозитории машинного обучения UCI). В этом примере спам кодируется как 1, а обычная электронная почта - как -1.
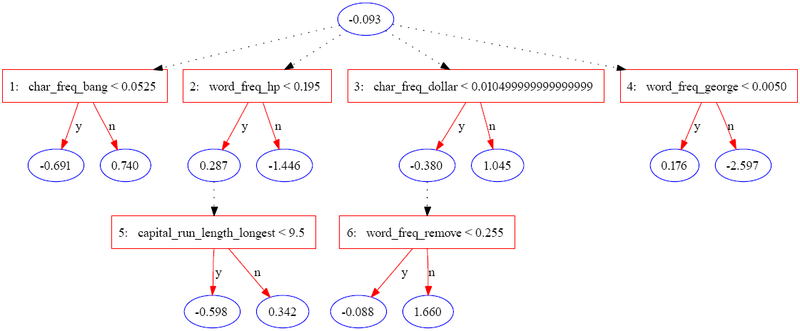
В следующей таблице содержится часть информации для одного экземпляра.
| Feature | Значение |
|---|---|
| char_freq_bang | 0,08 |
| word_freq_hp | 0,4 |
| capital_run_length_longest | 4 |
| char_freq_dollar | 0 |
| word_freq_remove | 0.9 |
| word_freq_george | 0 |
| Другие функции | ... |
Экземпляр оценивается путем суммирования всех узлов прогнозирования, через которые он проходит. В случае приведенного выше примера оценка рассчитывается как
| Итерация | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Значения экземпляра | Н / Д | .08 <.052 = f | .4 <.195 = f | 0 <.01 = t | 0 < 0.005 = t | Н / Д | .9 <.225 = f |
| Прогноз | -0,093 | 0,74 | -1,446 | - 0,38 | 0,176 | 0 | 1,66 |
Итоговая оценка 0,657 положительна, поэтому экземпляр классифицируется как спам. Величина значения является мерой уверенности в прогнозе. Первоначальные авторы перечисляют три возможных уровня интерпретации для набора атрибутов, идентифицированных ADTree:
Следует проявлять осторожность при интерпретации отдельных узлов, поскольку оценки отражают повторное взвешивание данных в каждой итерации.
Входными данными для алгоритма чередующегося дерева решений являются:
 где
где  - вектор атрибутов, а
- вектор атрибутов, а  либо -1, либо 1. Входные данные также называются экземплярами.
либо -1, либо 1. Входные данные также называются экземплярами. , соответствующий каждому экземпляру.
, соответствующий каждому экземпляру.Основным элементом алгоритма ADTree является правило. Одно правило состоит из предварительного условия, условия и двух оценок. Условие - это предикат формы «значение атрибута
1 if(предварительное условие) 2 if (условие) 3 return score_one 4 else 5 return score_two 6 end if 7 else 8 return 0 9 end if
Алгоритм также требует нескольких вспомогательных функций:
 возвращает сумму весов всех положительно помеченных примеров, которые удовлетворяют предикату
возвращает сумму весов всех положительно помеченных примеров, которые удовлетворяют предикату 
 возвращает сумму весов всех отрицательно помеченных примеров, которые удовлетворяют предикату
возвращает сумму весов всех отрицательно помеченных примеров, которые удовлетворяют предикату  возвращает сумму веса всех примеров, удовлетворяющих предикату
возвращает сумму веса всех примеров, удовлетворяющих предикату Алгоритм выглядит следующим образом:
1 function ad_tree 2 input Набор из m обучающих экземпляров 3 4 w i = 1 / m для всех i 56 R 0 = правило с оценками а и 0, предварительным условием «истина» и условием «истина». 7
8
набор всех возможных условий 9 для
10
получить значения, которые минимизируют
11
12
13
14 R j = новое правило с предусловием p, условием c и весами a 1 и a 2 15
16 конец для 17 return набор R j
Набор 
Рисунок 6 в исходной статье демонстрирует, что ADTrees обычно столь же устойчивы, как усиленные деревья решений и увеличенные пни принятия решений. Как правило, эквивалентной точности можно добиться с помощью гораздо более простой древовидной структуры, чем алгоритмы рекурсивного разделения.