
Войти
Нормализация базы данных - это процесс структурирования реляционной базы данных в соответствие серии так называемых нормальных форм, чтобы уменьшить избыточность данных и улучшить целостность данных. Впервые он был предложен Эдгаром Ф. Коддом как часть его реляционной модели.
Нормализация влечет за собой организацию столбцов (атрибутов) и таблиц ( отношений) базы данных, чтобы гарантировать, что их зависимости должным образом обеспечиваются ограничениями целостности базы данных. Это достигается путем применения некоторых формальных правил либо путем синтеза (создание нового проекта базы данных), либо декомпозиции (улучшения существующего проекта базы данных).
Основная цель первой нормальной формы, определенной Коддом в 1970 году, заключалась в том, чтобы позволить данным быть запрашиваются и обрабатываются с использованием «универсального подъязыка данных», основанного на логике первого порядка. (SQL является примером такого подъязыка данных, хотя Кодд считал его серьезно несовершенным.)
Цели нормализации за пределами 1NF (первая нормальная форма) были сформулированы следующим образом от Кодда:
 Аномалия обновления . Сотрудник 519 показан как имеющий разные адреса в разных записях.
Аномалия обновления . Сотрудник 519 показан как имеющий разные адреса в разных записях.  Аномалия вставки . Пока новому преподавателю, доктору Ньюсому, не будет поручено вести хотя бы один курс, его или ее данные не могут быть записаны.
Аномалия вставки . Пока новому преподавателю, доктору Ньюсому, не будет поручено вести хотя бы один курс, его или ее данные не могут быть записаны. 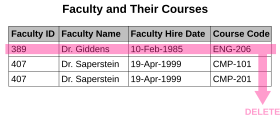 A аномалия удаления . Вся информация о докторе Гидденсе теряется, если он или она временно перестают назначаться на какие-либо курсы.
A аномалия удаления . Вся информация о докторе Гидденсе теряется, если он или она временно перестают назначаться на какие-либо курсы. Когда делается попытка изменить (обновить, вставить или удалить) связь, возникают следующие нежелательные побочные эффекты могут возникнуть в отношениях, которые не были достаточно нормализованы:
Полностью нормализованная база данных позволяет расширять ее структуру для размещения новых типов данных без значительного изменения существующей структуры. В результате это минимально влияет на приложения, взаимодействующие с базой данных.
Нормализованные отношения и отношения между одним нормализованным отношением и другим отражают концепции реального мира и их взаимосвязи.
Запрос и обработка данных в структуре данных, которая не нормализована, например, следующее не-1NF представление транзакций по кредитным картам клиентов, сопряжено с большей сложностью, чем это действительно необходимо:
| Заказчик | Заказчик. ID | Транзакции | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Авраам | 1 |
| ||||||||||||
| Исаак | 2 |
| ||||||||||||
| Джейкоб | 3 |
|
. Каждому покупателю соответствует «повторяющаяся группа» транзакций. Следовательно, автоматическая оценка любого запроса, относящегося к транзакциям клиентов, в целом будет включать в себя два этапа:
Например, чтобы узнать денежную сумму всех транзакций, которые произошли в октябре 2003 года для всех клиентов, системе необходимо знать, что она должна сначала распаковать Группу транзакций для каждого клиента, затем суммируйте Суммы всех полученных таким образом транзакций, когда Дата транзакции приходится на октябрь 2003 года.
Одним из важных выводов Кодда было то, что структурная сложность может быть уменьшена. Уменьшение структурной сложности дает пользователям, приложениям и СУБД больше возможностей и гибкости для формулирования и оценки запросов. Более нормализованный эквивалент приведенной выше структуры может выглядеть так:
| Customer | Cust. ID |
|---|---|
| Авраам | 1 |
| Исаак | 2 |
| Иаков | 3 |
| Каст. ID | Тр. ID | Дата | Сумма |
|---|---|---|---|
| 1 | 12890 | 14-Oct-2003 | −87 |
| 1 | 12904 | 15- Октябрь 2003 г. | −50 |
| 2 | 12898 | 14- окт.2003 | −21 |
| 3 | 12907 | 15 октября 2003 г. | −18 |
| 3 | 14920 | 20- ноябрь 2003 | −70 |
| 3 | 15003 | 27 ноября 2003 года | −60 |
В измененной структуре первичный ключ равен {Cust. ID} в первом отношении, {Cust. ID, Тр. ID} во втором отношении.
Теперь каждая строка представляет отдельную транзакцию по кредитной карте, и СУБД может получить интересующий ответ, просто найдя все строки с датой, приходящейся на октябрь, и суммируя их суммы. Структура данных размещает все значения на равных основаниях, открывая каждое из них напрямую СУБД, поэтому каждое потенциально может напрямую участвовать в запросах; тогда как в предыдущей ситуации некоторые значения были встроены в структуры нижнего уровня, с которыми нужно было обрабатывать специально. Соответственно, нормализованный дизайн подходит для обработки запросов общего назначения, а ненормализованный - нет. Нормализованная версия также позволяет пользователю изменить имя клиента в одном месте и защищает от ошибок, которые возникают, если имя клиента неправильно написано в некоторых записях.
Кодд представил концепцию нормализации и то, что сейчас известно как первая нормальная форма (1NF) в 1970 году. Кодд продолжил определение вторая нормальная форма (2NF) и третья нормальная форма (3NF) в 1971 году, а Кодд и Раймонд Ф. Бойс определили нормальную форму Бойса-Кодда (BCNF) в 1974 году.
Неформально отношение реляционной базы данных часто описывается как «нормализованное», если оно соответствует третьей нормальной форме. Большинство отношений 3NF не содержат аномалий вставки, обновления и удаления.
Нормальные формы (от наименее нормализованной до наиболее нормализованной):
| UNF. (1970) | 1NF. (1970) | 2NF. (1971) | 3NF. (1971) | EKNF. (1982) | BCNF. (1974) | 4NF. (1977) | . (2012) | 5NF. (1979) | DKNF. (1981) | 6NF. (2003) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Первичный ключ (без повторяющихся кортежей ) | |||||||||||
| Без повторяющихся групп | |||||||||||
| Атомарные столбцы (ячейки имеют одно значение) | |||||||||||
| Каждая нетривиальная функциональная зависимость либо не начинается с правильного подмножества ключа-кандидата, либо заканчивается простым атрибут (частичные функциональные зависимости не примитивных e атрибутов ключей-кандидатов) | |||||||||||
| Каждая нетривиальная функциональная зависимость начинается с суперключа или заканчивается первичным атрибутом (нет транзитивных функциональных зависимостей непервичных атрибутов для ключей-кандидатов) | |||||||||||
| Каждая нетривиальная функциональная зависимость либо начинается с суперключа, либо заканчивается элементарным первичным атрибутом | Н / Д | ||||||||||
| Каждая нетривиальная функциональная зависимость начинается с суперключа | Н / Д | ||||||||||
| Каждая нетривиальная многозначная зависимость начинается с суперключа | Н / Д | ||||||||||
| Каждая зависимость соединения имеет компонент суперключа | Н / Д | ||||||||||
| Каждая зависимость соединения имеет только компоненты суперключа | Н / Д | ||||||||||
| Каждое ограничение является следствием ограничений домена и ключевых ограничений | Н / Д | ||||||||||
| Каждая зависимость соединения тривиальна |
Нормализация - это метод проектирования базы данных, который используется для проектирования таблицы реляционной базы данных до более высокой нормальной формы. Процесс является прогрессивным, и более высокий уровень нормализации базы данных не может быть достигнут, если не будут удовлетворены предыдущие уровни.
Это означает, что наличие данных в ненормализованной форме (наименее нормализованная) и стремясь достичь наивысшего уровня нормализации, первым шагом будет обеспечение соответствия первой нормальной форме, вторым шагом будет обеспечение выполнения второй нормальной формы и т. д. в указанном выше порядке до тех пор, пока данные не будут соответствовать шестой нормальной форме.
Однако стоит отметить, что нормальные формы за пределами 4NF представляют в основном академический интерес, поскольку проблемы, которые они существуют, решаются редко появляются на практике.
Обратите внимание, что данные в следующем примере были намеренно созданы, чтобы противоречить большинству обычных форм. В реальной жизни вполне возможно пропустить некоторые шаги нормализации, потому что таблица не содержит ничего, что противоречило бы заданной нормальной форме. Также часто бывает, что исправление нарушения одной нормальной формы также устраняет нарушение более высокой нормальной формы в процессе. Также была выбрана одна таблица для нормализации на каждом шаге, а это означает, что в конце этого примера процесса все еще могут быть некоторые таблицы, не удовлетворяющие высшей нормальной форме.
Пусть таблица базы данных имеет следующую структуру:
| Заголовок | Автор | Национальность органа | Формат | Цена | Тема | Страницы | Толщина | Издатель | Страна издателя | Тип публикации | ID жанра | Название жанра |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Чад Рассел | Американский | Твердый переплет | 49,99 | MySQL, База данных, Дизайн | 520 | Толстый | Apress | США | Электронная книга | 1 | Учебник |
В этом примере мы предполагаем, что у каждой книги есть только один автор.
Чтобы удовлетворить 1NF, значения в каждом столбце таблицы должны быть атомарными. В исходной таблице Subject содержит набор значений темы, что означает, что он не соответствует.
Одним из способов достижения 1NF было бы разделение дубликатов на несколько столбцов с помощью повторяющихся групп Тема :
| Название | Формат | Автор | Национальность автора | Цена | Тема 1 | Тема 2 | Тема 3 | Страницы | Толщина | Издатель | Страна издателя | Идентификатор жанра | Название жанра |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Твердый переплет | Чад Рассел | Американский | 49,99 | MySQL | База данных | Дизайн | 520 | Толстый | Apress | USA | 1 | Учебник |
Хотя теперь таблица формально соответствует 1NF (атомарная), проблема с этим решением очевидна - если в книге более трех предметов, она нельзя добавить в базу данных без изменения ее структуры.
Чтобы решить проблему более элегантным способом, необходимо идентифицировать сущности, представленные в таблице, и разделять их на соответствующие таблицы. В этом случае это приведет к таблицам Книга, Тема и Издатель :
| Название | Формат | Автор | Автор Национальность | Цена | Страницы | Толщина | Идентификатор жанра | Название жанра | Идентификатор издателя |
|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Твердый переплет | Чад Рассел | Американец | 49,99 | 520 | Толстый | 1 | Учебник | 1 |
|
|
Простое разделение исходных данных на несколько таблиц приведет к разрыву связи между данными. Это означает, что необходимо определить отношения между вновь введенными таблицами. Обратите внимание, что столбец «Идентификатор издателя» в таблице книги - это внешний ключ , реализующий связь многие-к-одному между книгой и издателем.
Книга может соответствовать многим предметам, так же как предмет может соответствовать многим книгам. Это означает, что также необходимо определить отношение многие-ко-многим, что достигается путем создания таблицы ссылок :
. |
Вместо одной таблицы в ненормализованной форме теперь есть 4 таблицы, соответствующие 1NF.
Таблица Книга имеет один ключ-кандидат (который, следовательно, является первичным ключом ), составной ключ {Заголовок, Формат} . Рассмотрим следующий фрагмент таблицы:
| Название | Формат | Автор | Автор Национальность | Цена | Страниц | Толщина | ID жанра | Название жанра | ID издателя |
|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Твердый переплет | Chad Russell | Американский | 49,99 | 520 | Толстый | 1 | Учебное пособие | 1 |
| Начало проектирования и оптимизации баз данных MySQL | Электронная книга | Чад Рассел | Американец | 22.34 | 520 | Толстый | 1 | Учебник | 1 |
| Реляционная модель для управления базами данных: версия 2 | Электронная книга | EFCodd | Британский | 13,88 | 538 | Толстый | 2 | Популярный science | 2 |
| Реляционная модель для управления базами данных: версия 2 | Мягкая обложка | EFCodd | Британский | 39,99 | 538 | Толстый | 2 | Научно-популярный | 2 |
Все атрибуты, которые не являются частью ключа кандидата, зависят от Заголовка, но Ly Цена также зависит от формата. Чтобы соответствовать 2NF и устранить дублирование, каждый атрибут, не являющийся ключом-кандидатом, должен зависеть от всего ключа-кандидата, а не только от его части.
Чтобы нормализовать эту таблицу, сделайте {Title} (простым) кандидатным ключом (первичным ключом) так, чтобы каждый атрибут не-кандидата-ключа зависел от всего кандидата-ключа, и удалите Price в отдельную таблицу, чтобы сохранить ее зависимость от формата:
|
|
Теперь таблица Book соответствует 2NF.
Нормальная форма элементарного ключа (EKNF) находится строго между 3NF и BCNF и мало обсуждается в литературе. Он призван «уловить основные качества как 3NF, так и BCNF», избегая при этом проблем обоих (а именно, что 3NF «слишком снисходительна», а BCNF «склонна к вычислительной сложности»). Поскольку он редко упоминается в литературе, он не включен в этот пример.
Предположим, что база данных принадлежит франшизе книжного ритейлера, у которого есть несколько франчайзи, которые владеют магазинами в разных местах. Поэтому продавец решил добавить таблицу, содержащую данные о наличии книг в разных местах:
| Идентификатор франчайзи | Заголовок | Местоположение |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | Калифорния |
| 1 | Начало проектирования и оптимизации базы данных MySQL | Флорида |
| 1 | Начало проектирования и оптимизации базы данных MySQL | Техас |
| 1 | Реляционная модель для управления базами данных: версия 2 | Калифорния |
| 1 | Реляционная модель для управления базами данных: версия 2 | Флорида |
| 1 | Реляционная модель для управления базами данных: версия 2 | Техас |
| 2 | Начало Разработка и оптимизация базы данных MySQL | Калифорния |
| 2 | Начало проектирования и оптимизации базы данных MySQL | Флорида |
| 2 | Начало проектирования и оптимизации базы данных MySQL | Техас |
| 2 | Реляционная модель для управления базами данных: версия 2 | Калифорния |
| 2 | Реляционная модель для управления базами данных: версия 2 | Флорида |
| 2 | Реляционная модель для управления базами данных: версия 2 | Техас |
| 3 | Начало проектирования и оптимизации баз данных MySQL | Техас |
Как эта структура таблицы состоит из составного первичного ключа , он не содержит никаких неключевых атрибутов и уже находится в BCNF (и, следовательно, также удовлетворяет всем предыдущим нормальным формам ). Однако, если мы предположим, что все доступные книги предлагаются в каждой области, мы можем заметить, что Title не привязан однозначно к определенному Location, и поэтому таблица не удовлетворяет 4NF.
Это означает, что для удовлетворения четвертой нормальной формы эту таблицу также необходимо разложить:
|
|
Итак, каждая запись однозначно идентифицируется с помощью суперключа, следовательно, 4NF удовлетворяется.
Предположим, франчайзи также могут заказывать книги из diff Текущие поставщики. Пусть отношение также подчиняется следующему ограничению:
| Идентификатор поставщика | Заголовок | Идентификатор франчайзи |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | 1 |
| 2 | Реляционная модель для управления базой данных: версия 2 | 2 |
| 3 | Изучение SQL | 3 |
Эта таблица находится в 4NF, но ID поставщика равен объединению его прогнозов: {{Supplier ID, Book}, {Book, Franchisee ID}, {Franchisee ID, Supplier ID }}. Ни один из компонентов этой зависимости соединения не является суперключом (единственный суперключ представляет собой весь заголовок), поэтому таблица не удовлетворяет требованиям и может быть дополнительно разложена:
|
|
|
Разложение обеспечивает соответствие.
Чтобы определить таблицу, не удовлетворяющую 5NF, обычно необходимо тщательно изучить данные. Предположим, что таблица из 4NF, пример с небольшими изменениями в данных, и давайте посмотрим, удовлетворяет ли она 5NF :
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | Калифорния |
| 1 | Изучение SQL | Калифорния |
| 1 | Реляционная модель для управления базами данных: версия 2 | Техас |
| 2 | Реляционная Модель для управления базой данных: версия 2 | Калифорния |
Если мы разложим эту таблицу, мы уменьшим избыточность и получим следующие две таблицы:
|
|
Что произойдет, если мы попытаемся объединить эти таблицы? Запрос вернет следующие данные:
| Идентификатор франчайзи | Название | Местоположение |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | Калифорния |
| 1 | Обучение SQL | Калифорния |
| 1 | Реляционная модель для управления базами данных: версия 2 | Калифорния |
| 1 | Реляционная модель для управления базами данных: версия 2 | Техас |
| 1 | Обучение SQL | Техас |
| 1 | Начало проектирования и оптимизации базы данных MySQL | Техас |
| 2 | Реляционная модель для управления базами данных: версия 2 | Калифорния |
Очевидно, JOIN возвращает на три строки больше, чем нужно - давайте попробуем добавить еще одну таблицу, чтобы прояснить связь. В итоге мы получаем три отдельные таблицы:.
|
|
|
Что теперь будет возвращать JOIN? Фактически невозможно объединить эти три таблицы. Это означает, что невозможно было разложить Франчайзи - Местоположение книги без потери данных, поэтому таблица уже удовлетворяет 5NF.
C.J. Дейт утверждал, что только база данных в 5NF действительно "нормализована".
Давайте взглянем на таблицу Book из предыдущих примеров и посмотрим, удовлетворяет нормальной форме Доменного ключа :
| Заголовок | Страницы | Толщина | Идентификатор жанра | Идентификатор издателя |
|---|---|---|---|---|
| Начало проектирования базы данных MySQL и Оптимизация | 520 | Толстый | 1 | 1 |
| Реляционная модель для управления базами данных: Версия 2 | 538 | Толстый | 2 | 2 |
| Изучение SQL | 338 | Slim | 1 | 3 |
| Поваренная книга SQL | 636 | Thick | 1 | 3 |
Логически Толщина определяется количеством страниц. Это означает, что это зависит от страниц, которые не являются ключевыми. Приведем пример соглашения, согласно которому книга до 350 страниц считается «тонкой», а книга более 350 страниц - «толстой».
Это соглашение технически является ограничением, но не является ни ограничением домена, ни ограничением ключа; поэтому мы не можем полагаться на ограничения домена и ключевые ограничения для сохранения целостности данных.
Другими словами - ничто не мешает нам поставить, например, «Толстый» для книги всего с 50 страницами - и это нарушает таблицу DKNF.
Чтобы решить эту проблему, мы можем создать таблица, содержащая перечисление, которое определяет Thickness и удаляет этот столбец из исходной таблицы:
|
|
Таким образом, нарушение целостности домена было устранено, и таблица находится в DKNF.
Простое и интуитивно понятное определение шестой нормальной формы состоит в том, что «таблица находится в 6NF, когда строка содержит первичный ключ, и не более одного другого атрибута ".
Это означает, например, что таблица Publisher, созданная при создании 1NF
| Publisher_ID | Имя | Страна |
|---|---|---|
| 1 | Apress | США |
необходимо дополнительно разложить на две таблицы:
|
|
Очевидным недостатком 6NF является большое количество таблиц, необходимых для представления информации об одном объекте. Если таблица в 5NF имеет один столбец первичного ключа и N атрибутов, для представления той же информации в 6NF потребуется N таблиц; обновления нескольких полей одной концептуальной записи потребуют обновления нескольких таблиц; а вставки и удаления аналогичным образом потребуют операций над несколькими таблицами. По этой причине в базах данных, предназначенных для обслуживания нужд онлайн-обработки транзакций, не следует использовать 6NF.
Однако в хранилищах данных, которые не допускают интерактивных обновлений и которые предназначены для быстрого запроса больших объемов данных, некоторые СУБД используют внутреннее представление 6NF, известное как Столбцовое хранилище данных. В ситуациях, когда количество уникальных значений столбца намного меньше количества строк в таблице, хранение, ориентированное на столбцы, позволяет значительно сэкономить пространство за счет сжатия данных. Столбцовое хранилище также позволяет быстро выполнять запросы диапазона (например, отображать все записи, в которых конкретный столбец находится между X и Y или меньше X.)
Однако во всех этих случаях разработчик базы данных не имеет выполнить нормализацию 6НФ вручную, создав отдельные таблицы. Некоторые СУБД, специализирующиеся на хранении данных, такие как Sybase IQ, по умолчанию используют столбчатое хранилище, но разработчик по-прежнему видит только одну таблицу с несколькими столбцами. Другие СУБД, такие как Microsoft SQL Server 2012 и более поздние версии, позволяют вам указать "индекс columnstore" для конкретной таблицы.