
Войти
В информатике используется топологическая сортировка или топологический порядок ориентированного графа - это линейный порядок его вершин, такой, что для каждого направленного ребра uv от вершины u до вершины v u стоит перед v в заказ. Например, вершины графа могут представлять задачи, которые должны быть выполнены, а ребра могут представлять ограничения, согласно которым одна задача должна быть выполнена раньше другой; в этом приложении топологический порядок - это просто допустимая последовательность для задач. Топологическое упорядочение возможно тогда и только тогда, когда граф не имеет направленных циклов, то есть если это ориентированный ациклический граф (DAG). Любой DAG имеет по крайней мере одно топологическое упорядочение, и известны алгоритмы для построения топологического упорядочения любого DAG за линейное время. Топологическая сортировка имеет множество приложений, особенно в задачах ранжирования, таких как набор дуг обратной связи.
Каноническое применение топологической сортировки - это планирование последовательности заданий или задач на основе их зависимостей. Задания представлены вершинами, и есть ребро от x до y, если задание x должно быть завершено до начала задания y (например, при стирке одежды стиральная машина должна закончить, прежде чем мы поместим одежду в сушилку). Затем топологическая сортировка задает порядок выполнения работ. Тесно родственное применение алгоритмов топологической сортировки было впервые изучено в начале 1960-х годов в контексте метода PERT для планирования в управлении проектами. В этом приложении вершины графа представляют вехи проекта, а ребра представляют задачи, которые необходимо выполнить между одним этапом и другим. Топологическая сортировка формирует основу алгоритмов линейного времени для поиска критического пути проекта, последовательности этапов и задач, которые контролируют продолжительность общего расписания проекта.
В информатике приложения этого типа возникают в планировании инструкций, упорядочивании вычисления ячеек формулы при пересчете значений формулы в электронных таблицах, логическом синтезе, определение порядка выполнения задач компиляции в make-файлах, сериализация данных и разрешение символьных зависимостей в компоновщиках. Он также используется, чтобы решить, в каком порядке загружать таблицы с внешними ключами в базы данных.
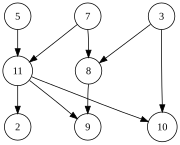 | График, показанный слева, имеет много допустимых топологических типов, включая:
|
Обычные алгоритмы топологической сортировки имеют время работы, линейное по количеству узлов плюс количество ребер, асимптотически
Один из этих алгоритмов, впервые описанный Каном (1962), работает, выбирая вершины в том же порядке, что и конечная топологическая сортировка. Сначала найдите список «начальных узлов», у которых нет входящих ребер, и вставьте их в набор S; хотя бы один такой узел должен существовать в непустом ациклическом графе. Затем:
L ← Пустой список, который будет содержать отсортированные элементы S ← Набор всех узлов без входящего ребра, в то время как S не пусто do удалить узел n из S добавить n к L для каждого узла m с ребром e от n до m do удалить ребро e из графа, если m не имеет других входящих ребер, затем вставьте m в S, если граф имеет ребра, затемверните ошибку (граф имеет хотя бы один цикл) elsereturn L (топологически отсортированный порядок)
Если график является DAG, решение будет содержаться в списке L ( решение не обязательно уникальное). В противном случае в графе должен быть хотя бы один цикл, поэтому топологическая сортировка невозможна.
Отражая неединственность результирующей сортировки, структура S может быть просто набором, очередью или стеком. В зависимости от порядка удаления узлов n из набора S создается другое решение. Вариант алгоритма Кана, который разрывает связи лексикографически, образует ключевой компонент алгоритма Коффмана – Грэма для параллельного планирования и рисования многоуровневого графа.
Альтернативный алгоритм топологической сортировки основан на поиске в глубину. Алгоритм проходит через каждый узел графа в произвольном порядке, инициируя поиск в глубину, который завершается, когда он попадает в любой узел, который уже был посещен с начала топологической сортировки или у узла нет исходящих ребер (т. Е. листовой узел):
L ← Пустой список, который будет содержать отсортированные узлы, в то время как существуют узлы без постоянной метки do выбрать немаркированный узел n посещение (n) функция визит (узел n) если n имеет постоянную метку, тогдаreturn ifn имеет временную метку, затем stop (не DAG) отметка n с временной отметкой для каждого узла m с ребром от n до m do visit (m) удалить временную отметку из n отметить n постоянной меткой добавить n в начало L
Каждый узел n добавляется к выходному списку L только после рассмотрения всех других узлов, которые зависят от n (всех потомков n в графе). В частности, когда алгоритм добавляет узел n, мы гарантируем, что все узлы, зависящие от n, уже находятся в выходном списке L: они были добавлены в L либо рекурсивным вызовом visit (), который завершился перед вызовом visit n, или вызовом visit (), который начался еще до вызова visit n. Поскольку каждое ребро и узел посещаются один раз, алгоритм работает за линейное время. Этот алгоритм, основанный на поиске в глубину, описан Cormen et al. (2001) ; кажется, что он был впервые описан в печати Tarjan (1976).
На параллельной машине с произвольным доступом топологическое упорядочение может быть построено за O (log n) время с использованием полиномиального числа процессоров, помещая задачу в класс сложности NC. Один из способов сделать это - многократно возводить в квадрат матрицу смежности данного графа, логарифмически много раз, используя умножение матрицы мин-плюс с максимизацией вместо минимизации. Результирующая матрица описывает самый длинный путь расстояний на графике. Сортировка вершин по длинам их самых длинных входящих путей приводит к топологическому упорядочиванию.
Алгоритм параллельной топологической сортировки на машинах с распределенной памятью распараллеливает алгоритм Кана для DAG 

Далее предполагается, что раздел графа хранится на p обрабатывающих элементах (PE), которые помечены 



 Выполнение параллельного алгоритма топологической сортировки на DAG с двумя элементами обработки.
Выполнение параллельного алгоритма топологической сортировки на DAG с двумя элементами обработки. На первом этапе PE j присваивает индексы 




На этапе k PE j присваивает индексы 



Обратите внимание, что префикс sum для локальных смещений
pэлементы обработки с идентификаторами от 0 до p-1 Input:Вывод: топологическая сортировка G
функция traverseDAG Распределенная δ входящая степень локальных вершин VQ = {v ∈ V | δ [v] = 0} // Все вершины с степенью 0 nrOfVerticesProcessed = 0 doglobal строим сумму префикса по размеру Q // получаем смещения и общее количество вершин в этот шаг смещение = nrOfVerticesProcessed +  // j - индекс процессора foreach u ∈ Q localOrder [u ] = index ++; foreach (u, v) ∈ E do отправить сообщение (u, v) PE, владеющему вершиной v nrOfVerticesProcessed + = доставить все сообщения соседям вершин в Q получить сообщения для локальных вершин V удалить все вершины в Q foreach получено сообщение (u, v): если --δ [v] = 0, добавить v к Q, а глобальный размер Q>0 return localOrder
// j - индекс процессора foreach u ∈ Q localOrder [u ] = index ++; foreach (u, v) ∈ E do отправить сообщение (u, v) PE, владеющему вершиной v nrOfVerticesProcessed + = доставить все сообщения соседям вершин в Q получить сообщения для локальных вершин V удалить все вершины в Q foreach получено сообщение (u, v): если --δ [v] = 0, добавить v к Q, а глобальный размер Q>0 return localOrderСтоимость связи сильно зависит от данного раздела графа. Что касается времени выполнения, то в модели CRCW-PRAM, которая допускает выборку и декремент за постоянное время, этот алгоритм работает в 
Топологическое упорядочение также может использоваться для быстрого вычисления кратчайших путей через взвешенный ориентированный ациклический граф. Пусть V - список вершин такого графа в топологическом порядке. Затем следующий алгоритм вычисляет кратчайший путь от некоторой исходной вершины s ко всем остальным вершинам:
На графе из n вершин и m ребер, этот алгоритм занимает Θ (n + m), т. е. линейное, время.
Если топологическая сортировка обладает тем свойством, что все пары последовательных вершины в отсортированном порядке соединяются ребрами, затем эти ребра образуют направленный гамильтонов путь в DAG. Если гамильтонов путь существует, топологический порядок сортировки уникален; никакой другой порядок не учитывает края пути. И наоборот, если топологическая сортировка не образует гамильтонов путь, DAG будет иметь два или более допустимых топологического порядка, поскольку в этом случае всегда можно сформировать второй допустимый порядок, поменяв местами две последовательные вершины, которые не соединены ребром. друг другу. Следовательно, можно проверить за линейное время, существует ли уникальный порядок и существует ли гамильтонов путь, несмотря на NP-трудность проблемы гамильтонова пути для более общих ориентированных графов.
Топологические порядки также тесно связаны с концепцией линейного расширения частичного порядка в математике. В терминах высокого уровня существует присоединение между ориентированными графами и частичными порядками.
Частично упорядоченный набор - это просто набор объектов вместе с определением отношения неравенства «≤», удовлетворяющие аксиомам рефлексивности (x ≤ x), антисимметрии (если x ≤ y и y ≤ x, то x = y) и транзитивности (если x ≤ y и y ≤ z, то x ≤ z). Общий порядок - это частичный порядок, в котором для каждых двух объектов x и y в наборе либо x ≤ y, либо y ≤ x. Общие заказы известны в информатике как операторы сравнения, необходимые для выполнения алгоритмов сортировки сравнения. Для конечных наборов общие порядки могут быть идентифицированы с линейными последовательностями объектов, где отношение «≤» истинно всякий раз, когда первый объект предшествует второму объекту в порядке; для преобразования общего порядка в последовательность таким образом может использоваться алгоритм сортировки сравнения. Линейное расширение частичного порядка - это общий порядок, совместимый с ним, в том смысле, что если x ≤ y в частичном порядке, то x ≤ y также и в полном порядке.
Можно определить частичный порядок из любого DAG, позволив набору объектов быть вершинами DAG и определив x ≤ y как истинное для любых двух вершин x и y, если существует направленный путь от x до y; то есть всякий раз, когда y достижим из x. С этими определениями топологический порядок DAG - это то же самое, что и линейное расширение этого частичного порядка. И наоборот, любой частичный порядок на конечном множестве можно определить как отношение достижимости в DAG. Один из способов сделать это - определить группу DAG, которая имеет вершину для каждого объекта в частично упорядоченном наборе и ребро xy для каждой пары объектов, для которых x ≤ y. Альтернативный способ сделать это - использовать транзитивную редукцию частичного упорядочения; как правило, это создает группы DAG с меньшим количеством ребер, но отношение достижимости в этих группах DAG остается тем же частичным порядком. Используя эти конструкции, можно использовать алгоритмы топологического упорядочения для поиска линейных расширений частичных порядков.
