
Войти
В информатике, парсеры LR - это тип восходящего синтаксического анализатора, который анализирует детерминированные контекстно-свободные языки за линейное время. Есть несколько вариантов парсеров LR: SLR парсеры, LALR парсеры, Канонические LR (1) парсеры, Минимальные LR (1) парсеры, GLR парсеры. Синтаксические анализаторы LR могут быть сгенерированы генератором синтаксического анализатора из формальной грамматики, определяющей синтаксис анализируемого языка. Они широко используются для обработки компьютерных языков.
синтаксического анализатора LR (L слева направо, R самое прямое происхождение в обратном порядке) считывает входной текст слева направо без резервного копирования (это верно для большинства парсеров) и производит крайнее правое производное в обратном порядке: он выполняет восходящий синтаксический анализ, а не нисходящий синтаксический анализ LL или специальный синтаксический анализ. За именем LR часто следует числовой квалификатор, например, LR (1) или иногда LR (k) . Чтобы избежать обратного отслеживания или угадывания, синтаксическому анализатору LR разрешено заглядывать вперед на k lookahead input символов, прежде чем решать, как анализировать более ранние символы. Обычно k равно 1 и не упоминается. Имя LR часто предшествует другим квалификаторам, например, SLR и LALR . Условие LR (k) для грамматики было предложено Кнутом как «переводимый слева направо с ограничением k».
Парсеры LR детерминированы; они производят единственный правильный синтаксический анализ без догадок или отката в линейное время. Это идеально подходит для компьютерных языков, но парсеры LR не подходят для человеческих языков, которым нужны более гибкие, но неизбежно более медленные методы. Некоторые методы, которые могут анализировать произвольные контекстно-свободные языки (например, Кок – Янгер – Касами, Эрли, GLR ), имеют производительность O (n) раз. Другие методы, которые возвращают или дают несколько синтаксических анализов, могут даже занять экспоненциальное время, если они плохо угадывают.
Вышеупомянутые свойства L, Rи k фактически используются всеми shift- уменьшить парсеры, включая парсеры приоритета . Но по соглашению имя LR обозначает форму синтаксического анализа, изобретенную Дональдом Кнутом, и исключает более ранние, менее мощные методы приоритета (например, синтаксический анализатор приоритета оператора ). Парсеры LR могут обрабатывать больший диапазон языков и грамматик, чем парсеры приоритета или нисходящий анализ LL. Это связано с тем, что синтаксический анализатор LR ожидает, пока он не увидит полный экземпляр некоторого грамматического шаблона, прежде чем совершить то, что он нашел. Анализатор LL должен решить или угадать, что он видит, гораздо раньше, когда он видел только крайний левый входной символ этого шаблона.
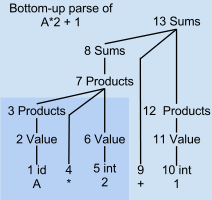 Снизу вверх дерево синтаксического анализа, построенное с пронумерованными шагами
Снизу вверх дерево синтаксического анализа, построенное с пронумерованными шагами Парсер LR сканирует и анализирует входной текст за один проход по тексту. Синтаксический анализатор строит дерево синтаксического анализа постепенно, снизу вверх и слева направо, без угадывания или возврата. На каждом этапе этого прохода синтаксический анализатор накапливает список поддеревьев или фраз входного текста, которые уже были проанализированы. Эти поддеревья еще не объединены, потому что синтаксический анализатор еще не достиг правого конца синтаксического шаблона, который будет их объединять.
На шаге 6 в примере синтаксического анализа только "A * 2" был проанализирован не полностью. Существует только затененный нижний левый угол дерева синтаксического анализа. Ни один из узлов дерева синтаксического анализа с номерами 7 и выше еще не существует. Узлы 3, 4 и 6 являются корнями изолированных поддеревьев для переменной A, оператора * и числа 2 соответственно. Эти три корневых узла временно хранятся в стеке синтаксического анализа. Оставшаяся неанализируемая часть входного потока равна «+ 1».
Как и другие парсеры сдвига-уменьшения, синтаксический анализатор LR работает, выполняя некоторую комбинацию шагов сдвига и уменьшения шагов.
Если input не имеет синтаксических ошибок, синтаксический анализатор продолжает эти шаги до тех пор, пока весь ввод не будет использован, и все деревья синтаксического анализа не будут сведены к одному дереву, представляющему весь допустимый ввод.
Парсеры LR отличаются от других парсеров сдвига-уменьшения тем, как они решают, когда сокращать, и как выбирать между правилами с похожими окончаниями. Но окончательные решения и последовательность шагов сдвига или уменьшения одинаковы.
Эффективность синтаксического анализатора LR во многом обусловлена детерминированностью. Чтобы избежать догадок, анализатор LR часто смотрит вперед (вправо) на следующий отсканированный символ, прежде чем решить, что делать с ранее отсканированными символами. Лексический сканер опережает синтаксический анализатор на один или несколько символов. Символы опережающего просмотра являются «правым контекстом» для решения о синтаксическом анализе.
 Анализатор снизу вверх на шаге 6
Анализатор снизу вверх на шаге 6 Как и другие сдвиги- reduce parsers, парсер LR лениво ждет, пока он не просканирует и не проанализирует все части некоторой конструкции, прежде чем зафиксировать, что представляет собой комбинированная конструкция. Затем синтаксический анализатор немедленно воздействует на комбинацию, а не ждет дальнейшего. В примере с деревом синтаксического анализа фраза A сокращается до Value, а затем до Products на шагах 1-3, как только просматривается опережающий *, вместо того, чтобы ждать позже, чтобы организовать эти части дерева синтаксического анализа. Решения о том, как обрабатывать A, основаны только на том, что синтаксический анализатор и сканер уже видели, без учета вещей, которые появляются намного позже справа.
Редукции реорганизуют самые недавно проанализированные объекты, непосредственно слева от символа просмотра вперед. Таким образом, список уже проанализированных вещей действует как стек . Этот стек синтаксического анализа увеличивается вправо. Основание или нижняя часть стека находится слева и содержит самый левый, самый старый фрагмент синтаксического анализа. Каждый шаг редукции действует только на самые правые, самые новые фрагменты синтаксического анализа. (Этот накопительный стек синтаксического анализа очень отличается от прогнозирующего, увеличивающегося влево стека синтаксического анализа, используемого нисходящими синтаксическими анализаторами.)
| Шаг | Разбор стека | Без анализа | Сдвиг / Уменьшение |
|---|---|---|---|
| 0 | пустой | A * 2 + 1 | shift |
| 1 | id | * 2 + 1 | Значение → id |
| 2 | Значение | * 2 + 1 | Продукты → Значение |
| 3 | Продукты | * 2 + 1 | сдвиг |
| 4 | Продукты * | 2 + 1 | shift |
| 5 | Продукты * int | + 1 | Значение → int |
| 6 | Продукты * Значение | + 1 | Продукты → Продукты * Стоимость |
| 7 | Продукты | + 1 | Суммы → Продукты |
| 8 | Суммы | + 1 | shift |
| 9 | Sums + | 1 | shift |
| 10 | Sums + int | eof | Value → int |
| 11 | Sums + Value | eof | Products → Value |
| 12 | Sums + Products | eof | Sums → Sums + Products |
| 13 | Sums | eof | done |
На шаге 6 применяется правило грамматики, состоящее из нескольких частей:
Это соответствует верхнему удержанию стека. ng проанализированных фраз "... Товары * Стоимость". Шаг уменьшения заменяет этот экземпляр правой части правила, «Products * Value», на левый символ правила, в данном случае на более крупный Products. Если синтаксический анализатор строит полные деревья синтаксического анализа, три дерева для внутренних продуктов, * и Value объединяются новым корнем дерева для продуктов. В противном случае семантические детали из внутренних продуктов и значения выводятся на более поздний этап компилятора или объединяются и сохраняются в новом символе продуктов.
В синтаксических анализаторах LR решения о сдвиге и сокращении потенциально основаны на всем стеке всего, что было предварительно проанализировано, а не только на одном, самом верхнем символе стека. Если сделать это неумелым образом, это может привести к очень медленным анализаторам, которые становятся все медленнее и медленнее для более длинных входных данных. Парсеры LR делают это с постоянной скоростью, суммируя всю релевантную информацию левого контекста в одно число, называемое состоянием парсера LR (0) . Для каждой грамматики и метода анализа LR существует фиксированное (конечное) количество таких состояний. Помимо хранения уже проанализированных символов, стек синтаксического анализа также запоминает номера состояний, достигнутые всем до этих точек.
На каждом шаге синтаксического анализа весь входной текст делится на стопку ранее проанализированных фраз, текущий предварительный символ и оставшийся неотсканированный текст. Следующее действие парсера определяется его текущим номером состояния LR (0) (крайний правый в стеке) и опережающим символом. В приведенных ниже шагах все черные детали точно такие же, как и в других синтаксических анализаторах, не относящихся к LR. Стек синтаксического анализатора LR добавляет информацию о состоянии фиолетовым цветом, суммируя черные фразы слева от них в стеке и то, какие возможности синтаксиса следует ожидать дальше. Пользователи парсера LR обычно могут игнорировать информацию о состоянии. Эти состояния объясняются в следующем разделе.
| . Шаг | Анализ стека., состояние [Символ состояние ] * | Смотреть. Впереди | . Не просканировано | Анализатор. Действие | . Правило грамматики | Следующее. Состояние |
|---|---|---|---|---|---|---|
| 0 | 0 | id | * 2 + 1 | shift | 9 | |
| 1 | 0id9 | * | 2 + 1 | reduce | Value → id | 7 |
| 2 | 0Значение 7 | * | 2 + 1 | уменьшить | Продукты → Значение | 4 |
| 3 | 0Продукты 4 | * | 2 + 1 | shift | 5 | |
| 4 | 0Продукты 4*5 | int | + 1 | shift | 8 | |
| 5 | 0Продукты 4*5int 8 | + | 1 | reduce | Value → int | 6 |
| 6 | 0Products 4*5Value 6 | + | 1 | reduce | Продукты → Продукты * Стоимость | 4 |
| 7 | 0Продукты 4 | + | 1 | уменьшить | Суммы → Продукты | 1 |
| 8 | 0Суммы 1 | + | 1 | сдвиг | 2 | |
| 9 | 0Суммы 1+2 | int | eof | shift | 8 | |
| 10 | 0Суммирует 1+2int 8 | eof | reduce | Value → int | 7 | |
| 11 | 0Суммирует 1+2Value 7 | eof | reduce | Продукты → Значение | 3 | |
| 12 | 0Суммы 1+2Продукты 3 | eof | уменьшить | Sums → Sums + Products | 1 | |
| 13 | 0Sums 1 | eof | done |
Первоначально на шаге 0 входной поток «A * 2 + 1» делится на
Стек синтаксического анализа начинается с сохранения только начального состояния 0. Когда состояние 0 видит идентификатор опережающего просмотра, оно знает, что нужно сдвинуть этот идентификатор в стек и сканировать следующий входной символ * и переходите к состоянию 9.
На шаге 4 общий входной поток «A * 2 + 1» в настоящее время делится на
Состояния, соответствующие сложенным фразам: 0, 4 и 5. Текущие, крайнее правое состояние в стеке - это состояние 5. Когда состояние 5 видит опережающий int, оно знает, что нужно переместить это int в стек как свою собственную фразу, сканировать следующий входной символ + и перейти к состоянию 8.
На шаге 12 весь входной поток израсходован, но организован лишь частично. Текущее состояние - 3. Когда состояние 3 видит опережающий eof, оно знает, что нужно применить завершенное правило грамматики
, объединив три крайние правые фразы стека для Sums, +, и продукты в одно целое. Само состояние 3 не знает, каким должно быть следующее состояние. Это можно найти, вернувшись в состояние 0, слева от сокращаемой фразы. Когда состояние 0 видит этот новый завершенный экземпляр Sums, он переходит в состояние 1 (снова). Консультации со старыми состояниями - вот почему они хранятся в стеке, а не только в текущем состоянии.
Парсеры LR построены на основе грамматики, которая формально определяет синтаксис языка ввода как набор шаблонов. Грамматика не охватывает все языковые правила, такие как размер чисел или последовательное использование имен и их определений в контексте всей программы. Парсеры LR используют контекстно-свободную грамматику, которая имеет дело только с локальными шаблонами символов.
Используемый здесь пример грамматики представляет собой крошечное подмножество языка Java или C:
терминальные символы грамматики - это многосимвольные символы или «токены», обнаруженные во входном потоке с помощью лексического сканера. Здесь они включают +*и int для любой целочисленной константы, id для любого имени идентификатора и eof для конца входного файла. Грамматика не заботится о значениях int или написании id, а также о пробелах или переносах строк. Грамматика использует эти терминальные символы, но не определяет их. Они всегда являются листовыми узлами (в нижнем густом конце) дерева синтаксического анализа.
Термины, написанные с заглавной буквы, например суммы, представляют собой нетерминальные символы. Это названия концепций или шаблонов в языке. Они определены в грамматике и никогда не встречаются во входном потоке. Они всегда являются внутренними узлами (над нижней частью) дерева синтаксического анализа. Они происходят только в результате применения парсером некоторого грамматического правила. Некоторые нетерминалы определяются двумя или более правилами; это альтернативные модели. Правила могут ссылаться на себя, что называется рекурсивным. Эта грамматика использует рекурсивные правила для обработки повторяющихся математических операторов. Грамматики для полных языков используют рекурсивные правила для обработки списков, выражений в скобках и вложенных операторов.
Любой компьютерный язык может быть описан несколькими разными грамматиками. Парсер LR (1) может обрабатывать многие, но не все общие грамматики. Обычно можно вручную изменить грамматику, чтобы она соответствовала ограничениям синтаксического анализа LR (1) и инструмента генератора.
Грамматика для синтаксического анализатора LR должна быть однозначной сама по себе или должна быть дополнена правилами приоритета разрешения конфликтов. Это означает, что существует только один правильный способ применения грамматики к данному легальному примеру языка, в результате чего получается уникальное дерево синтаксического анализа с одним значением и уникальная последовательность действий сдвига / уменьшения для этого примера. Анализ LR не является полезным методом для человеческих языков с неоднозначной грамматикой, зависящей от взаимодействия слов. Человеческие языки лучше обрабатываются синтаксическими анализаторами, такими как обобщенный синтаксический анализатор LR, синтаксический анализатор Эрли или алгоритм CYK, который может одновременно вычислять все возможные деревья синтаксического анализа за один проход.
Большинство синтаксических анализаторов LR управляются таблицами. Программный код парсера представляет собой простой универсальный цикл, одинаковый для всех грамматик и языков. Знание грамматики и ее синтаксические последствия кодируются в неизменяемые таблицы данных, называемые таблицы синтаксического анализа (или таблицы синтаксического анализа ). Записи в таблице показывают, следует ли сдвигать или уменьшать (и по какому правилу грамматики) для каждой допустимой комбинации состояния синтаксического анализатора и символа опережающего просмотра. Таблицы синтаксического анализа также сообщают, как вычислить следующее состояние, учитывая только текущее состояние и следующий символ.
Таблицы синтаксического анализа намного больше грамматики. Таблицы LR трудно точно вычислить вручную для больших грамматик. Таким образом, они механически выводятся из грамматики с помощью некоторого инструмента генератора синтаксического анализатора, такого как Bison.
В зависимости от того, как генерируются состояния и таблица синтаксического анализа, результирующий синтаксический анализатор называется либо SLR (простой LR) синтаксический анализатор, LALR (упреждающий LR) синтаксический анализатор, или канонический синтаксический анализатор LR. Парсеры LALR обрабатывают больше грамматик, чем парсеры SLR. Канонические парсеры LR обрабатывают еще больше грамматик, но используют гораздо больше состояний и таблицы гораздо большего размера. Пример грамматики - SLR.
Таблицы синтаксического анализа LR двумерны. Каждое текущее состояние парсера LR (0) имеет свою собственную строку. Каждый возможный следующий символ имеет свой столбец. Некоторые комбинации состояния и следующего символа невозможны для допустимых входных потоков. Эти пустые ячейки вызывают сообщения об ошибках синтаксиса.
В левой половине таблицы Action есть столбцы для упреждающих оконечных символов. Эти ячейки определяют, будет ли следующим действием синтаксического анализатора сдвиг (в состояние n) или уменьшение (по правилу грамматики rn).
В правой половине таблицы Перейти к есть столбцы для нетерминальных символов. Эти ячейки показывают, к какому состоянию перейти после того, как левая сторона некоторого сокращения создала ожидаемый новый экземпляр этого символа. Это похоже на действие сдвига, но для нетерминалов; символ упреждающего терминала не изменился.
Столбец таблицы «Текущие правила» документирует значение и возможности синтаксиса для каждого состояния, разработанные генератором синтаксического анализатора. Он не входит в фактические таблицы, используемые во время анализа. Маркер • (розовая точка) показывает, где сейчас находится синтаксический анализатор в пределах некоторых частично распознанных грамматических правил. Объекты слева от • были проанализированы, и объекты справа ожидаются в ближайшее время. Состояние имеет несколько таких текущих правил, если синтаксический анализатор еще не сузил возможности до одного правила.
| Curr | Lookahead | LHS Goto | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| State | Current Rules | int | id | * | + | eof | Sums | Products | Значение | |
| 0 | Цель → • Сумма | 8 | 9 | 1 | 4 | 7 | ||||
| 1 | Цель → Суммы • eof. Суммы → Суммы • + Продукты | . 2 | выполнено. | |||||||
| 2 | Суммы → Суммы + • Продукты | 8 | 9 | 3 | 7 | |||||
| 3 | Суммы → Суммы + Продукты •. Продукты → Продукты • * Значение | . 5 | r1. | r1. | ||||||
| 4 | Суммы → Продукты •. Продукты → Продукты • * Значение | . 5 | r2. | r2. | ||||||
| 5 | Продукты → Продукты * • Значение | 8 | 9 | 6 | ||||||
| 6 | Продукты → Продукты * Значение • | r3 | r3 | r3 | ||||||
| 7 | Продукты → Значение • | r4 | r4 | r4 | ||||||
| 8 | Значение → int • | r5 | r5 | r5 | ||||||
| 9 | Значение → id • | r6 | r6 | r6 | ||||||
В состоянии 2 выше синтаксический анализатор только что нашел и сдвинул + правила грамматики
Следующая ожидаемая фраза - Products. Товары начинаются с терминальных символов int или id. Если предварительный просмотр является одним из тех, синтаксический анализатор сдвигает их и переходит в состояние 8 или 9 соответственно. Когда продукт найден, анализатор переходит в состояние 3, чтобы собрать полный список слагаемых и найти конец правила r0. Товары также могут начинаться с нетерминального значения. Для любого другого опережающего или нетерминального сообщения синтаксический анализатор сообщает о синтаксической ошибке.
В состоянии 3 синтаксический анализатор только что нашел фразу Products, которая могла быть основана на двух возможных грамматических правилах:
Выбор между r1 и r3 не может быть решен, просто взглянув назад на предыдущие фразы. Синтаксический анализатор должен проверить символ опережающего просмотра, чтобы сказать, что делать. Если опережающий просмотр *, он находится в правиле 3, поэтому синтаксический анализатор переходит в * и переходит к состоянию 5. Если опережающий просмотр - eof, он находится в конце правила. 1 и правило 0, так что синтаксический анализатор готов.
В состоянии 9, приведенном выше, все непустые, не содержащие ошибок ячейки относятся к одному и тому же сокращению r6. Некоторые парсеры экономят время и табличное пространство, не проверяя в этих простых случаях опережающий символ. Затем синтаксические ошибки обнаруживаются несколько позже, после некоторых безвредных сокращений, но еще до следующего действия сдвига или решения синтаксического анализатора.
Отдельные ячейки таблицы не должны содержать несколько альтернативных действий, в противном случае синтаксический анализатор будет недетерминированным с догадками и обратным отслеживанием. Если грамматика не LR (1), в некоторых ячейках будут возникать конфликты сдвига / уменьшения между возможным действием сдвига и действия уменьшения или конфликты уменьшения / уменьшения между несколькими правилами грамматики. Парсеры LR (k) разрешают эти конфликты (где это возможно), проверяя дополнительные символы опережающего просмотра помимо первого.
Анализатор LR начинается с почти пустого стека синтаксического анализа, содержащего только начальное состояние 0, и с опережающего просмотра, содержащего первый отсканированный символ входного потока. Затем синтаксический анализатор повторяет следующий шаг цикла до тех пор, пока не будет выполнен или не остановится на синтаксической ошибке:
Самым верхним состоянием в стеке синтаксического анализа является некоторое состояние s, а текущим опережающим просмотром является некоторый конечный символ t. Найдите следующее действие парсера в строке s и столбце t таблицы Lookahead Action. Это действие - Shift, Уменьшение, Готово или Ошибка:
Стек парсера LR обычно хранит только состояния LR (0) автомата, поскольку символы грамматики могут быть получены из них (в автомате все входные переходы в какое-либо состояние помечены значком тот же символ, который является символом, связанным с этим состоянием). Более того, эти символы почти никогда не нужны, поскольку состояние - это все, что имеет значение при принятии решения о синтаксическом анализе.
Этот раздел статьи может быть пропущен большинством пользователей парсера LR генераторы.
Состояние 2 в примере таблицы синтаксического анализа относится к правилу частичного синтаксического анализа
Это показывает, как синтаксический анализатор попал сюда, увидев Sums, затем + при поиске больших Sums. Маркер • переместился за пределы начала правила. Он также показывает, как синтаксический анализатор ожидает в конечном итоге завершить правило, найдя в следующий раз полные продукты. Но необходимы дополнительные сведения о том, как анализировать все части этих продуктов.
Частично проанализированные правила для состояния называются его "основными элементами LR (0)". Генератор синтаксического анализатора добавляет дополнительные правила или элементы для всех возможных следующих шагов в создании ожидаемых продуктов:
Маркер • находится в начале каждого из этих добавленных правил; парсер еще не подтвердил и не проанализировал какую-либо их часть. Эти дополнительные элементы называются «закрытием» основных элементов. Для каждого нетерминального символа, следующего сразу за •, генератор добавляет правила, определяющие этот символ. Это добавляет дополнительные маркеры • и, возможно, другие символы-последователи. Этот процесс закрытия продолжается до тех пор, пока все символы-последователи не будут развернуты. Последовательные нетерминалы для состояния 2 начинаются с Products. Затем стоимость добавляется закрытием. Терминалы последователя - это int и id.
Ядро и элементы закрытия вместе показывают все возможные законные способы перехода от текущего состояния к будущим состояниям и полным фразам. Если символ последователя появляется только в одном элементе, он приводит к следующему состоянию, содержащему только один базовый элемент с выдвинутым маркером •. Таким образом, int приводит к следующему состоянию 8 с ядром
Если один и тот же символ последователя появляется в нескольких элементах, синтаксический анализатор еще не может сказать, какое правило здесь применяется. Таким образом, этот символ ведет к следующему состоянию, в котором показаны все оставшиеся возможности, опять же с продвинутым маркером •. Продукты появляются как в r1, так и в r3. Таким образом, Products приводит к следующему состоянию 3 с ядром
На словах это означает, что синтаксический анализатор обнаружил единичные продукты, это может быть сделано, или у него может быть еще больше вещей для умножения вместе. Все основные элементы имеют один и тот же символ перед маркером • ; все переходы в это состояние всегда имеют один и тот же символ.
Некоторые переходы будут к ядрам и состояниям, которые уже были перечислены. Другие переходы приводят к новым состояниям. Генератор начинается с целевого правила грамматики. Оттуда он продолжает исследовать известные состояния и переходы, пока не будут найдены все необходимые состояния.
Эти состояния называются состояниями «LR (0)», потому что они используют опережающий просмотр k = 0, то есть без опережения. Единственная проверка входных символов происходит, когда символ сдвигается внутрь. Проверка опережающих просмотров для сокращений выполняется отдельно таблицей синтаксического анализа, а не самими перечисленными состояниями.
Таблица синтаксического анализа описывает все возможные состояния LR (0) и их переходы. Они образуют конечный автомат (FSM). FSM - это простой механизм для разбора простых невложенных языков без использования стека. В этом приложении LR модифицированный «язык ввода» конечного автомата имеет как терминальные, так и нетерминальные символы и охватывает любой частично проанализированный снимок стека полного анализа LR.
Вызов шага 5 примера шагов синтаксического анализа:
| . шаг | синтаксический анализ стека. состояние символ состояние... | Посмотрите. Впереди | . Не просканированные |
|---|---|---|---|
| 5 | 0Продукты 4*5int 8 | + | 1 |
Стек синтаксического анализа показывает серию переходов состояний от начального состояния 0 до состояния 4, а затем до 5 и текущего состояния 8. Символы на стек синтаксического анализа - это символы сдвига или перехода для этих переходов. Другой способ увидеть это - то, что конечный автомат может сканировать поток «Products * int + 1» (без использования еще одного стека) и находить крайнюю левую полную фразу, которая должна быть сокращена следующей. И это действительно его работа!
Как может простой автомат сделать это, если исходный неанализируемый язык имеет вложенность и рекурсию и определенно требует анализатора со стеком? Хитрость в том, что все, что находится слева от вершины стека, уже полностью уменьшено. Это устраняет все петли и вложенность этих фраз. FSM может игнорировать все старые начала фраз и отслеживать только самые новые фразы, которые могут быть завершены следующей. В теории LR это неясное название - «жизнеспособный префикс».
Состояния и переходы предоставляют всю необходимую информацию для действий сдвига и действий перехода таблицы синтаксического анализа. Генератору также необходимо вычислить ожидаемые наборы опережающих вычислений для каждого действия сокращения.
В синтаксических анализаторах SLR эти опережающие наборы определяются непосредственно из грамматики, без учета отдельных состояний и переходов. Для каждого нетерминального S генератор SLR вырабатывает Follows (S), набор всех терминальных символов, которые могут сразу следовать за некоторым вхождением S. В таблице синтаксического анализа каждое сокращение до S использует Follow (S) в качестве своего LR (1) опережающий набор. Такие последующие наборы также используются генераторами нисходящих синтаксических анализаторов LL. Грамматика, которая не имеет конфликтов сдвига / уменьшения или уменьшения / уменьшения при использовании наборов Follow, называется грамматикой SLR.
Парсеры LALR имеют те же состояния, что и парсеры SLR, но используют более сложный, более точный способ определения минимально необходимых предвидений сокращения для каждого отдельного состояния. В зависимости от деталей грамматики он может оказаться таким же, как набор Follow, вычисляемый генераторами парсеров SLR, или может оказаться подмножеством опережающих просмотров SLR. Некоторые грамматики подходят для генераторов парсеров LALR, но не подходят для генераторов парсеров SLR. Это происходит, когда грамматика имеет ложные конфликты сдвига / уменьшения или уменьшения / уменьшения с использованием наборов Follow, но не конфликтует при использовании точных наборов, вычисленных генератором LALR. Тогда грамматика называется LALR (1), но не SLR.
Анализатор SLR или LALR избегает дублирования состояний. Но в такой минимизации нет необходимости, и иногда она может создавать ненужные конфликты опережающего просмотра. Канонические парсеры LR используют дублированные (или «разделенные») состояния, чтобы лучше запоминать левый и правый контекст использования нетерминала. Каждое вхождение символа S в грамматике можно обрабатывать независимо с его собственным набором опережающего просмотра, чтобы помочь разрешить конфликты сокращения. Это обрабатывает еще несколько грамматик. К сожалению, это значительно увеличивает размер таблиц синтаксического анализа, если выполняется для всех частей грамматики. Это разделение состояний также может быть выполнено вручную и выборочно с помощью любого анализатора SLR или LALR путем создания двух или более именованных копий некоторых нетерминалов. Грамматика, которая является бесконфликтной для канонического генератора LR, но имеет конфликты в генераторе LALR, называется LR (1), но не LALR (1) и не SLR.
Парсеры SLR, LALR и канонические LR выполняют точно такой же сдвиг и сокращают количество решений, если входной поток является правильным языком. Когда вход содержит синтаксическую ошибку, синтаксический анализатор LALR может выполнить некоторые дополнительные (безвредные) сокращения перед обнаружением ошибки, чем канонический синтаксический анализатор LR.А парсер SLR может даже больше. Это происходит потому, что парсеры SLR и LALR используют широкое приближение к истинным, минимальным опережающим символам для этого конкретного состояния.
Парсеры LR могут генерировать несколько полезных сообщений об ошибках для первой синтаксической ошибки в программе, просто перечисляя все ошибки терминальные символы, которые могли появиться рядом, вместо неожиданного плохого просмотра вперед символ. Но это не помогает синтаксическому анализатору понять, как анализировать оставшуюся часть входной программы для поиска дальнейших ошибок независимых. Если синтаксический анализатор плохо восстанавливается после первой ошибки, он, скорее всего, неправильно проанализирует все остальное и создаст каскад бесполезных ложных сообщений об ошибках.
В генераторах парсеров yacc и bison у парсера есть специальный механизм, позволяющий использовать от текущего оператора, отбросить некоторые проанализированные фразы и опережающие токены, окружающие ошибку, и повторно синхронизировать анализ в некоторых надежный разделитель на уровня операторов, например точка с запятой или фигурные скобки. Это часто позволяет синтаксическому анализатору и компилятору просматривать остальную часть программы.
Многие синтаксические ошибки кодирования - это простые опечатки или пропуски тривиального символа. Некоторые парсеры LR пытаются обнаружить и автоматически исправить эти распространенные случаи. Анализатор перечисляет все возможные вставки, удаления или замены одного символа в точке ошибки. Компилятор выполняет пробный синтаксический анализ каждого изменения, чтобы убедиться, что все работает нормально. (Для этого требуется возврат к снимкам стека синтаксического анализа и входного потока, которые обычно не требуются синтаксическому анализатору.) Выбрано лучшее восстановление. Это дает очень полезное сообщение об ошибке и хорошо синхронизирует синтаксический анализ. Однако исправление недостаточно надежно, чтобы навсегда изменить входной файл. Исправление синтаксических ошибок проще всего выполнять последовательно в парсерах (например, LR), которые имеют таблицы синтаксического анализа и явный стек данных.
Генератор парсера LR решает, что должно происходить для каждой комбинации состояния парсера и символа опережающего просмотра. Эти решения обычно превращаются в таблицы данных только для чтения, которые запускают общий цикл синтаксического анализатора, который не зависит от грамматики и состояния. Но есть и другие способы превратить эти решения в активный синтаксический анализатор.
Некоторые генераторы парсеров LR создают отдельный специализированный программный код для каждого состояния, а не таблицу синтаксического анализа. Эти парсеры могут работать в несколько раз быстрее, чем стандартный цикл парсеров в парсерах, управляемых таблицами. Самые быстрые парсеры используют сгенерированный код ассемблера.
В варианте рекурсивного восходящего парсера явная структура стека синтаксического анализа также заменяется неявным стеком, используемым вызовами подпрограмм. Редукции завершают несколько уровней вызовов подпрограмм, что для большинства языков неуклюже. Таким образом, рекурсивные парсеры восходящего типа обычно медленнее, менее очевидны и их труднее модифицировать вручную, чем парсеры рекурсивного спуска.
Другой вариант заменяет таблицу синтаксического анализа правилами сопоставления с образцом в непроцедурных языках, таких как Prolog.
GLR Обобщенные анализаторы LR используют восходящие методы LR для поиска всех возможных синтаксических анализов входного текста, а не только одного правильного синтаксического анализа. Это важно для неоднозначных грамматик, например, используемых в человеческих языках. Множественные допустимые деревья синтаксического анализа вычисляются одновременно, без возврата. GLR иногда бывает полезен для компьютерных языков, которые нелегко описать бесконфликтной грамматикой LALR (1).
LCАнализаторы левого угла используют восходящие методы LR для распознавания левого конца альтернативных правил грамматики. Когда альтернативы были сужены до единственного возможного правила, анализатор затем переключается на нисходящие методы LL (1) для синтаксического анализа остальной части этого правила. Анализаторы LC имеют меньшие таблицы синтаксического анализа, чем анализаторы LALR, и лучшую диагностику ошибок. Широко используемых генераторов для детерминированных LC-анализаторов не существует. Анализаторы LC с множественным синтаксическим анализом полезны для человеческих языков с очень большими грамматиками.
Парсеры LR были изобретены Дональдом Кнутом в 1965 году как эффективное обобщение парсеров приоритета. Кнут доказал, что синтаксические анализаторы LR были наиболее универсальными из возможных, которые все равно были бы эффективны в худших случаях.
Другими словами, если язык был достаточно разумным, чтобы позволить эффективный однопроходный синтаксический анализатор, он мог быть описан грамматикой LR (k). И эту грамматику всегда можно было механически преобразовать в эквивалентную (но более крупную) грамматику LR (1). Таким образом, метод синтаксического анализа LR (1) был теоретически достаточно мощным, чтобы работать с любым разумным языком. На практике естественные грамматики для многих языков программирования близки к LR (1).
Канонические синтаксические анализаторы LR, описанные Кнутом, имели слишком много состояний и очень большие таблицы синтаксического анализа, которые были непрактично большими для ограниченной памяти компьютеры той эпохи. Разбор LR стал практичным, когда были изобретены парсеры SLR и LALR с гораздо меньшим количеством характеристик.
Для получения полной информации о теории LR и о том, как парсеры LR выводятся из грамматик, см. Теорию синтаксического анализа, перевода и компиляции, том 1 (Ахо и Уллман).
Парсеры Эрли применять методы и нотацию • LR-анализаторов к задаче генерации всех синтаксических анализов для неоднозначных грамматик, таких как человеческие языки.
В то время как грамматики LR (k) имеют одинаковую порождающую способность для всех k≥1, случай грамматик LR (0) немного отличается. Говорят, что язык L обладает своим префикса, если ни одно в L не является слово собственное префиксом другое слово в L.Язык L имеет LR (0) грамматику тогда и только тогда, когда L детерминированный контекстно -свободный язык со своим префикса. Как следствие, язык L является детерминированным языком контекстно-свободным, когда L $ имеет LR (0) грамматику, где «$» не является символом L в пример алфавита.
 Анализ 1 + 1 снизу вверх
Анализ 1 + 1 снизу вверх В этом анализе LR используется следующая небольшая грамматика с символом цели E:
для анализа следующий ввод:
Две таблицы синтаксического анализа LR (0) для этой грамматики выглядят следующим образом:
| состояние | действие | goto | |||||
| * | + | 0 | 1 | $ | E | B | |
| 0 | s1 | s2 | 3 | 4 | |||
| 1 | r4 | r4 | r4 | r4 | r4 | ||
| 2 | r5 | r5 | r5 | r5 | r5 | ||
| 3 | s5 | s6 | acc | ||||
| 4 | r3 | r3 | r3 | r3 | r3 | ||
| 5 | s1 | s2 | 7 | ||||
| 6 | s1 | s2 | 8 | ||||
| 7 | r1 | r1 | r1 | r1 | r1 | ||
| 8 | r2 | r2 | r2 | r2 | r2 | ||
Таблица индексируется состоянием оператора и терминала (включая специальный терминал $, который указывает конец входного потока) и содержит три типа действий:
Таблица goto индекс состоянием синтаксического анализатора и нетерминалом и просто указывает, каким будет следующее состояние синтаксического анализатора, если он признал некий нетерминал. Эта таблица важна для определения следующего состояния после сокращения. После следующего сокращения путем поиска записи таблицы перехода для вершины стека (т. Е. Текущего состояния) и LHS сокращенного (т. Е. Нетерминального).
В таблице ниже показан каждый этап процесса. Здесь состояние относится к элементу наверху стека (самый правый элемент), следующее действие указано на приведенную выше таблицу действий. К входной строке добавляется символ $, обозначающий конец потока.
| Состояние | Входной поток | Выходной поток | Стек | Следующее действие |
|---|---|---|---|---|
| 0 | 1 + 1 $ | [0] | Shift 2 | |
| 2 | + 1 $ | [0,2] | Уменьшить 5 | |
| 4 | + 1 $ | 5 | [0,4] | Уменьшить 3 |
| 3 | + 1 $ | 5,3 | [0,3] | Сдвиг 6 |
| 6 | 1 $ | 5,3 | [0,3,6] | Сдвиг 2 |
| 2 | $ | 5,3 | [0,3,6,2] | Уменьшить 5 |
| 8 | $ | 5,3,5 | [0,3,6,8] | Уменьшить 2 |
| 3 | $ | 5,3,5,2 | [0,3] | Принять |
Анализатор начинает со стека, содержащего только начальное состояние ('0'):
Первым символом из входной строки, который видит анализатор, «1». Чтобы найти следующее действие (ошибка сдвиг, уменьшение, принятие или действие), таблица действий индексируется текущим состоянием («текущее состояние» - это то, что находится наверху стека), в данном случае равно 0, и текущий входной символ, равный «1». Таблица действий определяет переход в состояние 2, и поэтому состояние 2 помещается в стек (опять же, вся информация о состоянии находится в стеке, поэтому «переход в состояние 2» соответствует помещению 2 в стек). Результирующий стек равен
, где верх стека равен 2. Для пояснения показан символ (например, '1', B), который вызвал переход в следующее состояние, хотя строго, это не часть стека.
В состоянии 2 таблицы действий говорит о сокращении с помощью правил грамматики 5 (независимо от того, какой терминал анализатор видит во входном потоке), что означает, что анализатор только что распознал правую часть правил 5 В этом случае синтаксический анализатор записывает 5 в выходной поток, извлекает одно состояние из стека (поскольку часть правил имеет один символ) и помещает в стек состояние из состояния в результате перехода для состояния 0 и B, то есть 4. В результате получается стек:
в состоянии 4 таблица действий говорит, что синтаксический анализатор должен выполнить сокращение согласно правилу 3. Таким образом, он записывает 3 в выходной поток, выталкивает одно состояние из стек, и находит новое состояние в совместном переходе для состояния 0 и E, которое является состоянием 3. Результирующий стек:
Следующий терминал, который видит синтаксический анализатор, - это '+', и в соответствии с таблицами действий он должен перейди те в состоянии 6:
Полученный стек можно интерпретировать как историю конечного автомата, который только что прочитал нетерминал E с последующим знаком "+". Таблица переходов этого автомата определяет действия сдвига в таблице действий и действиями перехода в таблицу перехода.
Следующий терминал теперь равенство «1», и это означает, что синтаксический анализатор сдвиг и переходит в состояние 2:
Так же, как предыдущая '1' эта сокращается до B, давая следующий стек:
соответствует списку состояний конечного автомата, который прочитал нетерминал E, за которым следует '+' а нетерминальный B. В состоянии 8 синтаксический анализатор всегда сокращение по правилам 2. Три верхних состояния в стеке соответствуют 3 символам в правой части правила 2. На этот раз мы выталкиваем 3 символа из стек (поскольку правая часть правила имеет 3 символа) и ищет состояние перехода для E и 0, таким образом, помещая состояние 3 обратно в стек
Наконец, синтаксический анализатор считывает '$' (конец ввода символа) из входного потока, что означает, что в соответствии с таблицами действий (текущее состояние - 3) синтаксический анализатор принимает входную строку. Правила, которые будут записаны в выходной поток, будут [5, 3, 5, 2], что действительно является крайним правым производным «1 + 1» в обратном порядке.
Создание этих таблиц анализа основано на понятии элементов LR (0) (здесь просто называемых элементов), которые - это правила грамматики, в где-то справа добавляется специальная точка. Например, правилу E → E + B соответствуют следующие четыре элемента:
Правила формы A → ε имеют только один элемент A → •. Элемент E → E • + B, например, указывает, что синтаксический анализатор распознал строки, соответствующий E во входном потоке, и теперь ожидает прочитать '+', за соответствующую другую строку, соответствующую B.
Обычно невозможно охарактеризовать состояние анализатора с помощью элемента, потому что он может заранее не знать, какое правило будет использовать для сокращения. Например, если существует также правило E → E * B, то элементы E → E • + B и E → E • * B будут работать после строки, формы E прочитано. Поэтому состояние парсера удобно описать набором элементов, в данном случае набором {E → E • + B, E → E • * B}.
Элемент с точкой перед нетерминалом, например E → E + • B, указывает, что синтаксический анализатор ожидает разобрать нетерминал B. Чтобы обеспечить, что набор элементов содержит все возможные правила, которые синтаксический анализатор может выполнять в процессе синтаксического анализа, он должен включать все элементы, описывающие, как будет анализироваться сам B. Это означает, что если существуют такие правила, как B → 1 и B → 0, то набор элементов также должен включенные элементы B → • 1 и B → • 0. В целом это можно сформулировать следующим образом:
Таким образом, любой набор элементов может быть расширен путем рекурсивного добавления всех соответствующих элементов, пока не будут учтены все нетерминалы, соответствующие предшествующие точки. Минимальное расширение называется закрытием набора и записывается как clos (I), где I - набор элементов. Именно эти закрытые наборы элементов принимаются в качестве состояния анализатора, хотя в таблицах включены только те, которые достижимы из начального состояния.
Перед определением перехода между различными состояниями грамматика дополнительных дополнительных правилом
, где S - новый символ запуска и E старый символ запуска. Парсер будет использовать это правило для сокращения тогда, когда он принял всю входную инструкцию.
В этом примере та же грамматика, что и выше, дополнена следующим образом:
Это для этого будет определена расширенная грамматика, которую задают элементы и переходы между ними.
Первый шаг построения таблиц в переходах между закрытыми наборами элементов. Эти переходы будут определяться так, как если бы мы рассматривали конечный автомат, который может читать как терминалы, так и нетерминалы. Начальным состоянием этого автомата всегда является закрытие первого элемента добавленного правила: S → • E:
Значок жирный шрифт "+"Перед элементами указывают элементы, которые были добавлены для закрытия (не путать с математическим оператором '+', который является терминалом). Исходные элементы" + "называются ядром набора элементов.
начало с начального состояния (S0), теперь все состояния, которые могут быть достигнуты из этого состояния. Возможные переходы для набора могут найти следующие элементы за точками; в случае набора элементов 0 этими символами являются терминалы '0' и '1' и нетерминалы E и B. символ 
Для терминала '0' (т.е. где x = '0') это приводит к:
и для терминала '1' (т.е. где x = '1') это приводит к:
и для нетерминала E (т.е. где x = E) это приводит к:
и для нетерминала B (т.е. где x = B) это приводит в:
Замыкание не пере новые элементы во всех случаях - в новых наборах выше, например, нет нетерминалов после точки.
Вышеуказанная процедура продолжается до тех пор, пока не будут найдены новые наборы элементов. Для набора элементов 1, 2 и 4 не будет никаких переходов, поскольку точка не находится перед каким-либо символом. Однако для набора элементов 3 у нас есть точки перед клеммами «*» и «+». Для символов 
и для 
Теперь начинается третья итерация.
Для набора элементов 5 необходимо учитывать терминалы «0» и «1» и нетерминал B, но результирующие закрытые наборы элементов равны уже найденным наборам элементов 1 и 2, соответственно. Для нетерминала B переход идет к:
Для набора элементов 6 необходимо клеммы '0' и '1' и нетерминал B, но как и раньше, результирующие наборы элементов для терминалов равны уже найденным наборам элементов 1 и 2. Для нетерминала B переход идет к:
Эти последние наборы элементов 7 и 8 не имеют символов, кроме точек, поэтому новые наборы элементов больше не добавляются, процедура создания элементов завершена. Конечный автомат с наборами элементов в качестве состояния показано ниже.
Таблица переходов для автомата теперь выглядит следующим образом:
| Набор элементов | * | + | 0 | 1 | E | B |
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | ||
| 1 | ||||||
| 2 | ||||||
| 3 | 5 | 6 | ||||
| 4 | ||||||
| 5 | 1 | 2 | 7 | |||
| 6 | 1 | 2 | 8 | |||
| 7 | ||||||
| 8 |
Из этой таблицы и найденных наборов элементов, действие и переход таблицы строятся следующим образом:
Может убедиться, что это действительно приводит к действию и таблице перехода, которые были представлены ранее.
Только шаг 4 вышеупомянутой процедуры действий сокращения, поэтому все действия сокращения должны занимать всю строку таблицы, вызывая сокращение происходить независимо от следующего символа во входном потоке. Вот почему это таблицы синтаксического анализа LR (0): они не выполняют никакого предварительного просмотра (то есть они просматривают нулевые символы), прежде чем решить, какое сокращение выполнить. Грамматика, которая требует упреждения для устранения неоднозначности сокращений, потребует строки таблицы синтаксического анализа, содержащей различные действия сокращения в разных столбцах, а описанная выше процедура не способна создавать такие строки.
Уточнения к процедуре построения таблицы LR (0) (например, SLR и LALR ) могут создавать действия сокращения, которые не занимают целые ряды. Следовательно, они способны анализировать больше грамматик, чем парсеры LR (0).
Автомат сконструирован таким образом, что гарантированно будет детерминированным. Однако, когда действия сокращения добавляются в таблицу действий, может случиться так, что одна и та же ячейка будет заполнена действием уменьшения и действием сдвига (конфликт сдвига-уменьшения) или двумя разными действиями уменьшения (конфликт уменьшения-уменьшения). Однако можно показать, что когда это происходит, грамматика не является грамматикой LR (0). Классическим реальным примером конфликта сдвиг-уменьшение является проблема dangling else.
Небольшой пример грамматики, отличной от LR (0), с конфликтом сдвиг-сокращение:
Один из найденных наборов элементов:
Там представляет собой конфликт сдвига-уменьшения в этом наборе элементов: при построении таблицы действий в соответствии с приведенными выше правилами ячейка для [набор элементов 1, терминал '1'] содержит s1 (переход в состояние 1) и r2 (сокращение с помощью правила грамматики 2).
Небольшой пример грамматики, отличной от LR (0), с конфликтом сокращения-уменьшения:
В этом случае получается следующий набор элементов:
В этом наборе элементов существует конфликт уменьшения-уменьшения, поскольку в ячейках в таблице действий для этого набора элементов будет действие уменьшения для правила 3 и одно для правила 4.
Оба приведенных выше примера могут быть решены путем разрешения синтаксическому анализатору использовать следующий набор (см. LL-синтаксический анализатор ) нетерминала A, чтобы решить, будет ли он использовать одно из правил As для сокращения; он будет использовать правило A → w для сокращения, только если следующий символ во входном потоке находится в следующем наборе A. Это решение приводит к так называемым Простым анализаторам LR.