
Войти
В конструкции компилятора статическая форма одиночного присваивания (часто сокращенно форма SSA или просто SSA ) - это свойство промежуточного представления (IR), которое требует, чтобы каждой переменной назначался ровно один раз, и каждая переменная должна быть определена до ее использования. Существующие переменные в исходном IR разделены на версии, новые переменные обычно обозначаются исходным именем с нижним индексом в учебниках, так что каждое определение получает свою собственную версию. В форме SSA цепочки use-def являются явными, и каждая содержит единственный элемент.
SSA был предложен Марком Н. Вегманом, а в 1988 г. Жанна Ферранте и три предыдущих исследователя из IBM разработали алгоритм, который может эффективно вычислять форму SSA.
Можно ожидать найти SSA в компиляторе для Fortran, C или C ++, тогда как в функциональном языке обычно используются компиляторы для схемы и ML, стиля передачи продолжения (CPS). SSA формально эквивалентен подмножеству CPS с хорошим поведением, за исключением нелокального потока управления, чего не происходит, когда CPS используется в качестве промежуточного представления. Таким образом, оптимизации и преобразования, сформулированные в терминах одного, немедленно применяются к другому.
Основная полезность SSA заключается в том, что он одновременно упрощает и улучшает результаты различных оптимизаций компилятора за счет упрощения свойств переменных. Например, рассмотрим этот фрагмент кода:
y: = 1 y: = 2 x: = y
Люди могут видеть, что первое присваивание не требуется и что значение y, используемое в третьей строке, происходит от второго присвоения y. Программа должна будет выполнить анализ определения, чтобы определить это. Но если программа находится в форме SSA, оба из них действуют немедленно:
y1: = 1 y 2 : = 2 x 1 : = y 2
Оптимизация компилятора алгоритмы, которые либо активируются, либо сильно улучшаются за счет использования SSA, включают:
Преобразование обычного кода в форму SSA - это, в первую очередь, простой вопрос замены цели каждого назначения новой переменной и замены каждого использования переменной «версия» переменной , достигшая этой точки. Например, рассмотрим следующий граф потока управления :

. Изменение имени в левой части строки «x 
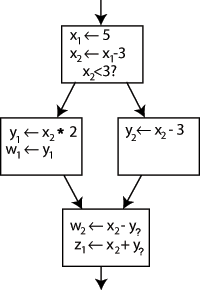
Ясно, к какому определению относится каждое использование, за исключением одного случая: оба использования yв нижнем блоке могут относиться к любому y1или y2, в зависимости от того, какой путь выбрал поток управления.
Чтобы решить эту проблему, в последний блок вставляется специальный оператор, называемый функцией Φ (Phi). Этот оператор сгенерирует новое определение y с именем y3путем «выбора» либо y1, либо y2, в зависимости от потока управления в прошлом.
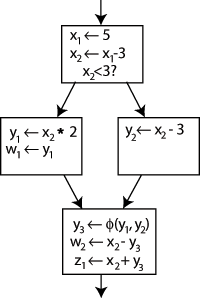
Теперь последний блок может просто использовать y3, и правильное значение будет получено в любом случае. Функция Φ для x не требуется: только одна версия x, а именно x2, достигает этого места, поэтому проблем нет (другими словами, Φ (x1,x2)=x2).
Для произвольного графа потока управления может быть трудно сказать, куда вставить Φ-функции и для каких переменных. Этот общий вопрос имеет эффективное решение, которое может быть вычислено с использованием концепции, называемой границами доминирования (см. Ниже).
Функции Φ не реализованы как машинные операции на большинстве машин. Компилятор может реализовать функцию Φ, вставляя операции «перемещения» в конец каждого блока-предшественника. В приведенном выше примере компилятор может вставить перемещение из От y1до y3в конце среднего левого блока и переход от y2к y3в конце среднего правого блока. Эти операции перемещения могут не закончиться в окончательном коде на основе процедура выделения регистров компилятора. Однако этот подход может не работать, когда одновременные операции предположительно производят входные данные для Φ функция, как это может происходить на машинах с широким выпуском. Как правило, у широко распространенной машины есть инструкция выбора, используемая в таких ситуациях компилятором для реализации функции Φ.
По словам Кенни Задека, функции Φ изначально назывались фальшивыми функциями, в то время как SSA разрабатывалась в IBM Research в 1980-х годах. Формальное название функции Φ было принято только тогда, когда работа была впервые опубликована в академической статье.
Во-первых, нам нужна концепция доминатора : мы говорим, что узел A строго доминирует над другим узлом B в потоке управления график, если невозможно достичь B, не пройдя сначала через A. Это полезно, потому что, если мы когда-нибудь дойдем до B, мы узнаем, что любой код в A запущен. Мы говорим, что A доминирует над B (B доминирует над A), если либо A строго доминирует над B, либо A = B.
Теперь мы можем определить границу доминирования : узел B находится в граница доминирования узла A, если A не строго доминирует над B, но доминирует над некоторым непосредственным предшественником B, или если узел A является непосредственным предшественником B, и, поскольку любой узел доминирует над самим собой, узел A доминирует над собой, и как Узел результата A находится на границе доминирования узла B. С точки зрения A, это узлы, в которых другие пути управления, которые не проходят через A, появляются раньше всего.
Границы доминирования фиксируют точные места, в которых нам нужны функции Φ: если узел A определяет определенную переменную, тогда это определение и это определение само по себе (или переопределения) достигнут каждого узла A. Только когда мы покидаем эти узлы и выходим на границу доминирования, мы должны учитывать другие потоки, вводя другие определения той же переменной. Более того, никакие другие функции Φ не нужны в графе потока управления, чтобы иметь дело с определениями A, и мы можем обойтись не меньшим.
Существует эффективный алгоритм для поиска границ доминирования каждого узла. Этот алгоритм был первоначально описан в Cytron et al. 1991. Также полезна глава 19 книги Эндрю Аппеля "Современная реализация компилятора на Java" (Cambridge University Press, 2002). См. Статью для более подробной информации.
Кейт Д. Купер, Тимоти Дж. Харви и Кен Кеннеди из Университета Райса описывают алгоритм в своей статье под названием «Простой, быстрый алгоритм доминирования». Алгоритм использует хорошо спроектированные структуры данных для повышения производительности. Он выражается просто следующим образом:
для каждого узла b dominance_frontier (b): = {} для каждого узла b, если количество непосредственных предшественников b ≥ 2 для каждого p inнепосредственного предшественника b runner: = p while runner ≠ idom (b) dominance_frontier (бегун): = dominance_frontier (бегун) ∪ {b} runner: = idom (бегун)Примечание: в приведенном выше коде непосредственным предшественником узла n является любой узел, от которого управление передается узлу n, а idom (b) - узел, который сразу доминирует над узлом b (одноэлементный набор).
«Минимальный» SSA вставляет минимальное количество функций Φ, необходимых для обеспечения того, чтобы каждому имени было присвоено значение ровно один раз и что каждая ссылка (использование) имени в исходной программе все еще может относиться к уникальному имени. (Последнее требование необходимо для обеспечения того, чтобы компилятор мог записывать имя для каждого операнда в каждой операции.)
Однако некоторые из этих функций Φ могут быть мертвыми. По этой причине минимальный SSA не обязательно дает наименьшее количество Φ функций, необходимых для конкретной процедуры. Для некоторых типов анализа эти функции Φ излишни и могут привести к снижению эффективности анализа.
Сокращенная форма SSA основана на простом наблюдении: функции Φ необходимы только для переменных, которые «живы» после функции Φ. (Здесь «живое» означает, что значение используется на некотором пути, который начинается с рассматриваемой функции Φ.) Если переменная не является действующей, результат функции Φ не может быть использован, и присвоение функцией Φ не выполняется..
Построение сокращенной формы SSA использует информацию о текущих переменных на этапе вставки функции Φ, чтобы решить, нужна ли данная функция Φ. Если исходное имя переменной отсутствует в точке вставки функции Φ, функция Φ не вставляется.
Другая возможность - рассматривать сокращение как проблему устранения мертвого кода. Тогда функция Φ является активной только в том случае, если какое-либо использование во входной программе будет переписано в нее, или если она будет использоваться в качестве аргумента в другой функции Φ. При вводе формы SSA каждое использование переписывается до ближайшего определения, которое в нем доминирует. Тогда функция Φ будет считаться действующей, если это ближайшее определение, которое доминирует по крайней мере одно использование или по крайней мере один аргумент живого Φ.
Полусрезанная форма SSA - это попытка уменьшить количество функций Φ без относительно высоких затрат на вычисление информации динамических переменных. Он основан на следующем наблюдении: если переменная никогда не становится активной при входе в базовый блок, ей никогда не нужна функция Φ. При построении SSA функции Φ для любых «блочно-локальных» переменных опускаются.
Вычисление набора локальных переменных блока является более простой и быстрой процедурой, чем полный анализ динамических переменных, что делает полу-сокращенную форму SSA более эффективной для вычислений, чем сокращенную форму SSA. С другой стороны, полуобрезанная форма SSA будет содержать больше функций Φ.
Форма SSA обычно не используется для прямого выполнения (хотя SSA можно интерпретировать), и она часто используется «поверх» другого IR, с которым остается в прямой переписке. Это может быть достигнуто путем «построения» SSA как набора функций, которые отображают части существующего IR (базовые блоки, инструкции, операнды и т. Д.) И его аналог SSA. Когда форма SSA больше не нужна, эти функции сопоставления могут быть отброшены, оставив только теперь оптимизированный IR.
Оптимизация формы SSA обычно приводит к запутанным SSA-сетям, что означает наличие инструкций Φ, не все операнды которых имеют одинаковый корневой операнд. В таких случаях для выхода из SSA используются алгоритмы выделения цвета. Наивные алгоритмы вводят копию по каждому пути предшественника, что заставляет источник другого корневого символа быть помещенным в Φ, чем место назначения Φ. Существует несколько алгоритмов выхода из SSA с меньшим количеством копий, большинство из них используют графики интерференции или некоторое их приближение для объединения копий.
Расширения формы SSA можно разделить на две категории.
Расширения схемы переименования изменяют критерий переименования. Напомним, что форма SSA переименовывает каждую переменную, когда ей присваивается значение. Альтернативные схемы включают статическую форму одноразового использования (которая переименовывает каждую переменную в каждом операторе при ее использовании) и статическую форму единой информации (которая переименовывает каждую переменную, когда ей присваивается значение, и на границе пост-доминирования).
Расширения для конкретных функций сохраняют единственное свойство присваивания для переменных, но включают новую семантику для моделирования дополнительных функций. Некоторые специализированные расширения моделируют такие функции языка программирования высокого уровня, как массивы, объекты и указатели с псевдонимами. Другие специфичные для функций расширения моделируют низкоуровневые архитектурные особенности, такие как предположения и предсказания.
Форма SSA - относительно недавняя разработка сообщества компиляторов. Таким образом, многие старые компиляторы используют форму SSA только для некоторой части процесса компиляции или оптимизации, но большинство из них не полагаются на нее. Примеры компиляторов, которые в значительной степени полагаются на форму SSA, включают:
| journal =()