
Войти
Восприятие речи - это процесс, с помощью которого звуки языка слышны, интерпретируются и понимаются. Изучение восприятия речи объединяет с областями фонологии и фонетики в лингвистике и когнитивной психологии и восприятие в психологии. Исследования в области восприятия речи используют то, чтобы понять, как слушатели распознают звуки речи, и использовать эту информацию для понимания устной речи. Исследования восприятия речи находят применение в создании компьютерных систем, способных распознавать речь, в улучшении распознавания речи для слушателей с нарушениями слуха и языка, а также в обучении иностранным языкам.
Процесс восприятия речи начинается на уровне звукового сигнала и процесса прослушивания. (Полное описание прослушивания см. В разделе Слух.) После обработки исходного слухового сигнала звуки процесса обработки обрабатываются для извлечения акустических сигналов и фонетической информации. Затем эту речевую информацию можно использовать для языковых процессов более высокого уровня, таких как распознавание слов.
 Рисунок 1: Спектрограммы слогов «dee» (вверху), »dah» (в середине) и «doo» (внизу), показывающие, как начало переходов формант, которые определяют перцептивноный [d], различаются в зависимости от идентичности следующейсной. (Форманты выделены красными пунктирными линиями; переходы являются началом изгиба траекторий формант.)
Рисунок 1: Спектрограммы слогов «dee» (вверху), »dah» (в середине) и «doo» (внизу), показывающие, как начало переходов формант, которые определяют перцептивноный [d], различаются в зависимости от идентичности следующейсной. (Форманты выделены красными пунктирными линиями; переходы являются началом изгиба траекторий формант.) Акустические сигналы - это сенсорные сигналы, содержащиеся в звуковом звуке речи, используются в восприятии речи для различения звуков речи, принадлежащих к разным фонетическим категориям, одним из наиболее изученных сигналов. в речи является время начала голоса или VOT. VOT - это основная реплика, показательная разница между звонкими и глухими взрывными звуками, такими как «b» и «p». 142>места артикуляции или манерах артикуляции. чевая система также должна комбинировать эти реплики, чтобы определить категорию конкретного речевого звука. Это часто рассматривается в терминах абстрактных представлений фонем. Эти представления можно комбинировать для использования в распознавании слов и других языковых процессах.
Нелегко определить, каким акустическим сигналом чувствительны слушатели при восприятии определенного звука речи:
На первый взгляд решение проблемы, как мы воспринимаем речь, кажется обманчиво основным. Если бы можно было идентифицировать отрезки акустической волны. Однако это отображение или отображение трудно найти даже после 45 лет исследований этой проблемы.
Если конкретный аспект акустической волны указывал на одну лингвистическую единицу, серия тестов с использованием синтезаторов речи бы быть достаточным для определения такой реплики или реплик. Однако есть два существенных препятствия:
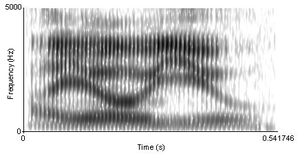 Рисунок 2: Спектрограмма фразы «Я должен тебе». Между звуками речи нет четко различимых границ.
Рисунок 2: Спектрограмма фразы «Я должен тебе». Между звуками речи нет четко различимых границ. Хотя слушатели воспринимают речь как поток дискретных единиц (фон, слоги и слова ), эту линейность трудно увидеть в физическом речевом сигнале. рисунок 2). Звуки речи не следуют друг за другом строго, они скорее накладываются друг на друга. На звук звуки ответственные и последующие звуки. Это влияние может проявляться даже на расстоянии двух или более сегментов (и через границы слогов и слов).
Речевой сигнал не является линейным, возникает проблема сегментации. Трудно отрезком речевого сигнала как принадлежащий одной единице восприятия. Например, акустические фонемы / d / будут зависеть от образования следующей гласной (из-за сращивания свойств ).
Исследование и применение восприятия речи иметь дело с проблемами, которые возникают в результате того, что было названо отсутствием инвариантности. Трудно найти надежные постоянные связи между фонемой языком и ее акустическим проявлением в речи. Для этого есть несколько причин:
Фонетическая среда влияет на акустические свойства звуков речи. Например, / u / на английском языке начинается в окружении корональных согласных. Или время начала голоса, обозначающее границу между звонкими и глухими взрывчатыми веществами, различно для различных, альвеолярных и велярных взрывных устройств, и они смещаются при ударении или в зависимости от положения в слоге.
Одним из важных факторов, вызывающих различия, является разная скорость речи. Многие фонематические контрасты состоят из временных характеристик (короткие против долгих гласных или согласующихся, аффрикаты против фрикативных, взрывные против скользящих, звонкие против глухих и т. Д.), И на них, безусловно, изменения в темпе речи. Другой важный источник вариаций - артикуляционная осторожность и небрежность, что характерно для связной речи (артикуляционный «недокус», очевидно, отражается на акустических свойствах производимых звуков).
Результирующая акустическая структура конкретных речевых произведений зависит от физических и психологических свойств отдельных говорящих. Мужчины, женщины и дети обычно издают голоса разной высоты. Говорящих есть голосовые тракты разного размера (особенно в зависимости от пола и возраста), резонансные частоты (форманты ), которые важны для распознавания звуков речи, будут различаться по своим абсолютным значениям у разных людей (см. Рисунок). 3 иллюстрации этого). Исследования, что младенцы в возрасте 7,5 месяцев не могут распознавать информацию, представленную носителями разных полов; однако к 10,5 месяцам они могут построить сходство. Диалект и иностранный акцент также могут вызывать вариации, как и социальные характеристики говорящего и слушателя.
 Рисунок 3: На левой панели показаны 3 периферийных гласных американского английского языка / i /, / ɑ / и / u / на стандартном графике F1 на F2 (в Гц). Несоответствие мужских, женских и детских ценностей очевидно. На правой панели показаны формантные расстояния (в Барк ), а не абсолютные значения с использованием процедуры нормализации предложенной Сырдал и Гопал в 1986 году. Формантные взяты из Hillenbrand et al. (1995)
Рисунок 3: На левой панели показаны 3 периферийных гласных американского английского языка / i /, / ɑ / и / u / на стандартном графике F1 на F2 (в Гц). Несоответствие мужских, женских и детских ценностей очевидно. На правой панели показаны формантные расстояния (в Барк ), а не абсолютные значения с использованием процедуры нормализации предложенной Сырдал и Гопал в 1986 году. Формантные взяты из Hillenbrand et al. (1995) Несмотря на огромное разнообразие говорящих и разные условия, слушатели воспринимают гласные и согласные как постоянные категории. Было предложено, что это достигается посредством процесса перцепционной стабилизации, в котором слушатели отфильтровывают шум (то есть вариации), чтобы прийти к основной категории. Различия в размерех голосовых трактов приводят к вариациям формантных частот у динамиков; поэтому слушатель должен приспособить свою систему восприятия к акустическим характеристикам конкретного говорящего. Это может быть достигнуто путем запуска формант, а не их абсолютных значений. Этот процесс получил название нормализации голосового тракта (см. Пример на Рисунке 3). Точно так же считается, что слушатели регулируют восприятие продолжительности в соответствии с текущим темпом речи, которые они слушают - это называется нормализацией скорости речи.
Происходит ли нормализация на самом деле и какова ее точная природа - предмет теоретических споров (см. теории ниже). Постоянство восприятия - явление, характерное не только для восприятия речи; он существует и в других типах восприятия.
 Рис. 4. Пример характеристик (красный) и различения (синий)
Рис. 4. Пример характеристик (красный) и различения (синий) Категорическое восприятие влияет в процессах перцепционной дифференциации. Люди воспринимают звуки речи категорично, то есть они с большей вероятностью замечают различия между категориями (фонемами), чем внутри категорий. Таким образом, пространство восприятия между категориями искажается, уровни категорий (или «прототипы») работают сито или как магниты для входящих звуков речи.
В искусственном континууме между безмолвным и звонким двугубным номером каждый новый шаг отличается от предыдущего взрыва VOT. Первый звук - это предварительный озвученный [b], то есть он имеет отрицательный VOT. Затем, увеличивая VOT, он достижения нуля, т. Е. Взрывное устройство представляет собой простой без выдыхания безмолвный [p]. Постепенно, добавляя одно и то же количество VOT за раз, взрывное вещество в конечном итоге становится глухим двухгубным с сильным придыханием [pʰ]. (Такой континуум использовался в эксперименте Лискером и Абрамсоном в 1970 году. Звуки, которые они использовали, доступны в Интернете.) В этом континууме, например Семь звуков, слушатели-носители английского языка идентифицируют первые три звука как / b /, а последние три звука как / p / с четкой границей между двумя категориями. Тест на двухальативную идентификацию (или категоризацию) даст прерывистую функцию категоризации (см. Красную кривую на рисунке 4).
В тестах на способность различать два звука с различными значениями VOT, но имеющими постоянное расстояние VOT от друга (например, 20 мс), слушатели, вероятно, будут работать на случайном уровне, оба звука попадают в одну и та же категория и почти на 100% уровне, если каждый звук попадает в другую категорию (см. синюю кривую дискриминации на рисунке 4).
Вывод, который можно сделать как из теста идентификации, так и из дискриминации, состоит в том, что слушатели будут иметь разную чувствительность к одному и тому же относительному увеличению VOT в зависимости от того, была ли пересечена граница между категориими. Аналогичная перцептивная корректировка подтверждается и для других акустических сигналов.
В классическом эксперименте Ричард М. Уоррен (1970) заменил одну фонему слова на звук, похожий на кашель. С точки зрения восприятия испытуемые без труда восстанавливали отсутствующий звук речи и не могли точно определить, какая фонема была точна. Это явление известно как эффект восстановления фонемы. Следовательно, процесс восприятия речи не обязательно однонаправленный.
В другом базовом эксперименте сравнивали распознавание произносимых слов во фразе и тех же слов в отдельности, обнаружив, что точность восприятия обычно падает в последнем случае. Чтобы исследовать влияние семантических знаний на восприятие, Гарнс и Бонд (1976) аналогичным образом использовали предложения-носители, в целевые слова отличались только одной фоновой (например, залив / день / гей), качество которого менялось в зависимости от континуума. Когда они складываются в разные предложения, каждый из которых состоит из естественных способов одной интерпретации, слушатели склонны судить о двусмысленных словах согласно значению всего предложения. То есть языковые процессы более высокого уровня, связанные с морфологией, синтаксисом или семантикой, могут взаимодействовать с базовыми процессами восприятия речи, помогая распознавать звуки речи.
Может случиться так, что слушателю не обязательно, даже невозможно распознавать фонемы перед распознаванием высших единиц, например слов. Получив по крайней мере фундаментальную информацию о фонематической структуре воспринимаемого объекта из акустического сигнала, слушатели могут компенсировать отсутствующие или замаскированные шумом фонемы, используя свои знания разговорного языка. Компенсационные механизмы могут даже работать на уровне предложения, например, в выученных песнях, фразах и стихах, эффект, подкрепленный паттернами нейронного кодирования, поддерживает пропущенным фрагментам непрерывной речи, несмотря на отсутствие всех соответствующих частей сенсорный ввод.
Первая гипотеза восприятия речи была пациентом, у развился дефицит слухового восприятия, также известный как рецептивная афазия. С тех пор было классифицировано множество инвалидностей, что привело к истинному определению «восприятия речи». Термин «восприятие речи» содержит интересующий процесс, который использует сублексические контексты для проверки. Он состоит из нескольких различных языковых и грамматических функций, таких как: особенности, сегменты (фонемы), слоговая структура (единица произношения), фонологические слова формы (как звуки сгруппированы вместе), грамматические особенности, морфема (префиксы и суффиксы) и семантическая информация ( слов). В первые их больше интересовала акустика речи годы. Например, они изучали различия между / ba / или / da /, но теперь исследование было направлено на реакцию мозга на стимулы. В последние годы была заложена модель, позволяющая понять, как работает восприятие речи; эта модель известна как модель двойного потока. Эта модель радикально изменилась по сравнению с тем, как психологи смотрят на восприятие. Первая часть модели двойного потока - это вентральный путь. Этот путь включает среднюю височную извилину, нижнюю височную борозду и, возможно, нижнюю височную извилину. Вентральный путь показывает фоновые представления лексическим или концептуальным представлениям, что является значением словологические. Вторая часть модели двойного потока - дорсальный путь. Этот путь включает сильвиевую теменно-височную, нижнюю лобную извилину, переднюю островковую долю и премоторную кору. Его основная функция состоит в том, чтобы сенсорные или фонологические стимулы и преобразовывать их в артикуляционно-моторное представление (формирование речи).
Афазия - нарушение обработки речи, вызванное повреждением мозга. Различные части речевой обработки подвержены влиянию зависимости от области мозга, которая повреждена, и афазия обычно классифицируется в зависимости от ситуации травмы или совокупности симптомов. Повреждение области Брока головного мозга часто приводит к экспрессивной афазии, которая проявляется в нарушении речевой деятельности. Повреждение области Вернике приводит часто к рецептивной афазии, при которой нарушается обработка речи.
Афазия с нарушением восприятия речи обычно проявляется поражениями или повреждениями, расположенными слева височные или теменные доли. Лексические и семантические трудности имеют место обычным, и понимание может быть нарушено.
Агнозия - это «потеря или уменьшение способности узнавать знакомые объекты или стимулы, обычно в результате повреждения мозга». Существует несколько различных видов агнозии, которые влияют на все наши чувства, но два наиболее распространенных, связанных с речью, - это и фонагнозия.
речевая агнозия : глухота, связанная с чистым словом, или речевая агнозия, является нарушением в при котором человек сохраняет способность слышать, произносить речь и даже читать речь, но при этом не может понимать или правильно воспринимать речь. Эти пациенты, по-видимому, обладают всеми навыками, необходимыми для правильной обработки речи, но, похоже, у них нет опыта, связанного с речевыми стимулами. Пациенты сообщали: «Я слышу, как вы говорите, но не могу перевести». Даже если они физически получают и обрабатывают речевые стимулы, не имея возможности определять значение речи, они, по сути, вообще не могут воспринимать речь. Не найдено никаких известных методов лечения, но из тематических исследований и экспериментов известно, что речевая агнозия связана с поражениями в левом или обоих полушариях, особенно с правыми височно-теменными дисфункциями.
Фонагнозия : Фонагнозия связан с неспособностью узнавать какие-либо знакомые голоса. В этих случаях речевые стимулы можно услышать и даже понять, но связь речи с определенным голосом теряется. Это может быть связано с «ненормальной обработкой сложных вокальных свойств (тембр, артикуляция и просодия - элементы, которые отличают индивидуальный голос»). Лечение не известно; тем не менее, есть отчет о женщине-эпилептике, у которой началась фонагнозия. Наряду с другими нарушениями. Ее результаты ЭЭГ и МРТ показали "Т2-гиперинтенсивное повреждение правой кортикальной париетальной области без усиления гадолиния и с дискретным нарушением диффузии молекул воды". Таким образом, хотя лечение не было обнаружено, фонагнозия может быть связана с постиктальной теменной корковой дисфункцией.
Младенцы начинают процесс овладения языком, будучи способными обнаруживать очень небольшие различия между звуками речи. Они могут различать все возможные речевые контрасты (фонемы Постепенно, когда они знакомятся со своим родным языком, их восприятие становится специфичным для языка, то есть они учатся игнорировать различия внутри фонематических категорий. языка (различия, которые могут быть весьма контрастными в других языках - например, английский различает две голосовые категории взрывных, тогда как тайский имеет три категории ; младенцы должны знать, какие различия характерны для их родного языка, а какие нет). По мере того, как младенцы учатся сортировать входящие звуки речи по категориям, игнорируя несущественные различия и усиливая контрастные, их восприятие становится категориальным. Младенцы учатся противопоставлять разные гласные фонемы своего родного языка примерно к 6-месячному возрасту. Родные согласные контрасты приобретаются к 11–12-месячному возрасту. Некоторые исследователи предположили, что младенцы могут изучать звуковые категории своего родного языка по средством пассивного слушания, используя процесс, называемый статистическим обучением. Другие даже утверждают, что определенные звуковые категории являются врожденными, то есть они генетически специфицированы (см.Обсуждение врожденной категориальной отличимости ).
Если однодневным детям предъявляется нормальный, ненормальный (монотонный) голос матери и чужой голос, они реагируют только на нормальный голос матери. Когда воспроизводятся человеческие и нечеловеческие звуки, младенцы поворачивают голову только к источнику человеческого звука. Было высказано предположение, что слуховое обучение начинается уже в пренатальном периоде.
Одним из методов, используемых для изучения, как младенцы воспринимают речь, помимо упомянутой выше процедуры поворота головы, измерения их скорости сосания. В таком эксперименте ребенок сосет специальный сосок, когда ему предъявляют звуки. Сначала устанавливается нормальная скорость сосания ребенка. Затем стимул воспроизводится повторно. Когда ребенок впервые слышит стимул, скорость сосания увеличивается, но по мере того, как ребенок привыкает к стим, скорость сосания уменьшается и выравнивается. Затем ребенку дается новый стимул. Если ребенок воспринимает введенный стимул, как отличный от фонового, скорость сосания возрастет. Скорость сосания и метод поворота головы - одни из наиболее восприятия поведенческих методов речи. Среди новых методов (см. Методы исследования ниже), которые нам исследуют восприятие речи, спектроскопия в ближнем инфракрасном диапазоне широко используется у младенцев.
Она также обнаружила, что даже на то, что способность младенцев различать различные фонетические свойства разных языков начинает снижаться примерно в возрасте девяти месяцев, можно обратить этот процесс вспять, достаточно познакомиться с новым языком. В ходе исследования, проведенного Патрисией К. Куль, Фэн-Мин Цао и Хуэй-Мей Лю, было обнаружено, что если с младенцами разговаривают и с ними общаются носители китайского мандаринского языка, их можно на самом деле научить своими способностями. чтобы различать звуки речи на китайском языке, которые отличаются от звуков речи на английском языке. Таким образом доказывается, что при правильных условиях можно предотвратить потерю младенцами способности различать звуки речи на языках, отличных от тех, которые присутствуют в родном языке.
Большое количество исследований посвящено изучению того, как пользователи языка воспринимают иностранную речь (называемую восприятием межъязыковой речи) или второязычную речь (речь на втором языке). восприятие). Последний относится к сфере овладения вторым языком.
Языки различаются по своему фонематическому инвентарю. Естественно, это создает трудности при знакомстве с иностранным языком. Например, если два звука иностранного языка отнесены к одной категории родного языка, разница между ними будет очень трудно различить. Классическим примером такой ситуации является наблюдение, что японские изучающие английский язык будут иметь проблемы с распознаванием или различением английских жидких согласных / l / и / r / (см. Восприятие английского языка / r / и / l / носителями японского языка ).
Бест (1995) использует модель перцептивной ассимиляции, которая представляет несколько моделей ассимиляции категорий между языками и предсказывает их последствия. Флеге (1995) сформулировал модель речевого обучения, которая объединяет гипотез о втором языке (L2) получение речи и предсказывает простыми словами, что звук L2, не слишком похож на звук на родном языке (L1), будет легче усвоить, чем звук L2, который относительно похож на звук L1 (потому что он будет
Исследование того, как люди с нарушением речи или слуха воспринимают речь, не только направлено на выявление методов лечения. нормального восприятия речи. Примером могут служить две области исследования:
Афазия влияет как на выражение, так и на восприятие языка. Оба наиболее распространенных типа, экспрессивная афазия и рецептивная афазия, в некоторой степени воздействие на восприятие речи. Выразительная афазия вызывает умеренные трудности в понимании языка. Эффект рецептивной афазии на понимание гораздо более серьезен. Принято считать, что афазики страдают дефицитом восприятия. Обычно они не могут полностью различить место артикуляции и озвучивания. Что касается других функций, то сложности разные. Пока не доказано, нарушаются ли у лиц, страдающих афазией, навыки восприятия речи низкого уровня или же их трудности вызваны нарушением более высокого уровня.
Кохлеарная имплантация восстанавливает доступ к акустическому сигналу у людей с нейросенсорной тугоухостью. Акустической информации, передаваемой имплантатом, обычно достаточно для пользователей имплантата, чтобы правильно распознавать речь людей, которых они знают, даже без визуальных подсказок. Пользователям кохлеарных имплантатов труднее понимать неизвестные динамики и звуки. Восприятие детей, которым имплантировали после двухлетнего возраста, значительно лучше, чем у тех, кому имплантировали в зрелом возрасте. Было показано, что на характеристики восприятия влияет ряд факторов, в частности: продолжительность использования глухоты до имплантации, возраст начала глухоты, возраст на момент имплантации (такие возрастные эффекты могут быть связаны с гипотезой критического периода ) и продолжительность использования имплантата. Есть различия между детьми с врожденной и глухотой. Постлингвально глухие дети имеют лучшие результаты, чем доязычные глухие, и быстрее адаптируются к кохлеарному имплантату. У обоих детей с кохлеарными имплантатами и нормальным слухом время появления гласных и голоса становится преобладающим в развитии до того, как способность различать место артикуляции. Через несколько месяцев после имплантации дети с кохлеарными имплантатами могут нормализовать восприятие речи.
Одна из фундаментальных проблем в изучении речи - как бороться с шумом. Об этом свидетельствует сложность распознавания обратной речи в компьютерных системах распознавания. Хотя они могут хорошо распознавать речь, если обучены голосу конкретного говорящего и в тихих условиях, эти системы часто плохо справляются с более реалистичными ситуациями прослушивания, когда люди понимают речь без относительных трудностей. Для имитации шаблонов обработки, которые хранятся в мозгу при нормальных условиях, предварительные знания используются нейронными факторами, как надежная история обучения может до некоторой степени перекрывать экстремальные маскирующие эффекты, связанные с полным отсутствием непрерывного речевые сигналы.
Исследование взаимосвязи между музыкой и познанием - это новая область, связанная с изучением восприятия речи. Первоначально предполагалось, что нейронные сигналы для музыки обрабатываются в специализированном «модуле» в правом полушарии мозга. И наоборот, нейронные сигналы для речи должны быть обрабатываться аналогичным «модулем» в левом полушарии. Исследования показывают, что в двух областях, традиционно считающихся для обработки речи, области, становятся активными во время музыкальной деятельности, такие как прослушивание музыкальных аккордов. Другие исследования, например, проведенное Marques et al. В 2006 году показали, что 8-летние дети, которым было предоставлено шесть месяцев музыкального обучения, показали улучшение, как в их распознают качество звука, так и в их электрофизиологических показателях, когда их заставляли слушать неизвестный иностранный язык.
И наоборот, некоторые исследования показали, что наша родная речь не влияет на восприятие речи, а влияет на восприятие музыки. Одним из примеров является парадокс тритона. Парадокс тритона заключен в том, что слушателю соответствует два генерируемых компьютера тона (например, C и F-Sharp), которые находятся на расстоянии половины октавы (или тритона), и его просят определить, идет ли высота тона последовательности по убыванию или Восходящий. Одно из таких исследований, проведенное г-жой Дайаной Дойч, показало, что интерпретация слушателя высоты звука зависит от языка или диалекта слушателя, между теми, кто вырос на юге Англии, и теми, кто в Калифорнии, или теми, кто во Вьетнаме и те в Калифорнии, чьим родным языком был английский. Второе исследование, проведенное в 2006 году в группе англоговорящих и трех студентов из Южной Азии в Университете Калифорнии, обнаружено, что носители английского языка, которые начали музыкальное обучение в возрасте 5 лет или раньше, имели 8% -ный шанс иметь совершенный слух.
Кейси О'Каллаган в своей статье Опыт речи анализирует, «отличается ли перцептивный опыт от слушания речи феноменальным характером» что касается понимания языка, который вы слышите. Он утверждает, что опыт человека при слушании языка, который он понимает, в отличие от опыта, полученного им при слушании языка, которого он не знает, показывает разницу в феноменальных характеристиках, которые он определяет как «те аспекты, на что похож опыт» для человека..
представляет собой моноязычным носителем английского языка, представлен речевой стимул на немецком языке, цепочка фонем будет выглядеть как простой звуки и вызовет совершенно другой опыт, чем если бы был представлен точно такой же стимул. субъекту, говорящему по-немецки.
Он также исследует, как меняется восприятие речи при изучении языка. Если субъекту, не знающему японского языка, был предложен стимул японской речи, а затем он получил те же стимулы после обучения японскому языку, у этого же человека был бы совершенно другой опыт.
Методы, использованные при исследовании восприятия речи, можно условно разделить на три группы: поведенческие, вычислительные и, в последнее время, нейрофизиологические методы.
Поведенческие эксперименты основаны на роли участника, которому подвергаются испытуемые стимулы и просят принять в отношении них осознанное решение. Это может быть идентификационный тест, тест различения, оценка сходства и т. Д. Эти типы экспериментов помогают дать базовое описание того, как слушатели воспринимают и классифицируют звуки речи.
Восприятие речи также было проанализировано с помощью синусоидальной речи, формы синтетической речи, в которой человеческий голос заменен синусоидальными волнами, имитирующими частоты и амплитуды, присутствующие в исходной речи. Когда испытуемым впервые предлагают эту речь, синусоидальная речь интерпретируется как случайный шум. Но когда испытуемых информируют о том, что стимулы на самом деле являются речью, и им рассказывают, что они говорят, «характерный, почти немедленный сдвиг происходит» в том, как воспринимается синусоидальная речь.
Вычислительное моделирование также использовалось для моделирования того, как мозг может обрабатывать речь для создания наблюдаемого поведения. Компьютерные модели использовались для решения нескольких вопросов восприятия речи, в том числе того, как обрабатывается сам звуковой сигнал для извлечения акустических сигналов, используемых в речи, и как речевая информация используется для процессов более высокого уровня, таких как распознавание слов.
Нейрофизиологические методы основываются на использовании информации, полученной в результате более прямых и необязательно осознанных (предварительных) процессов. Испытуемым предъявляют речевые стимулы в различных типах задач, и измеряют реакцию мозга. Сам мозг может быть более чувствительным, чем кажется, благодаря поведенческим реакциям. Например, субъект может не проявлять чувствительность к разнице между двумя звуками речи в тесте на различение, но реакции мозга могут выявить чувствительность к этим различиям. Методы, используемые для измерения нейронных реакций на речь, включают связанные с событием потенциалы, магнитоэнцефалографию и спектроскопию в ближнем инфракрасном диапазоне. Одним из важных ответов, используемых с связанными с событием потенциалами, является негативность несоответствия, которая возникает, когда речевые стимулы акустически отличаются от стимула, который субъект слышал ранее.
Нейрофизиологические методы были введены в исследования восприятия речи по нескольким причинам:
Поведенческие реакции могут отражать поздние сознательные процессы и зависеть от других систем, таких как орфография, и, таким образом, они могут маскировать способность говорящего распознавать звуки на основе на акустических распределениях нижнего уровня.
Без необходимости принимать активное участие в тестировании, даже младенцы могут быть протестированы; эта функция имеет решающее значение при исследовании процессов приобретения. Возможность наблюдать низкоуровневые слуховые процессы независимо от высокоуровневых позволяет решать давние теоретические вопросы, например, есть ли у людей специализированный модуль для восприятия речи или есть ли сложная акустическая инвариантность (см. отсутствие инвариантности выше) лежит в основе распознавания звука речи.
Некоторые из самых ранних работ по изучению того, как люди Восприятие звуков речи было проведено Элвином Либерманом и его коллегами из Haskins Laboratories. Используя синтезатор речи, они сконструировали звуки речи, которые изменялись в месте артикуляции вдоль континуума от / bɑ / до / dɑ / до / ɡɑ /. Слушателей попросили определить, какой звук они слышали, и различить два разных звука. Результаты эксперимента показали, что слушатели сгруппировали звуки по дискретным категориям, хотя звуки, которые они слышали, постоянно менялись. Основываясь на этих результатах, они предложили понятие категориального восприятия как механизма, с помощью которого люди могут идентифицировать звуки речи.
Более поздние исследования с использованием различных задач и методов показывают, что слушатели очень чувствительны к акустическим различиям в пределах одной фонетической категории, продолжая. Придерживайтесь строгой категоричности восприятия речи.
Для теоретического обоснования данных категориального восприятия Либерман и его коллеги разработали моторную теорию восприятия речи, в которой «сложное искусство. Предполагалось, что кодирование iculatory декодируется в восприятии речи теми же. же процессами, которые участвуют в производстве »(это называется анализом-синтезом), английский / может отличаться по своим акустическим деталям в разных фонетических контекстах (см. выше), но все / d / в восприятии слушателя попадают в одну категорию (звонкие альвеолярные взрывные), и это потому, что «лингвистические представления являются абстрактными, каноническими, фонетическими сегментами. или жесты, лежащие в основе этих сегментов ». и перешел к нейронным командам артикуляторам и даже позже намеченным артикуляционным жестам, таким образом, нейронное представление высказывания, которое определяет про дукцию говорящего. является дистальным средством, воспринимающим ». Теория вместе с гипотезой модульности, которая предполагает наличие модуля специального назначения, должен быть врожденным и вероятным человеческим.
Теория подверглась критике с точки зрения неспособности «предоставить отчет о том, как акустические сигналы переводятся в намеченные жесты» слушателями. Кроме того, неясно, как индексированная информация (например, идентичность говорящего) кодируется / декодируется вместе с лингвистически релевантной информацией.
Образцовые модели восприятия отличаются от четырех упомянутых выше теорий, предполагают, что нет никакой связи между распознаванием слов и говорящего и что различиями между говорящими «шумом» быть отфильтрованным.
Подходы на основе заявляют, что слушатели хранят информацию как для распознавания слов, так и для распознавания говорящего. Согласно этой теории, отдельные экземпляры звуков речи сохраняются в памяти слушателя. В процессе восприятия речи запомненные экземпляры, например, слог, хранящийся в памяти слушателя, сравнивается с входящим стимулом, чтобы стимулы можно было классифицировать. Точно так же при распознавании говорящего активируются все следы в памяти говорящим, говорящим голосом. Эту те подтверждают несколько экспериментов, которые сообщают, что наша точная передача сигнала более точным, когда у нас есть визуальное представление о его поле. Когда говорящий непредсказуем или неверно определен пол, частота ошибок при идентификации слов намного выше.
Образцы моделей сталкиваются с возражениями, два из которых: (1) недостаточный объем для каждого-либо услышанного, что касается способности воспроизводить то, что было услышано, (2) артикуляционные жесты сохраняются при воспроизведении высказываний, которые звучали бы как слуховые воспоминания.
Кеннет Н. Стивенс акустические ориентиры и отличительные черты как связь между фонологическими характеристиками. и слуховые свойства. Согласно этой точке зрения, слушатели проверяют входящий сигнал на предмет так называемых акустических ориентированных, которые представляют собой сигналы в спектре, несущие информацию о, которые их производили. Эти возможности ограничены возможностями артикуляторов человека, а слушатели чувствительны к их слуховым коррелятам, отсутствие инвариантности в этой модели просто не существует. Акустические ориентировочного состава для определения отличительных черт. Связки из них однозначно определяют фонетические сегменты (фонемы, слоги, слова).
Считается, что в этой модели входящий акустический сигнал сначала обрабатывается для определения так называемых ориентированных, которые являются особыми спектральными событиями в сигнале; например, гласные обычно обозначают более высокие форманты, имеют согласные могут быть указаны как разрывы в сигнале и более низкие амплитуды в нижней и средней области. Эти акустические особенности являются результатом артикуляции. Фактически, вторичные артикуляционные пропагандистские Программу, когда требуется улучшение из-за внешних условий, таких как шум. Стивенс утверждает, что коартикуляция вызывает только ограниченное и, более того, систематическое и, следовательно, предсказуемое изменение сигнала, с которым слушатель может иметь дело. Следовательно, в рамках этой модели то, что называется отсутствием инвариантности, просто существует, что не существует.
Ориентиры анализируются для определенных артикуляционных событий (жестов), которые с ними связаны. На следующем этапе акустические реплики извлекаются из сигнала ориентированного посредством физического измерения параметров параметров, таких как частоты спектральных пиков, амплитуды в низкочастотной области или время.
Следующий этап обработки - закрепление акустических сигналов и выделение отличительных признаков. Это бинарные категории, относящиеся к артикуляции (например, [+/- высокий], [+/- назад], [+/- круглые губы] для гласных; [+/- сонорный], [+/- латеральный] или [+ / - назальный] для согласных.
Связи этих характеристик однозначно идентифицируют речевые сегменты (фонемы, слоги, слова). Эти сегменты являются частями лексикона, хранящимися в памяти слушателя. Таким образом создается одна попытка с шаблоном-кандидатом., таким образом, реконструировать артикуляционные события таким образом, которые были необходимы для создания воспринимаемого речевого сигнала. анализ путем синтеза.
Таким образом, эта теория утверждает, что дистальный объект восприятия речи - это артикуляционные жесты, лежащие в основе речи. сится к тем, именуются анализом путем синтеза. сестренка.
Гипотеза речевого режима - это идея о том, что восприятие речи требует использования специализированной мысленной обработки. Гипотеза речевого режима является ответвлением теории модульности Фодора (см. модульность разума ). Он использует механизм вертикальной обработки, который ограничивает стимулы обработки специальными областями мозга, которые являются специфическими для стимулов.
Две версии гипотезы о речевом режиме:
В поисках доказательств гипотезы речевого режима возникли три экспериментальные парадигмы. Это дихотическое слушание, категориальное восприятие и дуплексное восприятие. В ходе исследований в этих категориях было обнаружено, что может не быть определенного речевого режима, а вместо этого может быть режим для слуховых кодов, требующих сложных слуховой обработки. Также кажется, что модульность изучается в системе восприятия. Несмотря на это, доказательства и контрдоказательства в пользу гипотезы речевого режима все еще неясны и требуются дальнейшие исследования.
Теория прямого реализма восприятия речи (в основном связанная с Кэрол Фаулер ) является частью более общей теории прямого реализма, который постулирует, что восприятие позволяет нам получить прямое представление о мире, поскольку оно включает прямое восстановление воспринимаемое событие исходного события. Что касается восприятия речи, теория утверждает, что объекты восприятия являются действительными движениями или жестами голосового тракта, а не абстрактными фонемами или (как в моторной теории) событиями, которыено предшествуют этим движением, т.е. жесты. Слушатели воспринимают жесты не с помощью специального декодера (как в теории мотора), а потому, что информация в акустическом сигнале определяет жесты, которые его формируют. Утверждая, что собственно артикуляционные жесты, производящие различные звуки речи, сами являются единицами восприятия речи, теория обходит проблему отсутствия инвариантности.