
Войти
В информатике приоритет queue - это абстрактный тип данных, аналогичный обычной структуре данных queue или stack, в которой каждый элемент дополнительно имеет связанный с ним «приоритет». В очереди с приоритетом элемент с высоким приоритетом обслуживается перед элементом с низким приоритетом. В некоторых реализациях, если два элемента имеют одинаковый приоритет, они обслуживаются в соответствии с порядком, в котором они были поставлены в очередь, тогда как в других реализациях порядок элементов с одинаковым приоритетом не определен.
Хотя очереди с приоритетом часто реализуются с помощью куч, они концептуально отличаются от куч. Очередь с приоритетом - это такое понятие, как «список » или «карта »; Так же, как список может быть реализован с помощью связанного списка или массива, очередь с приоритетом может быть реализована с помощью кучи или множества других методов, таких как неупорядоченный массив.
Очередь с приоритетом должна как минимум поддерживать следующие операции :
Кроме того, peek (в этом контексте часто называется find-max или find-min), который возвращает элемент с наивысшим приоритетом, но не изменяет очереди, очень часто реализуется и почти всегда выполняется за O (1) времени. Эта операция и ее производительность O (1) имеют решающее значение для многих приложений очередей с приоритетом.
Более продвинутые реализации могут поддерживать более сложные операции, такие как pull_lowest_priority_element, проверка первых нескольких элементов с наивысшим или самым низким приоритетом, очистка очереди, очистка подмножеств очереди, выполнение пакетной вставки, объединение двух или более очереди в одну, увеличивая приоритет любого элемента и т. д.
Можно представить себе очередь с приоритетом как модифицированную очередь, но когда один из очереди получит следующий элемент, наивысший- приоритетный элемент извлекается первым.
Стеки и очереди могут быть смоделированы как определенные виды приоритетных очередей. Напоминаем, что вот как ведут себя стопки и очереди:
В стеке приоритет каждого вставленного элемента монотонно увеличивается; таким образом, последний вставленный элемент всегда извлекается первым. В очереди приоритет каждого вставленного элемента монотонно уменьшается; таким образом, первый вставленный элемент всегда извлекается первым.
Существует множество простых, обычно неэффективных способов реализации очереди с приоритетами. Они предоставляют аналогию, чтобы помочь понять, что такое приоритетная очередь.
Например, можно сохранить все элементы в несортированном списке (время вставки O (1)). Всякий раз, когда запрашивается элемент с наивысшим приоритетом, ищите среди всех элементов элемент с наивысшим приоритетом. (O (n) время вытягивания),
insert (node) {list.append (node)}pull () {foreach node in list {ifhest.priority < node.priority{ highest = node } } list.remove(highest) return highest }In В другом случае можно сохранить все элементы в списке сортировки по приоритету (время сортировки вставки O (n)), всякий раз, когда запрашивается элемент с наивысшим приоритетом, может быть возвращен первый в списке. (O (1) время извлечения)
вставить (узел) {foreach (индекс, элемент) в список {if node.priority < element.priority{ list.insert_at_index(node,index) } } }pull () {high = list.get_at_index (list. length-1) list.remove (высший) return высший}Для повышения производительности приоритетные очереди обычно используют кучу в качестве своей основы, что дает O ( log n) производительность для вставок и удалений и O (n) для первоначального построения из набора из n элементов. Варианты базовой структуры данных кучи, такие как кучи объединения или кучи Фибоначчи, могут обеспечить лучшие границы для некоторых операций.
В качестве альтернативы, когда самобалансируется используется двоичное дерево поиска, вставка и удаление также занимают время O (log n), хотя построение деревьев из существующих последовательностей элементов занимает время O (n log n); это типично, когда у кого-то уже может быть доступ к этим структурам данных, например, со сторонними или стандартными библиотеками.
С точки зрения вычислительной сложности очереди с приоритетами соответствуют алгоритмам сортировки. В разделе эквивалентность очередей с приоритетом и алгоритмов сортировки ниже описывается, как эффективные алгоритмы сортировки могут создавать эффективные очереди с приоритетами.
Существует несколько специализированных структур данных heap , которые либо предоставляют дополнительные операции, либо превосходят реализации на основе кучи для определенных типов ключей, конкретно целочисленные ключи. Предположим, что набор возможных ключей равен {1, 2,..., C}.
 времени. Однако автор заявляет, что «наши алгоритмы представляют только теоретический интерес; постоянные факторы, влияющие на время выполнения, исключают практичность».
времени. Однако автор заявляет, что «наши алгоритмы представляют только теоретический интерес; постоянные факторы, влияющие на время выполнения, исключают практичность».Для приложений, которые выполняют много операций «peek » для каждого » extract-min "временная сложность действий просмотра может быть снижена до O (1) во всех реализациях дерева и кучи путем кэширования элемента с наивысшим приоритетом после каждой вставки и удаления. Для вставки это добавляет максимум постоянную стоимость, поскольку вновь вставленный элемент сравнивается только с ранее кэшированным минимальным элементом. Для удаления это не более чем добавляет дополнительную стоимость «просмотра», которая обычно дешевле, чем стоимость удаления, поэтому общая временная сложность существенно не влияет.
Очереди с монотонным приоритетом - это специализированные очереди, оптимизированные для случая, когда никогда не вставляется элемент с более низким приоритетом (в случае min-heap), чем любой ранее извлеченный элемент. Это ограничение встречается в нескольких практических приложениях приоритетных очередей.
Вот временная сложность различных структур данных кучи. Имена функций предполагают минимальную кучу. Значение «O (f)» и «Θ (f)» см. В нотации Big O.
| Operation | find-min | delete-min | вставить | кнопка уменьшения | meld |
|---|---|---|---|---|---|
| двоичный | Θ (1) | Θ (log n) | O (log n) | O (log n) | Θ (n) |
| Левый | Θ (1) | Θ (log n) | Θ (log n) | O (log n) | Θ (log n) |
| Биномиальный | Θ (1) | Θ (log n) | Θ(1) | Θ (log n) | O (log n) |
| Фибоначчи | Θ (1) | O (log n) | Θ (1) | Θ(1) | Θ (1) |
| Сопряжение | Θ (1) | O (log n) | Θ (1) | o (log n) | Θ (1) |
| Brodal | Θ (1) | O (журнал n) | Θ (1) | Θ (1) | Θ (1) |
| Θ (1) | O (log n) | Θ (1) | Θ(1) | Θ (1) | |
| Строгий Фибоначчи | Θ (1) | O (log n) | Θ (1) | Θ (1) | Θ (1) |
| 2–3 куча | O (log n) | O (log n) | O (log n) | Θ (1) | ? |
Семантика приоритетных очередей, естественно, предполагает метод сортировки: вставьте все элементы для сортировки в приоритетную очередь и последовательно удалите их; они появятся в отсортированном порядке. Фактически это процедура, используемая несколькими алгоритмами сортировки после удаления уровня абстракции, обеспечиваемого очередью приоритетов. Этот метод сортировки эквивалентен следующим алгоритмам сортировки:
| Имя | Реализация приоритетной очереди | Лучшее | Среднее | Худшее |
|---|---|---|---|---|
| Heapsort | Куча |  | | |
| Smoothsort | Leonardo Heap |  | | |
| Сортировка выбора | Неупорядоченный Массив |  | | |
| Сортировка вставкой | Упорядоченный Массив | | | |
| Сортировка по дереву | Самобалансирующееся двоичное дерево поиска | | | |
Алгоритм сортировки может o использоваться для реализации очереди с приоритетом. В частности, Торуп говорит:
Мы представляем общее детерминированное линейное сокращение пространства от очередей приоритета до сортировки, подразумевая, что если мы можем отсортировать до n ключей за S (n) раз на каждый ключ, тогда будет очередь с приоритетом, поддерживающая удаление и вставку за время O (S (n)) и найти мин за постоянное время.
То есть, если существует алгоритм сортировки, который может сортировать за время O (S) на ключ, где S - некоторая функция от n и размер слова, то можно использовать данную процедуру для создания очередь с приоритетом, в которой извлечение элемента с наивысшим приоритетом занимает время O (1), а вставка новых элементов (и удаление элементов) - время O (S). Например, если у кого-то есть алгоритм сортировки O (n log n), можно создать приоритетную очередь с O (1) вытягиванием и O (n log n) вставкой.
Очередь с приоритетом часто рассматривается как «структура данных контейнера ».
Стандартная библиотека шаблонов (STL) и C ++ 1998 стандарт определяет priority_queueкак один из контейнеров STL адаптер шаблоны классов. Однако он не определяет, как должны обслуживаться два элемента с одинаковым приоритетом, и действительно, общие реализации не будут возвращать их в соответствии с их порядком в очереди. Он реализует очередь с максимальным приоритетом и имеет три параметра: объект сравнения для сортировки, такой как объект функции (по умолчанию меньше
Модуль Python heapq реализует двоичную минимальную кучу поверх списка.
Библиотека Java содержит класс PriorityQueue , который реализует очередь с минимальным приоритетом. Библиотека
Scala содержит класс PriorityQueue, который реализует очередь с максимальным приоритетом. Библиотека
Go содержит модуль контейнер / куча, который реализует минимальную кучу поверх любой совместимой структуры данных.
Расширение стандартной библиотеки PHP содержит класс SplPriorityQueue.
каркас Apple Core Foundation содержит структуру CFBinaryHeap, которая реализует мин-куча.
Очередь с приоритетом может использоваться для управления ограниченными ресурсами, такими как полоса пропускания на линии передачи из сети маршрутизатор. В случае постановки в очередь исходящего трафика из-за недостаточной пропускной способности все другие очереди могут быть остановлены для отправки трафика из очереди с наивысшим приоритетом по прибытии. Это гарантирует, что приоритетный трафик (например, трафик в реальном времени, например, поток RTP соединения VoIP ) пересылается с наименьшей задержкой и наименьшей вероятностью отклонения из-за очередь достигает максимальной емкости. Весь остальной трафик может обрабатываться, когда очередь с наивысшим приоритетом пуста. Другой используемый подход - отправка непропорционально большего объема трафика из очередей с более высоким приоритетом.
Многие современные протоколы для локальных сетей также включают концепцию приоритетных очередей на подуровне управления доступом к среде (MAC), чтобы гарантировать, что высокоприоритетные приложения (например, VoIP или IPTV ) имеют более низкую задержку, чем другие приложения, которые могут обслуживаться с помощью службы наилучшего качества. Примеры включают IEEE 802.11e (поправка к IEEE 802.11, которая обеспечивает качество обслуживания ) и ITU-T G. hn (стандарт для высокоскоростной локальной сети с использованием существующей домашней проводки (линии питания, телефонные линии и коаксиальные кабели ).
Обычно устанавливается ограничение (ограничитель) для ограничения пропускной способности, которую может принимать трафик из очереди с наивысшим приоритетом, чтобы пакеты с высоким приоритетом не подавляли весь другой трафик. Этот предел обычно никогда не достигается из-за контроля высокого уровня экземпляры, такие как Cisco, которые можно запрограммировать на запрет вызовов, превышающих запрограммированный предел пропускной способности.
Другое использование очереди с приоритетами - это управлять событиями в моделировании дискретных событий . События добавляются в очередь с использованием времени их моделирования в качестве приоритета. Выполнение моделирования продолжается путем многократного вытягивания вершины очередь и выполнение в ней события.
См. Также: Планирование (вычисления), теория массового обслуживания
Когда граф хранится в виде списка смежности или матрица, приоритетная очередь может использоваться для минимального эффективного извлечения при реализации алгоритма Дейкстры, хотя также необходима возможность эффективного изменения приоритета конкретной вершины в приоритетной очереди.
Кодирование Хаффмана требует, чтобы один код неоднократно получал два низкочастотных дерева. Очередь с приоритетами - это один из методов выполнения этого.
поиска лучшего первого, такие как алгоритм поиска A *, найти кратчайший путь между две вершины или узлов взвешенного графа, сначала пробуя наиболее перспективные маршруты. Очередь с приоритетом (также известная как бахрома) используется для отслеживания неисследованных маршрутов; тот, для которого оценка (нижняя граница в случае A *) общей длины пути является наименьшей, получает наивысший приоритет. Если ограничения памяти делают поиск лучшего первого непрактичным, вместо него можно использовать такие варианты, как алгоритм SMA *, с двусторонней приоритетной очередью, чтобы разрешить удаление элементов с низким приоритетом.
Алгоритм оптимальной адаптации сеток в реальном времени (ROAM ) вычисляет динамически изменяющуюся триангуляцию местности. Он работает, разделяя треугольники там, где требуется больше деталей, и объединяя их там, где требуется меньше деталей. Алгоритм присваивает каждому треугольнику на местности приоритет, обычно связанный с уменьшением ошибки, если этот треугольник будет разделен. Алгоритм использует две очереди приоритета: одну для треугольников, которые можно разделить, а другую для треугольников, которые можно объединить. На каждом шаге треугольник из очереди разделения с наивысшим приоритетом разделяется, или треугольник из очереди слияния с самым низким приоритетом объединяется со своими соседями.
Использование очереди с минимальным приоритетом кучи в алгоритме Прима для поиска минимального связующего дерева соединенного и неориентированного графа можно добиться хорошего времени работы. Эта очередь с минимальным приоритетом кучи использует структуру данных минимальной кучи, которая поддерживает такие операции, как вставка, минимум, извлечение-минимум, уменьшение-ключ. В этой реализации вес ребер используется для определения приоритета вершин. Меньше вес, выше приоритет и выше вес, ниже приоритет.
Распараллеливание может использоваться для ускорения очередей с приоритетом, но требует некоторых изменений в интерфейсе очереди с приоритетами. Причина таких изменений в том, что последовательное обновление обычно имеет только 


Если приоритетная очередь разрешает одновременный доступ, несколько процессов могут выполнять операции одновременно с этой приоритетной очередью. Однако здесь возникают две проблемы. Прежде всего, определение семантики отдельных операций перестало быть очевидным. Например, если два процесса хотят извлечь элемент с наивысшим приоритетом, должны ли они получить один и тот же элемент или разные? Это ограничивает параллелизм на уровне программы, использующей очередь приоритетов. Кроме того, поскольку несколько процессов имеют доступ к одному и тому же элементу, это приводит к конфликту.
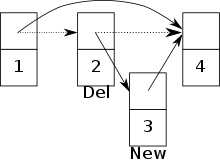 Узел 3 вставляется и устанавливает указатель узла 2 на узел 3. Сразу после этого узел 2 удаляется, а указатель узла 1 устанавливается на узел 4. Теперь узел 3 больше недоступен.
Узел 3 вставляется и устанавливает указатель узла 2 на узел 3. Сразу после этого узел 2 удаляется, а указатель узла 1 устанавливается на узел 4. Теперь узел 3 больше недоступен. параллельный доступ к приоритетной очереди может быть реализован в модели PRAM с одновременным чтением и одновременной записью (CRCW). Далее очередь с приоритетом реализована как список пропусков . Кроме того, примитив атомарной синхронизации CAS используется для освобождения списка пропуска блокировки. Узлы списка пропусков состоят из уникального ключа, приоритета, массива из указателей для каждого уровня, на следующие узлы и метки удаления. Метка удаления отмечает, что узел собирается быть удаленным процессом. Это гарантирует, что другие процессы могут соответствующим образом отреагировать на удаление.
Если разрешен одновременный доступ к приоритетной очереди, между двумя процессами могут возникнуть конфликты. Например, конфликт возникает, если один процесс пытается вставить новый узел, но в то же время другой процесс собирается удалить предшественника этого узла. Есть риск, что новый узел будет добавлен в список пропуска, но станет недоступен. (См. Изображение )
В этом параметре операции с приоритетной очередью обобщаются для пакета из
В настройке совместно используемой памяти, очередь с параллельным приоритетом может быть легко реализована с использованием параллельных двоичных деревьев поиска и алгоритмов дерева на основе соединения. В частности, k_extract-min соответствует разделению в двоичном дереве поиска который имеет 

В оставшейся части этого раздела обсуждается алгоритм распределенной памяти на основе очередей. Мы предполагаем, что каждый процессор имеет свою собственную локальную память и локальную (последовательную) очередь приоритетов. Элементы глобальной (параллельной) очереди приоритета распределяются по всем процессорам.
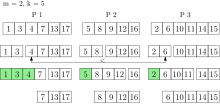 k_extract-min выполняется в очереди приоритетов с тремя процессорами. Зеленые элементы возвращаются и удаляются из очереди приоритетов.
k_extract-min выполняется в очереди приоритетов с тремя процессорами. Зеленые элементы возвращаются и удаляются из очереди приоритетов. Операция k_insert назначает элементы равномерно случайным образом процессорам, которые вставляют элементы в свои локальные очереди. Обратите внимание, что отдельные элементы все еще могут быть вставлены в очередь. При использовании этой стратегии наименьшие глобальные элементы находятся в объединении наименьших локальных элементов каждого процессора с высокой вероятностью. Таким образом, каждый процессор содержит репрезентативную часть очереди с глобальным приоритетом.
Это свойство используется, когда выполняется k_extract-min, поскольку наименьшие элементы 




Очередь приоритетов может быть дополнительно улучшена, если не перемещать оставшиеся элементы набора результатов непосредственно обратно в локальные очереди после операции k_extract-min. Это позволяет избежать постоянного перемещения элементов между набором результатов и локальными очередями.
Удалив сразу несколько элементов, можно значительно ускорить работу. Но не все алгоритмы могут использовать такую приоритетную очередь. Например, алгоритм Дейкстры не может работать сразу на нескольких узлах. Алгоритм берет узел с наименьшим расстоянием от очереди приоритетов и вычисляет новые расстояния для всех его соседних узлов. Если вы удалите узлы
std :: priority_queue {kind=link}