Метод агломеративной иерархической кластеризации
UPGMA (метод невзвешенной парной группы со средним арифметическим ) является простой агломеративный (восходящий) метод иерархической кластеризации. Этот метод обычно приписывается Sokal и Michener.
. Метод UPGMA аналогичен его взвешенному варианту, методу WPGMA.
Обратите внимание, что невзвешенный член указывает, что все расстояния вносят равный вклад в каждое вычисленное среднее значение, и не относится к математике, с помощью которой оно достигается. Таким образом, простое усреднение в WPGMA дает взвешенный результат, а пропорциональное усреднение в UPGMA дает невзвешенный результат (см. Рабочий пример).
Содержание
- 1 Алгоритм
- 2 Рабочий пример
- 2.1 Первый шаг
- 2.2 Второй этап
- 2.3 Третий этап
- 2.4 Заключительный этап
- 2.5 Дендрограмма UPGMA
- 2.6 Сравнение с другими связями
- 3 Использование
- 4 Сложность времени
- 5 См. Также
- 6 Ссылки
- 7 Внешние ссылки
Алгоритм
Алгоритм UPGMA строит корневое дерево (дендрограмма ), которое отражает структуру, представленную в попарной матрице сходства (или матрица несходства ). На каждом шаге ближайшие два кластера объединяются в кластер более высокого уровня. Расстояние между любыми двумя кластерами  и
и  , каждый размером (т. Е. мощность )
, каждый размером (т. Е. мощность )  и
и  , принимается как среднее всех расстояний
, принимается как среднее всех расстояний  между парами объектов
между парами объектов  в и
в и  в , то есть среднее расстояние между элементами каждого кластера:
в , то есть среднее расстояние между элементами каждого кластера:

Другими словами, на каждом шаге кластеризации обновленное расстояние между объединенными кластерами  и новый кластер
и новый кластер  дается пропорциональным усреднением
дается пропорциональным усреднением  и
и  расстояния:
расстояния:

Алгоритм UPGMA создает корневые дендрограммы и требует допущения о постоянной скорости - то есть, он принимает ультраметрическое дерево, в котором расстояния от корня до каждого конца ветви равны. Когда подсказки представляют собой молекулярные данные (например, ДНК, РНК и белок ), взятые одновременно, предположение ультраметричности становится эквивалентным для предположения о молекулярных часах.
Рабочий пример
Этот рабочий пример основан на JC69 матрице генетических расстояний, вычисленной на основе выравнивания последовательности 5S рибосомной РНК из пяти бактерий: Bacillus subtilis ( ), Bacillus stearothermophilus (
), Bacillus stearothermophilus ( ), Lactobacillus viridescens (
), Lactobacillus viridescens ( ), Acholeplasma modicum (
), Acholeplasma modicum ( ) и Micrococcus luteus (
) и Micrococcus luteus ( ).
).
Первый шаг
Предположим, что у нас есть пять элементов  и следующая матрица
и следующая матрица  попарных расстояний между ними:
попарных расстояний между ними:
| a | b | c | d | e |
|---|
| a | 0 | 17 | 21 | 31 | 23 |
|---|
| b | 17 | 0 | 30 | 34 | 21 |
|---|
| c | 21 | 30 | 0 | 28 | 39 |
|---|
| d | 31 | 34 | 28 | 0 | 43 |
|---|
| e | 23 | 21 | 39 | 43 | 0 |
|---|
В этом примере  - наименьшее значение , поэтому мы объединяем элементы и .
- наименьшее значение , поэтому мы объединяем элементы и .
- Оценка длины первой ветви
Пусть  обозначает узел, к которому и теперь подключены. Установка
обозначает узел, к которому и теперь подключены. Установка  гарантирует, что элементы и равноудалены из . Это соответствует ожиданиям гипотезы ультраметричности. Ветви, соединяющие и с тогда длина
гарантирует, что элементы и равноудалены из . Это соответствует ожиданиям гипотезы ультраметричности. Ветви, соединяющие и с тогда длина  (см. Окончательную дендрограмму)
(см. Окончательную дендрограмму)
- Первое обновление матрицы расстояний
Затем мы переходим к обновлению исходной матрицы расстояний в новую матрицу расстояний  (см. Ниже), размер уменьшен на одну строку и один столбец из-за кластеризации с . Значения, выделенные жирным шрифтом в , соответствуют новым расстояниям, вычисленным с помощью усреднения расстояний между каждым элементом первого кластера
(см. Ниже), размер уменьшен на одну строку и один столбец из-за кластеризации с . Значения, выделенные жирным шрифтом в , соответствуют новым расстояниям, вычисленным с помощью усреднения расстояний между каждым элементом первого кластера  и каждый из оставшихся элементов:
и каждый из оставшихся элементов:



Значения, выделенные курсивом в На обновление матрицы не влияет, поскольку они соответствуют расстояниям между элементами, не участвующими в первом кластере.
Второй шаг
Теперь мы повторяем три предыдущих шага, начиная с новой матрицы расстояний
| (a, b) | c | d | e |
|---|
| (a, b) | 0 | 25,5 | 32,5 | 22 |
|---|
| c | 25,5 | 0 | 28 | 39 |
|---|
| d | 32,5 | 28 | 0 | 43 |
|---|
| e | 22 | 39 | 43 | 0 |
|---|
Здесь  - наименьшее значение из , поэтому мы объединяем кластер и элемент .
- наименьшее значение из , поэтому мы объединяем кластер и элемент .
- Оценка длины второй ветви
Пусть  обозначает узел, к которому и теперь подключены. Из-за ограничения ультраметричности ветви, соединяющие или с и to равны и имеют следующую длину:
обозначает узел, к которому и теперь подключены. Из-за ограничения ультраметричности ветви, соединяющие или с и to равны и имеют следующую длину: 
Вычисляем недостающую длину ветви:  (см. окончательную дендрограмму)
(см. окончательную дендрограмму)
- Обновление матрицы второго расстояния
Затем мы переходим к обновлению в новую матрицу расстояний  (см. Ниже), уменьшенную на одну строку и один столбец из-за кластеризации с . Значения, выделенные жирным шрифтом в , соответствуют новым расстояниям, вычисленным с помощью пропорционального усреднения :
(см. Ниже), уменьшенную на одну строку и один столбец из-за кластеризации с . Значения, выделенные жирным шрифтом в , соответствуют новым расстояниям, вычисленным с помощью пропорционального усреднения :

Благодаря этому пропорциональному среднему, вычисление этого нового расстояния учитывает больший размер кластер (два элемента) по отношению к (один элемент). Аналогично:

Следовательно, пропорциональное усреднение дает равный вес к начальным расстояниям матрицы . Это причина того, почему метод невзвешен не по отношению к математической процедуре, а по отношению к начальным расстояниям.
Третий шаг
Мы снова повторяем три предыдущих шага, начиная с обновленной матрицы расстояний .
| ((a, b), e) | c | d |
|---|
| ((a, b), e) | 0 | 30 | 36 |
|---|
| c | 30 | 0 | 28 |
|---|
| d | 36 | 28 | 0 |
|---|
Здесь  - наименьшее значение , поэтому мы соединяем элементы и .
- наименьшее значение , поэтому мы соединяем элементы и .
- Оценка длины третьей ветви
Пусть  обозначает узел, к которому и теперь соединены. Ветви, соединяющие и с тогда длина
обозначает узел, к которому и теперь соединены. Ветви, соединяющие и с тогда длина  (см. Финальную дендрограмму)
(см. Финальную дендрограмму)
- Третье обновление матрицы расстояний
Необходимо обновить одну запись, учитывая, что два элемента и каждый имеет вклад  в среднее вычисление :
в среднее вычисление :

Заключительный шаг
Заключительная матрица  :
:
| ( (a, b), e) | (c, d) |
|---|
| ((a, b), e) | 0 | 33 |
|---|
| (c, d) | 33 | 0 |
|---|
Итак, мы объединить кластеры  и
и  .
.
Пусть  обозначает (корневой) узел, к которому и теперь соединены. Ветви, соединяющие и до тогда имеют длины:
обозначает (корневой) узел, к которому и теперь соединены. Ветви, соединяющие и до тогда имеют длины:

Вычисляем две оставшиеся длины ветвей:


Дендрограмма UPGMA
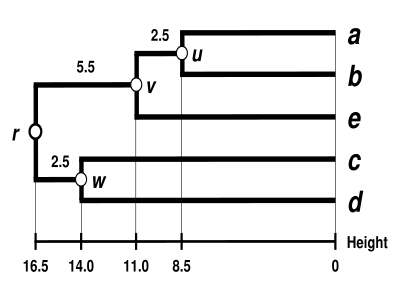
Дендрограмма завершена. Он ультраметрический, потому что все подсказки (от до ) находятся на одинаковом расстоянии от :

Следовательно, корень дендрограммы лежит на , самый глубокий узел.
Сравнение с другими связями
Альтернативные схемы связи включают кластеризацию одиночных связей, кластеризацию полной связи и кластеризацию средних связей WPGMA. Реализация другой связи - это просто вопрос использования другой формулы для расчета межкластерных расстояний на этапах обновления матрицы расстояний в вышеупомянутом алгоритме. Полная кластеризация по связям позволяет избежать недостатка альтернативного метода кластеризации с одной связью - так называемого явления сцепления, когда кластеры, сформированные с помощью кластеризации с одной связью, могут быть принудительно объединены из-за того, что отдельные элементы находятся близко друг к другу, даже если многие элементы в каждом кластеры могут быть очень далеки друг от друга. Полное сцепление имеет тенденцию находить компактные кластеры примерно равных диаметров.
Сравнение дендрограмм, полученных разными методами кластеризации из одной и той же матрицы расстояний. |  |  |  |
| Одинарная кластеризация. | Кластеризация с полной связью. | Средняя кластеризация связей: WPGMA. | Средняя кластеризация сцепления: UPGMA. |
Использует
- В экологии это один из самых популярных методов классификации единиц выборки (например, участков растительности) на основе их попарного сходства в соответствующих переменных дескриптора (таких как видовой состав). Например, его использовали для понимания трофического взаимодействия между морскими бактериями и простейшими.
- В биоинформатике UPGMA используется для создания фенетических деревья (фенограммы). Первоначально UPGMA был разработан для использования в исследованиях электрофореза белков, но в настоящее время наиболее часто используется для создания направляющих деревьев для более сложных алгоритмов. Этот алгоритм, например, используется в процедурах выравнивания последовательностей, поскольку он предлагает один порядок, в котором последовательности будут выравниваться. Действительно, направляющее дерево нацелено на группировку наиболее похожих последовательностей, независимо от их скорости эволюции или филогенетического сходства, и это как раз и является целью UPGMA
- В филогенетике UPGMA предполагает постоянную скорость эволюции (гипотеза молекулярных часов ) и что все последовательности были взяты в одно и то же время, и не является хорошо зарекомендовавшим себя методом вывода взаимосвязей, если это предположение не было проверено и оправдано для используемого набора данных. Обратите внимание, что даже в условиях «строгой синхронизации» последовательности, выбранные в разное время, не должны приводить к ультраметрическому дереву.
Временная сложность
Тривиальная реализация алгоритма для построения дерева UPGMA имеет  временная сложность, а использование кучи для каждого кластера, чтобы сохранить расстояние от другого кластера, сокращает его время до
временная сложность, а использование кучи для каждого кластера, чтобы сохранить расстояние от другого кластера, сокращает его время до  . Фионн Муртаг представил некоторые другие подходы для особых случаев, временной алгоритм
. Фионн Муртаг представил некоторые другие подходы для особых случаев, временной алгоритм  Дэя и Эдельсбруннера. для k-мерных данных, которые оптимальны
Дэя и Эдельсбруннера. для k-мерных данных, которые оптимальны  для постоянного k, а другой алгоритм для ограниченного ввода, когда «агломеративная стратегия удовлетворяет свойству сводимости».
для постоянного k, а другой алгоритм для ограниченного ввода, когда «агломеративная стратегия удовлетворяет свойству сводимости».
См. также
Ссылки
Внешние ссылки





