
Войти
A Байесовская сеть (также известная как байесовская сеть, сеть убеждений, или сеть решений ) представляет собой вероятностную графическую модель, которая представляет набор чисел и их условных зависимостей через направленную ациклическую график (DAG). Байесовские сети идеально подходят для анализа произошедшего события и прогнозирования вероятности того, что любая из нескольких известных причин является способствующим фактором. Например, байесовская сеть может представлять вероятностные отношения между болезнями и симптомами. Возможности наличия различных заболеваний.
Эффективные алгоритмы выполняют вывод и обучение в байесовских сетях. Байесовские сети, моделирующие последовательность (например, речевых сигналов или белковых последовательностей ), называются динамическими байесовскими сетями. Обобщения байесовских сетей, которые могут решать проблемы принятия решений в условиях неопределенности, называются диаграммами влияния.
Формально байесовские сети - это ориентированные ациклические графы (DAG), узлы которые представляют переменные в байесовском смысле: они могут быть наблюдаемыми величинами, скрытыми переменными, неизвестные параметры или гипотезы. Ребра предоставьте собой условные зависимости; узлы, которые не связаны (никакой путь не соединяет один узел с другими), предоставьте переменные, которые условно независимы от друга. Каждый узел с функцией вероятности , которая принимает в качестве входных данных набор значений для родительских число узла и дает (в качестве выходных данных) вероятность (или распределение вероятностей, если применимо) перемен., представленной узлом. Например, если 

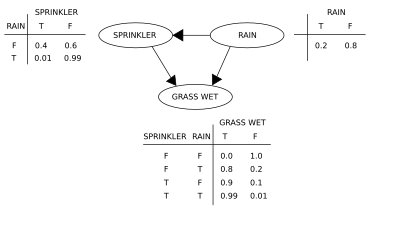 Простая байесовская сеть с таблицами условной вероятности
Простая байесовская сеть с таблицами условной вероятности Два события могут привести к намоканию трав: активная поливальная машина или дождь. Дождь имеет прямое влияние на использование дождевателя (а именно, когда идет дождь, дождеватель обычно не работает). Эту ситуацию можно смоделировать с помощью байесовской сети (показано справа). Каждая переменная имеет два значения: T (истина) и F (ложь).
Совместная функция вероятности :

где G = «Трава мокрая (истина / ложь)», S = «Спринклер включен (истина / ложь)» и R = «Дождь (истина / ложь)».
Модель может ответить на вопросы о наличии причины при наличии эффекта (так называемая обратная вероятность), например: «Какова вероятность того, что идет дождь, если трава мокрая?» с помощью формулы условной вероятности и суммирования по всем мешающим переменным :

Использование разложения для совместной функции вероятности 

Числовые результаты (с индексами соответствующих чисел) равны

Чтобы ответить на интервенционный вопрос, например, "Какова вероятность того, что пойдет дождь, учитывая, что мы намочить траву? "ответ имеет функцию совместного распределения после вмешательства

, полученное путем удаления множителя 

Чтобы предсказать влияние включения спринклера:

с членом 
Эти прогнозы могут оказаться невозможными с учетом ненаблюдаемых переменных, как в большинстве оценок политики. Эффект действия 

Черный ход - это путь, который заканчивается стрелкой в X. Наборы, удовлетворяющие критерию черного хода, называются «достаточными» или «допустимыми». Например, множество Z = R допустимо для предсказания влияния S = T на G, потому что R d-разделяет (единственный) черный ход S ← R → G. Однако, если S не соблюдается, никакие другие набор d отделяет этот путь, и эффект включения разбрызгивателя (S = T) на траве (G) не может быть предсказан на пассивных наблюдений. В этом случае P (G | do (S = T)) не идентифицирован ». Это отражает тот факт, что при отсутствии предполагаемой зависимости S и G обусловлена причинной связью или ложной (очевидная зависимость, вызывающая из общей причины, R). (см. парадокс Симпсона )
Чтобы определить идентифицирует ли причинную связь из произвольной байесовской сети с ненаблюдаемыми переменными, можно использовать три правила «выполнить-исчисления» и проверить, проверить, удалить ли можно удалить все члены из выражения этих отношений,
Использование байесовской сети может сэкономить значительный объем памяти по сравнению с исчерпывающими таблицами вероятностей, если зависимости в совместном распределении вероятностей являются разреженными. 10 двузначных чисел в виде таблицы требует места для хранения 

Одно из преимущест в байесовских сетях состоит в том, что их интуитивно проще понимать (разреженный набор) прямых зависимостей и локальных распределений, чем полные совместные распределения.
Байесовские сети выполняют три основных задачи вывода:
Временная сеть представляет собой полную модель для своих чисел и их отношения, его можно использовать для ответа на вероятностные вопросы о них. Например, сеть местная инстанция для обновления информации о состоянии подмножества, когда наблюдаются другие переменные (переменные свидетельства). Этот процесс вычисления апостериорного распределения при наличии свидетельств называется вероятностным выводом. Апостериорная оценка дает универсальную статистику, достаточную для обнаружения при выборе значений для подмножества чисел, которые минимизируют некоторую функцию ожидаемых потерь, например вероятность решения. Таким образом, байесовскую сеть можно рассматривать как механизм для автоматического применения теоремы Байеса к сложным задачам.
Наиболее распространенными методами эффективного вывода являются: исключение чисел, ненаблюдаемые переменные, не относящиеся к запросу, одно за другим путем распределения суммы по произведению; распространение кликов, которое кэширует вычисления, чтобы можно было запрашивать сразу несколько чисел и быстро распространять новые свидетельства; и рекурсивное кондиционирование и поиск И / ИЛИ, которые допускают компромисс между пространством и временем и соответствуют эффективности исключения, когда используется достаточно места. Все эти методы имеют сложность, которая экспоненциально зависит от ширины дерева сети. Наиболее распространенными алгоритмами приближенного вывода являются выбор по важности, стохастическое моделирование MCMC, устранение мини-ведра, распространение веры с петлей, распространение обобщенных системений и вариационные методы.
Чтобы полностью определить байесовскую сеть и таким образом, полностью представить совместное распределение вероятностей, необходимо указать для каждого Распределение X узла вероятностей для X в зависимости от родителей X. Распределение X в зависимости от его родителей может иметь любую форму. Обычно работают с дискретными или гауссовыми распределениями, это упрощает вычисления. Иногда известны только ограничения на распределение; затем можно использовать максимальной энтропии для определения единственного распределения, то есть с наибольшей энтропией с учетом ограничений. (Аналогично, в конкретном контексте динамической байесовской сети, условное распределение для временной эволюции скрытого состояния обычно для максимизации скорости энтропии подразумеваемого стохастического процесса.)
включают в себя параметры, неизвестны и оценены на основе данных, например, с помощью подхода максимальный правдоподобия. Прямая максимизация правдоподобия (или апостериорной вероятности ) является сложной сложной задачей с учетом ненаблюдаемых чисел. Классическим подходом к проблеме является алгоритм максимизации ожидания, который чередует вычисление ожидаемых значений ненаблюдаемых переменных, обусловленных наблюдаемыми данными, с максимизацией полной вероятности (или апостериорной) предполагающей, что ранее вычисленные ожидаемые значения верны.. В умеренных условиях регулярности этот процесс сходится к значениям максимального правдоподобия (или максимальным апостериорным) значениям параметров.
Более полно байесовский подход к параметрам в том, чтобы рассматривать их как дополнительные ненаблюдаемые переменные и вычислять полное апостериорное распределение по всем узлам, обусловленное наблюдаемыми данными, а интегрировать параметры. Этот подход может быть дорогостоящим и вести к моделям большого размера, что делает классический подход к установке более гибким.
В случае байесовская сеть определяется экспертом и используется для выполнения логического вывода. В других приложениях задача определения сети слишком сложна для человека. В этом случае структура сети и параметры локальных распределений должны быть изучены из данных.
Автоматическое изучение структуры графа байесовской сети (BN) - задача, решаемая в рамках машинного обучения. Основная идея восходит к алгоритму восстановления, разработанному Ребэйном и Перлом, и основывается на различии между тремя возможными шаблонами, разрешенными в 3-узловом DAG:
| Шаблон | Модель |
|---|---|
| Цепочка |  |
| Вилка |  |
| Коллайдер |  |
Первые 2 значения одинаковые зависимости (


Альтернативный метод структурного обучения использует поиск на основе оптимизации. Для этого требуется функция оценки и стратегия поиска. Обычная функция оценки является апостериорная вероятность структуры с учетом обучающих данных, например BIC или BDeu. Требование времени для исчерпывающего поиска, возвращающего структуру, которая максимизирует оценку, составляет суперэкспоненциальный по количеству числа. Стратегия локального поиска внеситенные изменения, улучшение структуры. Алгоритм глобального поиска, такой как цепь Маркова Монте-Карло, может избежатьпопадания в локальных минимумов. Friedman et al. использовать использование взаимной информации между переменными и поисковыми структурами, которая максимизирует это. Они делают это, ограничивая набор родительских кандидатов k узлами и просматривая их.
Особенно быстрый метод точного обучения BN - это преобразовать проблему в задачу оптимизации и решить ее с помощью целочисленного программирования. Ограничения ацикличности добавляются к целочисленной программе (IP) во время решения в виде плоскостей резки. Такой метод может обрабатывать задачи с числом до 100.
справиться с проблемами с числом чисел, необходимым подход. Один из них в том, чтобы сначала выбрать один порядок, а найти оптимальную структуру BN по отношению к этому порядку. Это подразумевает работу над пространством поиска порядков. Затем выберитека и оценка нескольких заказов. Этот метод зарекомендовал себя как лучший из доступных в литературе при огромном количестве чисел.
Другой метод состоит в сосредоточении внимания на подклассе разложимых моделей, для которого MLE имеет закрытую форму. Затем можно непротиворечивую структуру для сотен число.
Изучение байесовских сетей с ограниченной шириной дерева необходимо для обеспечения точного вывода, сложность вывода в наихудшем случае экспоненциально зависит от ширины дерева k (ниже гипотеза экспоненциального времени). Тем не менее, как глобальное свойство графа, увеличивается сложность процесса обучения. В этом контексте можно использовать K-дерево для эффективного обучения.
Данные данные 




Часто предшествующее значение 



Это простейший пример иерархическая байесовская модель.
Процесс может повторяться; например, параметры 
Учитывая измеренные величины 


Предположим, нас интересует оценка 

Однако, если количества связаны, например, индивидуальный


с неправильными априорными значениями 

