
Войти
 | |
| Разработчик (и) | Thomas Breuel, DFKI |
|---|---|
| Первоначальный выпуск | 9 апреля 2007 г.; 13 лет назад (2007-04-09) |
| Стабильный выпуск | 1.3.3 / 16 декабря 2017 г.; 2 года назад (16.12.2017) |
| Репозиторий | |
| Написано на | C ++ и Python |
| Операционная система | FreeBSD, Linux, Mac OS X |
| Тип | Оптическое распознавание символов |
| Лицензия | Лицензия Apache v2.0 |
| Веб-сайт | github.com / tmbdev / ocropy |
OCRopus - это бесплатный анализ документов и система оптического распознавания символов (OCR), выпущенная под лицензией Apache License v2.0 с очень модульной конструкцией с использованием интерфейсов командной строки.
OCRopus разрабатывается под руководством Томас Бреуэль из Немецкого исследовательского центра искусственного интеллекта в Кайзерслаутерне, Германия, при спонсорской поддержке Google.
OCRopus был специально разработан для использования в проектах оцифровки больших объемов книг, таких как Google Книги, Стажер et Archive или библиотеки. Будет поддерживаться большое количество языков и шрифтов. Однако его также можно использовать для настольных и офисных приложений или для приложений для людей с ослабленным зрением.
Сформированы основные компоненты OCRopus:
Для них доступны один или несколько скриптов составные части. модульный подход позволяет использовать отдельные рабочие процессы и обмениваться отдельными шагами.
По умолчанию OCRopus поставляется с моделью для текста на английском языке и моделью для текста на языке Fraktur. Эти модели относятся к сценарию и в значительной степени не зависят от реального языка. Новые персонажи или языковые варианты можно обучать как новых, так и дополнительно.
Распознавание недавнего текста основано на рекуррентных нейронных сетях (LSTM ) и не требует языковой модели. Это позволяет обучать независимые от языка модели, для которых были показаны хорошие результаты распознавания для английского, немецкого и французского языков одновременно. Помимо латинского алфавита, есть результаты для других алфавитов, таких как санскрит, урду, деванагари и греческий.
Очень хорошие показатели обнаружения могут быть достигнуты при соответствующем обучении. Эти дополнительные усилия особенно полезны для сложных документов или сценариев, которые сегодня уже не используются, и которые не являются предметом внимания другого программного обеспечения для распознавания текста.
9 апреля 2007 г. было объявлено о выпуске OCRopus как спонсируемый Google проект по разработке передовых технологий распознавания текста. Финансирование было предоставлено сроком на три года и охватывало, в частности, кандидатские и постдокторские должности в DFKI и Университете Кайзерслаутерна. В свою очередь, OCRopus также использовался для автоматического распознавания текста в Поиск книг Google. Лицензирование по лицензии с открытым исходным кодом было сделано с самого начала, чтобы облегчить сотрудничество между промышленными и академическими исследованиями. OCRopus получил дополнительное финансирование от Фонда Эндрю У. Меллона и BMBF.
. Первая альфа-версия 0.1 была выпущена 22 октября 2007 г., а в период с декабря 2007 г. по май 2009 г. последовало несколько предварительных релизов. достижение стабильной версии 0.4.4 в марте 2010. Первоначально программное обеспечение было разработано на C ++, Python и Lua с Jam как система сборки . Был проведен полный рефакторинг исходного кода в модулях Python, который был выпущен в версии 0.5 (июнь 2012 г.).
Первоначально Tesseract использовался как единственное средство распознавания текста. модуль. С 2009 года (версия 0.4) Tesseract поддерживался только как плагин. Вместо этого был использован распознаватель текста собственной разработки (также сегментный). Этот распознаватель затем использовался вместе с OpenFST для языкового моделирования после этапа распознавания. С 2013 года было предложено дополнительное распознавание с помощью рекуррентных нейронных сетей (LSTM ), которое с выпуском версии 1.0 в ноябре 2014 года стало единственным распознавателем.
Исходный код управляется через GitHub, поддерживается и разрабатывается сообществом разработчиков. Текущая версия OCRopus - 1.3.3 (декабрь 2017 г.).
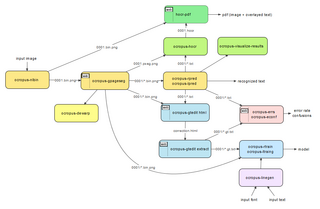 Схема рабочего процесса отдельных инструментов командной строки из OCRopus.
Схема рабочего процесса отдельных инструментов командной строки из OCRopus. OCRopus можно использовать из командной строки. После установки его можно вызвать, указав входные изображения. Он будет выводить распознанный текст в стандартный вывод напрямую или записывать его в виде кода hOCR (HTML ) в файлы, из которых он затем может быть преобразован в PDF-файл с возможностью поиска. Если требуется более точное управление, в командной строке можно указать параметры для выполнения определенных операций (например, распознавания отдельной строки).
Пример вызова OCRopus для распознавания текста на изображении:
# выполнить бинаризацию ocropus-nlbin tests / ersch.png -o book # выполнить анализ макета страницы ocropus-gpageseg book / 0001.bin.png # выполнить распознавание текстовой строки (с моделью fraktur) ocropus-rpred -m models / fraktur.pyrnn. gz book / 0001 / *. bin.png # генерировать HTML-вывод ocropus-hocr book / 0001.bin.png -o book / 0001.htmlДругие инструменты сосредоточены на обучающей части OCRopus. Существуют модели OCRopus для извлечения текста из латинского, греческого, кириллического и индийского алфавитов.