
Войти
Румынский алфавит является вариантом латинского алфавита, используемого в Румынский язык. Это модификация классического латинского алфавита и состоит из 31 буквы, пять из которых (Ă, Â, Î, Ș и Ț) были изменены по сравнению с их латинскими оригиналами для фонетических требований языка. :
| Буква | Имя |
|---|---|
| A, a | a |
| Ă, ă | ă |
| Â, â | î / î din a |
| B, b | be / bî |
| C, c | ce / cî |
| D, d | de / dî |
| E, e | e |
| F, f | ef / fe / fî |
| G, g | ge / ghe / gî |
| H, h | haș / ha / hî |
| I, i | i |
| Letter | Имя |
|---|---|
| Î, î | î / î din i |
| J, j | je / jî |
| K, k | ca / capa |
| L, l | el / le / lî |
| M, m | em / me / mî |
| N, n | en / ne / nî |
| O, o | o |
| P, p | pe / pî |
| Q, q | chiu (/ ky /) |
| R, r | er / re / rî |
| S, s | es / se / sî |
| Буква | Имя |
|---|---|
| Ș, ș | șe / î |
| T, t | te / tî |
| Ț, ț | țe / î |
| U, u | u |
| V, v | ve / vî |
| W, w | dublu ve / dublu vî |
| X, x | ics |
| Y, y | igrec / i grec |
| Z, z | ze / zet / zed / zî |
Буквы Q (ch iu), W (dublu v) и Y (igrec или i grec) были официально введены в румынский алфавит в 1982 году, хотя использовались и раньше. Они встречаются только в иностранных словах и их румынских производных, таких как quasar, watt и yacht. Буква K, хотя и относительно старая, также редко используется и появляется только в именах собственных и международных неологизмах, таких как килограмм, брокер, карате. Эти четыре буквы все еще воспринимаются как иностранные, что объясняет их использование в стилистических целях в таких словах, как nomenklatură (обычно nomenclatură, что означает «номенклатура», но иногда пишется с k вместо c, если относится к членам коммунистического руководства в Советском Союзе. и страны Восточного блока, поскольку Nomenklatura используется в английском языке).
В случаях, когда слово является прямым заимствованием и имеет диакритические знаки, отсутствующие в приведенном выше алфавите, официальное правописание имеет тенденцию к предпочтению их использование (München, Angoulême и т. д., в отличие от использования Istanbul над Стамбулом).
Румынское правописание в основном фонематическое, без молчаливых букв (но см. I). В таблице ниже показано соответствие между буквами и звуками. Некоторые буквы имеют несколько возможных прочтений, даже если не учитывать аллофоны. Когда гласные / i /, / u /, / e / и / o / заменяются соответствующими им полугласными, это не отмечается в письменной форме. Буквы K, Q, W и Y появляются только в иностранных заимствованиях; произношение W и Y и комбинации QU зависит от происхождения слова, в котором они встречаются.
| Letter | Phoneme | Примерное произношение |
|---|---|---|
| A a | /a / | a в "отце" |
| Ă ă (a с breve ) | /ə / | в "выше" |
| Â â (a с циркумфлексом ) | /ɨ / | закрывающий центральный неокругленный гласный, как слышно, для Например, в последнем слоге слова roses для некоторых носителей английского языка, употребляемом внутри слова, "bread" = "pâine" |
| B b | /b / | b в "ball" |
| C c | /k / | c in «сканировать» |
| /tʃ / | ch в слове «шимпанзе» - если c появляется перед буквами e или i (но не î); в этом случае e и i обычно не произносятся в комбинациях: cea (cia в некоторых заимствованных словах), cio, ciu и в конце слова ci, если без ударения | |
| D d | /d / | d в "door" |
| E e | /e / | e в "merry" |
| / e̯ /, / ɛ̯ / | перед a или o - полусловесный / e /; если ему не предшествует согласный, становится / j / | |
| / je /, / jɛ / | ye в «да» - в нескольких старых словах с начальным e: este, el и т. д. | |
| F f | /f / | f in "flag" |
| G g | /ɡ / | g in "goa" t " |
| /dʒ / | g в" общем "- если g стоит перед буквами e или i (но не î); в этом случае e и i обычно не произносятся в комбинациях: gea (gia в некоторых заимствованных словах), gio (geo в некоторых заимствованных словах), giu и в конце слова gi, если без ударения | |
| H h | /h / ([h ], [ç ], [x ]) | ch в шотландском «loch» или h в английском «ha! " или, чаще, тонкое сочетание этих двух (то есть, не такое гортанное, как шотландское озеро) |
| (без звука) | без произношения, если h появляется между буквами c или g и e или i (che, чи, ге, ги); c и g палатализованы | |
| I i | /i / | i в "машинном" |
| /j / | y в "да" | |
| / ʲ / | Обозначает палатализацию предшествующего согласного (когда в конце слова и без ударения, в некоторых составных словах, таких как oricum, и в комбинациях chia, chio, chiu, ghia, ghio, ghiu) | |
| Î î (i с циркумфлексом ) | /ɨ / | Идентично Â, см. выше, используется в начале и в конце слова по эстетическим соображениям, например, "выучить" = "a învăța"; "убить" = "a omorî" |
| J j | /ʒ / | s в "сокровище" |
| K k | /k / | c в «сканировании» (смягчено перед e и i) |
| L l | /l / | l в «хромоте» |
| M m | /m / | m во «рту» |
| N n | /n / | n на «севере» |
| O o | /o / | o на «этаже» |
| / o̯ /, / ɔ̯ / | перед a - полусловонный / o /; если не предшествует a согласная становится / w / | |
| P p | /p / | p в «пятне» |
| Q q | /k / | k в «котелке» (qu звучит как / kw /, / kv / или / kʲ /) |
| R r | /r / | альвеолярная трель или коснитесь |
| S s | /s / | s в "песне" |
| Ș ș (s с запятой ) | /ʃ / | sh in " покупка " |
| T t | /t / | t в" камне " |
| Ț ț (t с запятая ) | /ts / | zz в «пицце», но с большим акцентом на «ss» |
| U u | /u / | u в «group» |
| /w / | w в «cow» | |
| /y / | французском u или немецком ü (закругленный гласный переднего ряда ) - в некоторых заимствованиях из французского: ecru, tul | |
| V v | /v / | v в «видении» |
| W w | /v / | v в «видении» |
| /w / | w на «западе» | |
| /u / | oo в «ложке» (wee, wi, которые произносятся / uj / в заимствованиях из английского, поскольку / wi / не существует в румынском языке) | |
| X x | / ks / | x в "шести" |
| / ɡz / | x в "example" | |
| Y y | /j / | y в "yes" |
| /i / | i в "машине « | |
| Z z | /z / | z в« застежке-молнии » |
См. Запятая ниже (ș и ț) по сравнению с седилем (ş и ţ).
 Pre- (вверху) и Уличные знаки после 1993 года (внизу) в Бухаресте, показывающие два разных написания одного и того же имени
Pre- (вверху) и Уличные знаки после 1993 года (внизу) в Бухаресте, показывающие два разных написания одного и того же имени Румынский орфография без акцентов и диакритических знаков - это второстепенные символы, добавленные к буквам (т.е. основные глифы ), чтобы изменить их произношение или различать слова. Однако в румынском алфавите есть пять специальных букв (связанных с четырьмя разными звуками), которые образуются путем изменения других латинских букв; строго говоря, эти буквы функционируют как основные глифы сами по себе, а не буквы с диакритическими знаками, но их часто называют последними.
Буква â употребляется исключительно в середине слов; его версия majuscule встречается только в надписях, написанных заглавными буквами.
Написание букв ș и ț с седилем вместо запятой считается в Румынской академии неправильным. В румынских произведениях, в том числе в книгах, созданных для обучения детей письму, запятая и седиль рассматриваются как разновидности шрифта. См. Unicode и HTML ниже.
Буквы î и â фонетически и функционально идентичны. Причина использования обоих из них - историческая, указывающая на латинское происхождение языка.
В течение нескольких десятилетий до реформы правописания в 1904 году для обозначения одной и той же фонемы использовалось четыре или пять букв (â, ê, î, û, а иногда и ô), согласно этимологическому правилу. Все они использовались для обозначения гласного / ɨ /, к которому сходились оригинальные латинские гласные, написанные с циркумфлексами. Реформа 1904 г. оставила только две буквы, â и î, выбор которых соответствовал правилам, которые несколько раз менялись в течение 20-го века.
В течение первой половины столетия правилом было использование î в начале слова и в конце слова, а â во всех остальных местах. Были исключения, предполагающие использование î во внутренних позициях, когда слова объединялись или производились с префиксами или суффиксами. Например, прилагательное urît «уродливый» было написано с î, потому что оно происходит от глагола a urî «ненавидеть».
В 1953 году, в коммунистическую эпоху, Румынская академия удалила букву â, заменив ее на î везде, включая название страны, которая должна была пишется Romînia. Первое условие совпало с официальным обозначением страны как Народная Республика, что означало, что ее полное название было Republica Populară Romînă. Незначительная реформа орфографии в 1964 году вернула букву â, но только в написании român «румынский» и всех его производных, включая название страны. Таким образом, Социалистическая Республика, провозглашенная в 1965 году, ассоциируется с написанием Republica Socialistă România.
Вскоре после падения правительства Чаушеску, Румынская академия решила вновь ввести â с 1993 года и далее, отменив последствия орфографической реформы 1953 года и по существу вернув к правилам 1904 г. (с некоторыми отличиями). Этот шаг был публично оправдан как исправление либо коммунистического нападения на традиции, либо советского влияния на румынскую культуру, а также как возврат к традиционному правописанию, несущему отпечаток латинского происхождения языка. Политический контекст в то время, однако, заключался в том, что Румынская Академия в значительной степени рассматривалась как коммунистическое и коррумпированное учреждение - Николае Чаушеску и его жена Елена были ее почетными членами, а членство находился под контролем коммунистической партии. Таким образом, реформа орфографии 1993 года рассматривалась как попытка Академии порвать со своим коммунистическим прошлым. Академия пригласила национальное сообщество лингвистов, а также иностранных лингвистов, специализирующихся на румынском языке, для обсуждения проблемы; когда они в подавляющем большинстве яростно выступили против реформы орфографии, их позиция была явно отклонена как слишком научная.
Согласно реформе 1993 года выбор между î и â, таким образом, снова основан на правиле, которое не является строго этимологическим, ни фонологическим, а позиционным и морфологическим. Звук всегда записывается как â, за исключением начала и конца слов, где вместо этого следует использовать î. Исключения включают имена собственные, где использование букв заморожено, в зависимости от того, какими они могут быть, и составные слова, каждый компонент которых по отдельности подчиняется правилу (например, ne- + î ndemânatic → ne î ndemânatic «неуклюжий», а не * ne â ndemânatic). Однако это исключение больше не применяется к словам, полученным с суффиксами, в отличие от нормы 1904 года; например, то, что было написано urît после 1904 года, стало urât после 1993 года.
Хотя реформа продвигалась как средство показать латинское происхождение румынского языка, статистически только некоторые из слов, написанных с â, в соответствии с реформой 1993 года фактически происходят от латинских слов, имеющих в соответствующей позиции букву a. Фактически, это включает в себя большое количество слов, которые содержат i в оригинальной латыни и аналогичным образом написаны с i в их итальянских или испанских аналогах. Примеры включают rîu «река», от латинского rivus (ср. испанский río), теперь пишется как râu; наряду с rîde < ridere, sîn < sinus, strînge < stringere, lumînare < luminaria, etc.
В то время как орфографическая норма 1993 года является обязательной в румынском образовании и официальных публикациях, и постепенно большинство других изданий начали использовать ее, все еще есть отдельные лица, публикации и издательства, предпочитающие предыдущую орфографическую норму или собственная смешанная гибридная система. Среди них - еженедельный культурный журнал Dilema Veche и ежедневная Gazeta Sporturilor, в то время как некоторые издания позволяют авторам выбирать любую орфографическую норму; в их число входят România literară, журнал Союза писателей Румынии и издательства, такие как Polirom. Словари, грамматики и другие лингвистические работы также публиковались с использованием î и sînt спустя много времени после реформы 1993 года.
В конечном счете, конфликт является результатом двух разных лингвистических рассуждений относительно того, как писать / ɨ /. Выбор â происходит от того, что он является самым средним или центральным из пяти гласных (официальная болгарская латинизация использует ту же логику, выбирая вместо ъ, в результате чего название страны пишется как Balgariya; а также Европейская португальская гласная / ɐ / для упомянутого выше), тогда как î - это попытка выбрать латинскую букву, которая наиболее интуитивно записывает звук / ɨ / (аналогично тому, как польский использует букву y).
Хотя стандарт Румынской академии требует использования запятой ниже варианты звуков / ʃ / и / t͡s /, варианты седиль по-прежнему широко используются. Во многих печатных и онлайн-текстах все еще неправильно используются "s с седилем " и "t с седилем ". Такое положение дел связано с первоначальным отсутствием стандартизации глифов, усугубляемым отсутствием поддержки компьютерных шрифтов для вариантов с запятыми ниже (подробности см. В разделе Unicode).
Отсутствие поддержки диакритических знаков запятой было исправлено в текущих версиях основных операционных систем: Windows Vista или новее, дистрибутивах Linux после 2005 года и поддерживаемых в настоящее время версиях Mac OS. В соответствии с требованиями Европейского Союза Microsoft выпустила обновление шрифта для исправления этого недостатка в Windows XP в начале 2007 года, вскоре после присоединения Румынии к Европейскому Союзу.
 Старый Бухарест крышка люка inscr ibed согласно этимологически склонному к тому времени написанию, которое читается как BUCURESCI CANALISARE (что означает канализация Бухареста). Сравните с сегодняшним BUCUREȘTI CANALIZARE.
Старый Бухарест крышка люка inscr ibed согласно этимологически склонному к тому времени написанию, которое читается как BUCURESCI CANALISARE (что означает канализация Бухареста). Сравните с сегодняшним BUCUREȘTI CANALIZARE. До реформы орфографии 1904 года было несколько дополнительных букв с диакритическими знаками.
Использование этих букв не было полностью принято даже до 1904 года, поскольку в некоторых публикациях (например, Timpul и Universul ) использовалось упрощенный подход, напоминающий сегодняшнее письмо на румынском языке.
Как и в других языках, острый акцент иногда используется в румынских текстах для обозначения ударения гласный в некоторых словах. Такое использование часто встречается в словарных заглавных словах, но также иногда встречается в тщательно отредактированных текстах, чтобы устранить неоднозначность между омографами, которые также не являются омофонами, например, чтобы различать cópii («копии») и copíi («дети»), éra («эпоха») и erá («был»), ácele («иглы») и acéle («те») и т. д. Ударение также различает омографические формы глаголов, такие как încúie и încuié («он запирает» и «он запирает»).
В некоторых заимствованиях сохранены диакритические знаки: bourrée, pietà. Иностранные имена также обычно пишутся с их оригинальными диакритическими знаками: Bâle, Molière, даже когда острый акцент может быть ошибочно истолкован как ударение, как в István или Gérard. Однако часто используемые иностранные названия, такие как названия городов или стран, часто пишутся без диакритических знаков: Богота, Панама, Перу.
 Широко распространенное неправильное использование Румынские диакритические знаки с примерами
Широко распространенное неправильное использование Румынские диакритические знаки с примерами Стандарт кодировки символов ISO 8859 изначально определял единую кодовую страницу для всей Центральной и Восточной Европы - ISO 8859-2. Эта кодовая страница включает только «s» и «t» с седильями. Юго-Восточная Европа ISO 8859-16 включает «s» и «t» с запятой ниже в тех же местах, где «s» и «t» с седилем были в ISO 8859-2. Кодовая страница ISO 8859-16 стала стандартом после того, как Unicode получил широкое распространение, поэтому производители программного обеспечения в значительной степени игнорировали ее.
Румынские буквы с акцентом на циркумфлексе и бреве были частью стандарта Юникод с момента его создания, как и варианты седиль для s и t. Ș и ț (варианты с запятыми ниже) были добавлены в Unicode версии 3.0. Начиная с версии Unicode 3.0 и до версии 5.1, символы, использующие седилу, были определены стандартом Unicode как «используемые как в турецких, так и в румынских данных», и что «вариант глифа с запятой ниже предпочтительнее для румынского языка»; В отношении недавно закодированных символов, использующих запятую, было сказано, что они должны использоваться, «когда требуется отдельная запятая под формой». В Unicode 5.2 прямо указано, что «форма с седилем предпочтительнее в турецком языке, а форма с запятой ниже предпочтительнее в румынском», при этом упоминается (возможно, по историческим причинам), что «в турецком и румынском языках седиль и запятая ниже иногда заменяют друг друга ».
Широкому распространению в течение нескольких лет препятствовало отсутствие шрифтов, обеспечивающих новые символы. В мае 2007 года, через пять месяцев после того, как Румыния (и Болгария) присоединились к ЕС, Microsoft выпустила обновленные шрифты, которые включают все официальные глифы румынского (и болгарского ) алфавита. Это обновление шрифтов предназначалось для Windows XP SP2, Windows Server 2003 и Windows Vista. Подмножество Unicode, наиболее широко поддерживаемое в системах Microsoft Windows, Windows Glyph List 4, по-прежнему не включает варианты S и T с запятыми ниже
| Фонема | С запятой ( официальный) | С седилем | ||||
|---|---|---|---|---|---|---|
| Символ | Unicode. позиция. (шестнадцатеричный) | HTML-объект | Символ | Unicode. позиция. (шестнадцатеричная) | HTML-объект | |
| / ʃ / | Ș | 0218 | Ș или Ș | Ş | 015E | Ş или Ş или Ş |
| ș | 0219 | ș или ș | ş | 015F | ş или ş или ş | |
| / t͡s / | Ț | 021A | Ț или Ț | Ţ | 0162 | Ţ или Ţ или Ţ |
| ț | 021B | ț или ț | ţ | 0163 | ţ или ţ или ţ | |
Гласные с диакритические знаки кодируются следующим образом:
| Фонема | Символ | Unicode. позиция. (шестнадцатеричный) | HTML-объект |
|---|---|---|---|
| / ə / | Ă | 0102 | Ă или Ă или Ă |
| ă | 0103 | ă или ă или ă | |
| / ɨ / | Â | 00C2 | Â или Â или Â |
| â | 00E2 | â или â или â | |
| Î | 00CE | Î или Î или Î | |
| î | 00EE | î или î или î |
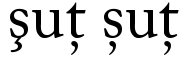 Несогласованные глифы седиль в Adobe Caslon (слева). Правильный рендеринг на румынском языке (справа) можно получить, активировав функцию OpenType
Несогласованные глифы седиль в Adobe Caslon (слева). Правильный рендеринг на румынском языке (справа) можно получить, активировав функцию OpenType GSUB / latn / ROM / locl, которая преобразует s с глифом седиллы в запятую ниже. Рендеринг справа визуально неотличим от рендеринга, полученного с помощью кодовых точек, указанных ниже запятыми для этого шрифта. Adobe Systems решила, что глифы Unicode "t с седилем" U + 0162/3 не используются ни в каких язык. (На самом деле он используется, но на очень небольшом количестве языков. T с седиллой существует как часть общего алфавита камерунских языков, в некоторых гагаузских орфографиях, в кабильском диалекте берберского языка и, возможно, в других местах.) Поэтому Adobe заменила глифы с буквой «t с запятой внизу» (U + 021A / B) во всех поставляемых ими шрифтах. Прискорбным последствием этого решения является то, что румынские документы, в которых используются (неофициальные) точки Unicode U + 015E / F и U + 0162/3 (для ș и ț), визуализируются в шрифтах Adobe визуально несовместимым образом с использованием «s с седилем»., но "t с запятой" (см. рисунок). Шрифты Linotype, которые поддерживают румынские глифы, в основном следуют этому соглашению.
Шрифты, представленные Microsoft в Windows Vista, также реализуют этот стандарт де-факто Adobe. Немногие шрифты Microsoft обеспечивают единообразный вид при использовании вариантов седиль; примечательными из них являются Tahoma, Verdana, Trebuchet MS, Microsoft Sans Serif и Segoe UI.
The free Шрифты DejaVu и Linux Libertine обеспечивают правильные и согласованные глифы в обоих вариантах. Шрифты Liberation Red Hat поддерживают только указанные ниже запятые варианты, начиная с версии 1.04, запланированной для включения в Fedora 10.
ROM / loclНекоторые шрифты OpenType от Adobe и все шрифты серии C Vista реализуют дополнительные Функция OpenType GSUB / latn / ROM / locl. Эта функция заставляет рендеринг "s с седилем" с использованием того же символа, что и "s с запятой ниже". Когда происходит это второе (но необязательное) переназначение, румынский текст Unicode отображается с глифами, запятыми ниже, независимо от вариантов кодовой точки.
К сожалению, большинство шрифтов OpenType Microsoft до Vista (Arial и т. Д.) Не реализуют функцию ROM / loclдаже после обновления шрифтов расширения Европейского Союза, поэтому старые документы будут выглядеть несовместимыми, как показано на рисунке слева. Выберите несколько шрифтов, например Verdana и Trebuchet MS не только единообразно ищут варианты седиль (после обновления для ЕС), но также выполняют одновременное переназначение седиль s и t на варианты с запятыми ниже, когда ROM / loclактивирован. Бесплатные шрифты DejaVu и Linux Libertine еще не предлагают эту функцию в своих текущих выпусках, но версии для разработки включают.
Pango поддерживает тег locl, начиная с версии 1.17. XeTeX поддерживает locl, начиная с версии 0.995. По состоянию на июль 2008 года очень немногие приложения Windows поддерживают тег функции locl. Из пакета Adobe CS3 только InDesign поддерживает его.
Статус поддержки румынского языка в бесплатных шрифтах, поставляемых с Fedora поддерживается на Fedoraproject.org.
Юникод также позволяет представлять диакритические знаки как отдельные , объединяющие диакритические знаки. Соответствующие акценты комбинирования - U + 0326 ОБЪЕДИНЕНИЕ ЗАПЯТЫЙ НИЖЕ и U + 0327 ОБЪЕДИНЕНИЕ СЕДИЛЬИ. Поддержка применения комбинированной запятой ниже к буквам S и T, возможно, плохо поддерживалась в коммерческих шрифтах в прошлом, но почти все современные шрифты могут успешно обрабатывать как Cedilla, так и запятую ниже для S и T. Как и для всех шрифтов, типографский качество может варьироваться, поэтому предпочтительнее использовать вместо него отдельные точки кода. Каждый раз, когда в документе используется комбинированный диакритический знак, используемый шрифт должен быть протестирован, чтобы подтвердить, что он отображается приемлемым образом.
LaTeX позволяет набирать текст на румынском языке с использованием седил Ş и Ţ, используя кодировку Cork. Варианты, указанные ниже запятыми, не полностью поддерживаются в стандартных 8-битных кодировках шрифтов TeX. Отсутствие стандарта (внутреннего представления символов LaTeX) для запятых под Ș и является частью проблемы. Метод ввода latin10пытается решить проблему, определяя акцент \ textcommabelow LICR. К сожалению, это не поддерживается методом ввода utf8.
Проблема может быть частично решена в документе LaTeX с использованием этих настроек, что позволит использовать ș, ț или их варианты седиль непосредственно в исходном коде LaTeX:
\ usepackage [latin10, utf8 ] {inputenc}% транслитерирует символы utf8 с помощью çedila в их представлении, указанном ниже запятой % ţ \ DeclareUnicodeCharacter {0162} {\ textcommabelow T}% Ţ% транслитерирует символы, указанные ниже запятой, utf8 в представление, указанное ниже запятой. \ DeclareUnicodeCharacter {0219} {\ textcommabelow s}% ș \ DeclareUnicodeCharacter}% \ Ș \ DeclareUnicodeCharacter {021B} {\ textcommabelow t}% ț \ DeclareUnicodeCharacter {021A} {\ textcommabelow T}% ȚПакет latin10состоит из глифов ниже запятых с наложением и буквы S и T. Этот метод подходит только для печати. В документах PDF, созданных таким образом, поиск или копирование текста не работают должным образом. В польской кодировке QX есть некоторая поддержка глифов, начинающихся с запятой, которые неправильно отображаются в LICR седиль, но также не хватает A breve (Ă), которое всегда должно быть составным, а значит, недоступным для поиска.
В шрифтах Latin Modern Type 1 буква T с запятой ниже находится под именем AGL / Tcommaaccent. Это противоречит обсуждавшемуся выше решению Adobe, в котором буква T с запятой ниже ставится в / Tcedilla. Как следствие, фиксированное сопоставление не может работать для всех шрифтов Type 1; каждый шрифт должен иметь собственное отображение. К сожалению, драйверы вывода TeX, такие как dvips, dvipdfm или внутренний PDF-драйвер pdfTeX, обращаются к глифам по имени AGL. Поскольку все упомянутые драйверы вывода не знают об этой особенности, проблема практически неразрешима для всех шрифтов. Как следствие, нужно использовать шрифты, которые включают отображение, которое не обходит TeX. Так обстоит дело с новым механизмом TeX XeTeX, который может использовать шрифты Unicode OpenType и не обходит карту Unicode шрифта.
Современные компьютерные операционные системы могут быть настроены для реализации стандартной румынской раскладки клавиатуры, чтобы можно было печатать на любой клавиатуре, как если бы это была румынская клавиатура.
В таких системах, как GNU / Linux, в которых используется система XCompose, румынские буквы могут быть набраны с нерумынской раскладки клавиатуры с использованием клавиши набора. Раскладка клавиатуры системы должна быть настроена для использования клавиши набора. (Как именно это выполняется, зависит от распределения.) Например, «левый Alt» часто используется в качестве клавиши создания.
Чтобы ввести букву с диакритическим знаком, удерживайте клавишу составления, пока набирается другая клавиша, указывающая метку, которую нужно применить, затем набирается основная буква. Например, при использовании английской (США) раскладки клавиатуры, чтобы получить ț, удерживайте нажатой клавишу создания, набирая точку с запятой ';', затем отпустите клавишу создания и введите 't'. Аналогичным образом могут применяться и другие знаки:
| буква | метка, клавиша | базовая буква | примечание |
|---|---|---|---|
| ț | ; | t | |
| ă | U | a | shift-u для U |
| î | ^ | i | shift-6 для ^ |
Существует румынский эквивалент англоязычного фонетического алфавита НАТО. Большинство кодовых слов - это имена людей, за исключением K, J, Q, W и Y. Буквы с диакритическими знаками (Ă, Â, Î, Ș, Ț) обычно передаются без диакритических знаков (A, A, I, S, Т).
| Word | IPA (неофициальный) | |
|---|---|---|
| A | Ana | /ˈa.na/ |
| B | Barbu | /ˈbar.bu/ |
| C | Константин | /kon.stanˈtin/ |
| D | Dumitru | /duˈmi.tru/ |
| E | Elena | /eˈle.na/ |
| F | Florea | / ˈFlo.re̯a / |
| G | Gheorghe | /ˈɡe̯or.ɡe/ |
| H | Haralambie | /ha.raˈlam.bi.e/ |
| I | Ion | / iˈon / |
| J | Jiu | / ʒiw / |
| K | kilogram | /ki.loˈɡram/ |
| L | Lazăr | /ˈla.zər/ |
| M | Мария | /maˈri.a/ |
| Word | IPA (неофициальный) | |
|---|---|---|
| N | Nicolae | /ni.koˈla.e/ |
| O | Olga | /ˈOl.ɡa/ |
| P | Петре | /ˈpe.tre/ |
| Q | Q | / kju / |
| R | Radu | /ˈra.du/ |
| S | Санду | /ˈSan.du/ |
| T | Tudor | /ˈtu.dor/ |
| U | Udrea | /ˈu.dre̯a/ |
| V | Vasile | /vaˈsi.le / |
| W | dublu V | /du.bluˈve/ |
| X | Xenia | /ˈkse.ni.a/ |
| Y | I grec | /ˈi.ɡrek/ |
| Z | Zamfir | /ˈzam.fir/ |