
Войти
В теории информации код с низкой плотностью проверки на четность ( LDPC ) - это код с линейной коррекцией ошибок, метод передачи сообщения по каналу передачи с шумом. LDPC строится с использованием разреженного графа Таннера (подкласс двудольного графа ). Коды LDPC - это коды, приближающиеся к емкости, что означает, что существуют практические конструкции, которые позволяют устанавливать порог шума очень близко к теоретическому максимуму ( предел Шеннона ) для симметричного канала без памяти. Порог шума определяет верхнюю границу шума канала, до которого вероятность потери информации может быть минимальной по желанию. Используя методы итеративного распространения уверенности, коды LDPC могут быть декодированы во времени, линейном по отношению к длине их блока.
Коды LDPC находят все более широкое применение в приложениях, требующих надежной и высокоэффективной передачи информации по линиям с ограниченной полосой пропускания или обратным каналом в присутствии искажающего шума. Реализация кодов LDPC отстала от других кодов, особенно турбокодов. Срок действия фундаментального патента на турбокоды истек 29 августа 2013 года.
Коды LDPC также известны как коды Галлагера в честь Роберта Г. Галлагера, который разработал концепцию LDPC в своей докторской диссертации в Массачусетском технологическом институте в 1960 году.
Коды LDPC, впервые разработанные Галлагером в 1963 году, были непрактичными для реализации, пока его работа не была заново открыта в 1996 году. Турбокоды, еще один класс кодов, приближающихся к емкости, открытый в 1993 году, стали предпочтительной схемой кодирования в конце 1990-х годов, используемой для такие приложения, как Deep Space Network и спутниковая связь. Однако достижения в области кодов проверки на четность с низкой плотностью показали, что они превосходят турбокоды с точки зрения минимального уровня ошибок и производительности в диапазоне более высоких кодовых скоростей, в результате чего турбокоды лучше подходят только для более низких кодовых скоростей.
В 2003 году код LDPC в стиле нерегулярного повторного накопления (IRA) превзошел шесть турбокодов и стал кодом с исправлением ошибок в новом стандарте DVB-S2 для спутниковой передачи цифрового телевидения. Отборочная комиссия DVB-S2 сделала оценки сложности декодера для предложений Turbo Code, используя гораздо менее эффективную архитектуру последовательного декодера, чем архитектуру параллельного декодера. Это вынудило предложения Turbo Code использовать размеры кадра порядка половины размера кадра предложений LDPC.
В 2008 годе LDPC бить сверточные турбокоды как прямая коррекция ошибок системы (ПИО) для МСЭ-Т G.hn стандарта. G.hn предпочел коды LDPC турбокодам из-за их меньшей сложности декодирования (особенно при работе со скоростями передачи данных, близких к 1,0 Гбит / с), а также потому, что предложенные турбокоды демонстрируют значительный минимальный уровень ошибок в желаемом диапазоне работы.
Коды LDPC также используются для 10GBASE-T Ethernet, который передает данные со скоростью 10 гигабит в секунду по кабелям витой пары. С 2009 года коды LDPC также являются частью стандарта Wi-Fi 802.11 в качестве дополнительной части 802.11n и 802.11ac в спецификации PHY с высокой пропускной способностью (HT).
Некоторые системы OFDM добавляют дополнительную внешнюю коррекцию ошибок, которая исправляет случайные ошибки («минимальный уровень ошибок»), которые преодолевают внутренний код коррекции LDPC даже при низкой частоте ошибок по битам. Например: код Рида-Соломона с кодированной модуляцией LDPC (RS-LCM) использует внешний код Рида-Соломона. Стандарты DVB-S2, DVB-T2 и DVB-C2 используют внешний код кода BCH для устранения остаточных ошибок после декодирования LDPC.
Коды LDPC функционально определяются разреженной матрицей проверки на четность. Эта разреженная матрица часто генерируется случайным образом с учетом ограничений разреженности - конструкция кода LDPC обсуждается позже. Эти коды были впервые разработаны Робертом Галлагером в 1960 году.
Ниже приведен фрагмент графа примера кода LDPC с использованием обозначения графа факторов Форни. В этом графе n узлов переменных в верхней части графа соединены с ( n - k ) узлами ограничений в нижней части графика.
Это популярный способ графического представления ( n, k ) кода LDPC. Биты действительного сообщения, помещенные в буквы T в верхней части графика, удовлетворяют графическим ограничениям. В частности, все линии, соединяющиеся с узлом переменной (прямоугольник со знаком '='), имеют одинаковое значение, и все значения, соединяющиеся с узлом фактора (прямоугольник со знаком '+'), должны суммироваться по модулю два до нуля (в другими словами, они должны быть суммированы до четного числа; или должно быть четное число нечетных значений).
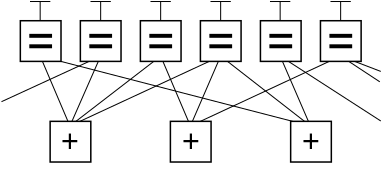
Игнорируя любые строки, выходящие за пределы изображения, существует восемь возможных шестибитных строк, соответствующих допустимым кодовым словам: (т.е. 000000, 011001, 110010, 101011, 111100, 100101, 001110, 010111). Этот фрагмент кода LDPC представляет трехбитовое сообщение, закодированное как шесть битов. Здесь используется избыточность для увеличения шансов восстановления после ошибок канала. Это линейный код (6, 3) с n = 6 и k = 3.
Снова игнорируя строки, выходящие за пределы изображения, матрица проверки на четность, представляющая этот фрагмент графа, имеет вид
В этой матрице каждая строка представляет одно из трех ограничений проверки на четность, а каждый столбец представляет один из шести битов принятого кодового слова.
В этом примере восемь кодовых слов можно получить, поместив матрицу проверки на четность H в эту форму с помощью основных операций со строками в GF (2) :
Шаг 1: H.
Шаг 2: Ряд 1 добавлен к ряду 3.
Шаг 3: строки 2 и 3 меняются местами.
Шаг 4: Ряд 1 добавляем к ряду 3.
Из этого порождающая матрица G может быть получена как (с учетом того, что в частном случае это двоичный код), или, в частности:
Наконец, умножая все восемь возможных 3-битных строк на G, получают все восемь действительных кодовых слов. Например, кодовое слово для битовой строки «101» получается следующим образом:
где - символ умножения по модулю 2.
Для проверки, пространство строк G ортогонально H такое, что
Битовая строка «101» находится как первые 3 бита кодового слова «101011».
На рисунке 1 показаны функциональные компоненты большинства кодеров LDPC.
 Рис. 1. Кодер LDPC
Рис. 1. Кодер LDPC Во время кодирования кадра биты входных данных (D) повторяются и распределяются по набору составляющих кодеров. Составляющие кодеры обычно являются накопителями, и каждый накопитель используется для генерации символа четности. Единственная копия исходных данных (S 0, K-1 ) передается с битами четности (P), чтобы составить кодовые символы. S битов от каждого составляющего кодера отбрасываются.
Бит четности может использоваться в другом составляющем коде.
В примере с использованием кода DVB-S2 со скоростью 2/3 размер кодированного блока составляет 64800 символов (N = 64800) с 43200 битами данных (K = 43200) и 21600 битами четности (M = 21600). Каждый составляющий код (контрольный узел) кодирует 16 бит данных, за исключением первого бита четности, который кодирует 8 битов данных. Первые 4680 битов данных повторяются 13 раз (используются в 13 кодах четности), а остальные биты данных используются в 3 кодах четности (нерегулярный код LDPC).
Для сравнения, в классических турбокодах обычно используются два составляющих кода, сконфигурированных параллельно, каждый из которых кодирует весь входной блок (K) битов данных. Эти составные кодеры представляют собой рекурсивные сверточные коды (RSC) средней глубины (8 или 16 состояний), которые разделены перемежителем кода, который перемежает одну копию кадра.
Код LDPC, напротив, использует параллельно множество составляющих кодов (аккумуляторов) низкой глубины, каждый из которых кодирует только небольшую часть входного кадра. Многие составляющие коды можно рассматривать как множество «сверточных кодов» с низкой глубиной (2 состояния), которые связаны посредством операций повтора и распределения. Операции повтора и распределения выполняют функцию перемежителя в турбо-коде.
Возможность более точного управления соединениями различных составляющих кодов и уровнем избыточности для каждого входного бита дает большую гибкость в разработке кодов LDPC, что в некоторых случаях может привести к лучшей производительности, чем турбокоды. Турбо-коды по-прежнему работают лучше, чем LDPC, при низких скоростях кода, или, по крайней мере, конструкция хорошо работающих кодов с низкой скоростью проще для турбо-кодов.
На практике оборудование, которое формирует аккумуляторы, повторно используется в процессе кодирования. То есть, как только первый набор битов четности сгенерирован и биты четности сохранены, то же самое аппаратное накопительное оборудование используется для генерации следующего набора битов четности.
Как и в случае с другими кодами, декодирование с максимальной вероятностью кода LDPC в двоичном симметричном канале является NP-полной проблемой. Оптимальное декодирование NP-полного кода любого полезного размера нецелесообразно.
Однако субоптимальные методы, основанные на итеративном декодировании с распространением убеждений, дают отличные результаты и могут быть практически реализованы. Субоптимальные методы декодирования рассматривают каждую проверку четности, которая составляет LDPC, как независимый код одиночной проверки четности (SPC). Каждый код SPC декодируется отдельно с использованием методов программного ввода -вывода (SISO), таких как SOVA, BCJR, MAP и других их производных. Информация мягкого решения от каждого декодирования SISO перекрестно проверяется и обновляется с помощью других избыточных декодирований SPC того же информационного бита. Затем каждый код SPC снова декодируется с использованием обновленной информации мягкого решения. Этот процесс повторяется до тех пор, пока не будет получено допустимое кодовое слово или не будет исчерпано декодирование. Этот тип декодирования часто называют декодированием суммарного произведения.
Декодирование кодов SPC часто упоминается как обработка «узла проверки», а перекрестная проверка переменных часто упоминается как обработка «узла переменной».
В практической реализации декодера LDPC наборы кодов SPC декодируются параллельно для увеличения пропускной способности.
Напротив, распространение убеждений по каналу двоичного стирания особенно просто, если оно состоит из итеративного удовлетворения ограничений.
Например, предположим, что действительное кодовое слово 101011 из приведенного выше примера передается по двоичному каналу стирания и принимается со стертыми первым и четвертым битами, что дает «01» 11. Поскольку переданное сообщение должно удовлетворять кодовым ограничениям, сообщение может быть представлено путем записи полученного сообщения в верхней части графа факторов.
В этом примере первый бит еще не может быть восстановлен, потому что все связанные с ним ограничения имеют более одного неизвестного бита. Чтобы продолжить декодирование сообщения, необходимо определить ограничения, связанные только с одним из стертых битов. В этом примере достаточно только второго ограничения. Рассматривая второе ограничение, четвертый бит должен быть равен нулю, поскольку только ноль в этой позиции будет удовлетворять ограничению.
Затем эта процедура повторяется. Новое значение четвертого бита теперь можно использовать вместе с первым ограничением для восстановления первого бита, как показано ниже. Это означает, что первый бит должен быть единицей, чтобы удовлетворить крайнему левому ограничению.

Таким образом, сообщение можно декодировать итеративно. Для других моделей каналов сообщения, передаваемые между переменными узлами и проверочными узлами, являются действительными числами, которые выражают вероятность и вероятность веры.
Этот результат может быть подтвержден путем умножения исправленного кодового слова r на матрицу проверки на четность H :
Поскольку результатом z ( синдромом ) этой операции является нулевой вектор размером 3 × 1, результирующее кодовое слово r успешно проверяется.
После завершения декодирования исходные биты «101» сообщения могут быть извлечены путем просмотра первых 3 бита кодового слова.
Хотя этот пример стирания является иллюстративным, он не показывает использование декодирования с мягким решением или передачи сообщений с мягким решением, которые используются практически во всех коммерческих декодерах LDPC.
В последние годы также было проведено много работы по изучению эффектов альтернативных расписаний для обновления переменных-узлов и ограничений-узлов. Первоначальный метод, который использовался для декодирования кодов LDPC, был известен как лавинная рассылка. Этот тип обновления требовал, чтобы перед обновлением узла переменной необходимо было обновить все узлы ограничений, и наоборот. В более поздних работах Вила Касадо и др. были изучены альтернативные методы обновления, при которых переменные узлы обновляются новейшей доступной информацией о проверочных узлах.
Интуиция, лежащая в основе этих алгоритмов, заключается в том, что узлы переменных, значения которых изменяются больше всего, должны быть обновлены в первую очередь. Высоконадежные узлы, величина логарифмического отношения правдоподобия (LLR) которых велика и существенно не меняется от одного обновления к другому, не требуют обновлений с той же частотой, что и другие узлы, знак и величина которых колеблются в более широких пределах. Эти алгоритмы планирования показывают более высокую скорость сходимости и более низкие минимальные уровни ошибок, чем те, которые используют лавинную рассылку. Эти более низкие минимальные уровни ошибок достигаются за счет способности алгоритма информированного динамического планирования (IDS) преодолевать захват наборов близких кодовых слов.
Когда используются алгоритмы планирования без заводнения, используется альтернативное определение итерации. Для ( n, k ) кода LDPC со скоростью k / n полная итерация происходит, когда n переменных и n - k узлов ограничений были обновлены, независимо от порядка, в котором они были обновлены.
Для больших размеров блоков коды LDPC обычно создаются путем предварительного изучения поведения декодеров. Поскольку размер блока стремится к бесконечности, можно показать, что декодеры LDPC имеют порог шума, ниже которого надежно достигается декодирование, а выше которого декодирование не достигается, что в просторечии называется эффектом обрыва. Этот порог можно оптимизировать, найдя наилучшую пропорцию дуг из контрольных узлов и дуг из переменных узлов. Примерный графический подход к визуализации этого порога - диаграмма ВЫХОДА.
Построение конкретного кода LDPC после этой оптимизации делится на два основных типа методов:
Построение с помощью псевдослучайного подхода основывается на теоретических результатах, которые для большого размера блока случайное построение дает хорошие характеристики декодирования. В общем, псевдослучайные коды имеют сложные кодеры, но псевдослучайные коды с лучшими декодерами могут иметь простые кодеры. Часто применяются различные ограничения, чтобы гарантировать, что желаемые свойства, ожидаемые при теоретическом пределе бесконечного размера блока, возникают при конечном размере блока.
Комбинаторные подходы могут использоваться для оптимизации свойств кодов LDPC небольшого размера или для создания кодов с помощью простых кодировщиков.
Некоторые коды LDPC основаны на кодах Рида – Соломона, например код RS-LDPC, используемый в стандарте 10 Gigabit Ethernet. По сравнению со случайно сгенерированными кодами LDPC, структурированные коды LDPC, такие как код LDPC, используемый в стандарте DVB-S2, могут иметь более простое и, следовательно, более дешевое оборудование - в частности, коды, построенные таким образом, что матрица H является циркулянтной матрицей.
Еще один способ построения LDPC-кодов - использовать конечную геометрию. Этот метод был предложен Y. Kou et al. в 2001.
Коды LDPC можно сравнить с другими мощными схемами кодирования, например, с турбокодами. С одной стороны, на производительность турбокодов BER влияют ограничения младших кодов. Коды LDPC не имеют ограничений по минимальному расстоянию, что косвенно означает, что коды LDPC могут быть более эффективными при относительно больших кодовых скоростях (например, 3/4, 5/6, 7/8), чем турбокоды. Однако коды LDPC не являются полной заменой: турбокоды - лучшее решение при более низких скоростях кода (например, 1/6, 1/3, 1/2).






 ,
,

