Обобщенный закон распределения (GDL) является обобщением свойства распределения что дает начало общему алгоритму передачи сообщений . Это синтез работ многих авторов в области теории информации, цифровых коммуникаций, обработки сигналов, статистики и <581.>искусственный интеллект сообщества. Закон и алгоритм были представлены в полуучебном пособии Шриниваса М. Аджи и Роберта Дж. МакЭлиса с тем же названием.
Содержание
- 1 Введение
- 2 История
- 3 Задача MPF
- 4 GDL: алгоритм решения задачи MPF
- 4.1 Алгоритм обобщенного закона распределения (GDL)
- 4.2 Основы работы алгоритма
- 5 Планирование передачи сообщений и вычисления состояний
- 6 Построение дерева соединений
- 7 Теорема о планировании
- 8 Вычислительная сложность
- 9 Ссылки
Введение
«Закон распределения в математике - это закон, связывающий операции умножения и сложения., обозначенное символически,  ; то есть, мономиальный множитель
; то есть, мономиальный множитель  распределяется или применяется отдельно к каждому члену биномиального множителя
распределяется или применяется отдельно к каждому члену биномиального множителя  , в результате получается произведение
, в результате получается произведение  "- Britannica
"- Britannica
Как видно из определения, применение закона распределения к арифметическому выражению сокращает количество операций в нем. В предыдущем примере общее количество операций уменьшилось с трех (два умножения и сложение в ) до двух ( одно умножение и одно сложение в  ). Обобщение закона распределения приводит к большому семейству быстрых алгоритмов. Это включает в себя БПФ и алгоритм Витерби.
). Обобщение закона распределения приводит к большому семейству быстрых алгоритмов. Это включает в себя БПФ и алгоритм Витерби.
Это более формально объясняется в следующем примере:
 где
где  и
и  - функции с действительным знаком,
- функции с действительным знаком,  и
и  (например)
(например)
Здесь мы «маргинализируем» независимые переменные ( ,
,  и
и  ) для получения результата. Когда мы вычисляем вычислительную сложность, мы видим, что для каждого
) для получения результата. Когда мы вычисляем вычислительную сложность, мы видим, что для каждого  пары
пары  , есть
, есть  термины из-за тройки
термины из-за тройки  , который должен участвовать в оценке
, который должен участвовать в оценке  на каждом шаге одно сложение и одно умножение. Следовательно, общее количество необходимых вычислений составляет
на каждом шаге одно сложение и одно умножение. Следовательно, общее количество необходимых вычислений составляет  . Следовательно, асимптотическая сложность указанной функции равна
. Следовательно, асимптотическая сложность указанной функции равна  .
.
Если мы применим закон распределения к правой части уравнения, мы получим следующее:

Это означает, что можно описать как продукт  где
где  и
и 
Теперь, когда мы вычисляем t Вычислительная сложность, мы видим, что есть сложения в  и
и  каждый, и есть умножения, когда мы используем произведение для вычисления . Следовательно, общее количество необходимых вычислений равно
каждый, и есть умножения, когда мы используем произведение для вычисления . Следовательно, общее количество необходимых вычислений равно  . Следовательно, асимптотическая сложность вычисления
. Следовательно, асимптотическая сложность вычисления  уменьшается до
уменьшается до  из . Это показывает на примере, что применение закона распределения снижает вычислительную сложность, что является одной из хороших черт «быстрого алгоритма».
из . Это показывает на примере, что применение закона распределения снижает вычислительную сложность, что является одной из хороших черт «быстрого алгоритма».
История
Некоторые из проблем, для решения которых использовался закон распределения, можно сгруппировать следующим образом:
1. Алгоритмы декодирования. GDL-подобный алгоритм использовался Галлагером для декодирования кодов с низкой плотностью проверки четности. Основываясь на работе Галлагера, Таннер представил граф Таннера и выразил работу Галлагера в форме передачи сообщений. График Таннерса также помог объяснить алгоритм Витерби.
. Форни заметил, что максимальное правдоподобие Витерби при декодировании сверточных кодов также использовало алгоритмы GDL-подобной общности.
2. Алгоритм вперед-назад. Алгоритм вперед-назад помогал в качестве алгоритма отслеживания состояний в цепи Маркова. И для этого также использовался алгоритм GDL типа generality
3. Искусственный интеллект. Понятие деревьев соединений использовалось для решения многих проблем в AI. Также концепция устранения корзины использует многие концепции.
Задача MPF
MPF или маргинализация функции произведения - это общая вычислительная проблема, которая, как частный случай, включает множество классических задач, таких как вычисление дискретного преобразования Адамара, декодирование с максимальной вероятностью линейного кода по каналу без памяти и умножение цепочки матриц. Сила GDL заключается в том, что он применяется к ситуациям, в которых сложение и умножение являются обобщенными. Коммутативное полукольцо является хорошей основой для объяснения этого поведения. Он определяется в наборе  с операторами «
с операторами « » и «
» и « "где
"где  и
и  являются коммутативными моноидами и выполняется закон распределения.
являются коммутативными моноидами и выполняется закон распределения.
Пусть  - такие переменные, что
- такие переменные, что  где
где  - конечное множество и
- конечное множество и  . Здесь
. Здесь  . Если
. Если  и
и  , пусть
, пусть  ,
,  ,
,  ,
,  и
и 
Пусть  где
где  . Предположим, что функция определена как
. Предположим, что функция определена как  , где
, где  - это коммутативное полукольцо. Кроме того,
- это коммутативное полукольцо. Кроме того,  называются локальными доменами, а
называются локальными доменами, а  как локальные ядра.
как локальные ядра.
Теперь глобальное ядро  определяется как:
определяется как: 
Определение проблемы MPF: для одного или нескольких индексов  , вычислить таблицу значений
, вычислить таблицу значений  -маргинализация глобального ядра
-маргинализация глобального ядра  , которая является функцией
, которая является функцией  определяется как
определяется как 
Здесь  является дополнением с учетом на
является дополнением с учетом на  и
и  называется
называется  целевой функцией или целевой функцией в . Можно заметить, что для вычисления целевой функции очевидным образом требуется
целевой функцией или целевой функцией в . Можно заметить, что для вычисления целевой функции очевидным образом требуется  операций. Это потому, что есть
операций. Это потому, что есть  сложения и
сложения и  умножения, необходимые для вычисления
умножения, необходимые для вычисления  целевая функция. Алгоритм GDL, который объясняется в следующем разделе, может уменьшить эту вычислительную сложность.
целевая функция. Алгоритм GDL, который объясняется в следующем разделе, может уменьшить эту вычислительную сложность.
Ниже приведен пример проблемы MPF. Пусть  и
и  быть такими переменными, что
быть такими переменными, что  и
и  . Здесь
. Здесь  и
и  . Данные функции, использующие эти переменные:
. Данные функции, использующие эти переменные:  и
и  и нам нужно вычислить
и нам нужно вычислить  и
и  определяется как:
определяется как:


Здесь локальные домены и локальные ядра определены следующим образом:
| локальные домены | локальные ядра |
|---|
 |  |
 |  |
 |  |
 | |
где  - это
- это  целевая функция и - целевая функция
целевая функция и - целевая функция  .
.
Рассмотрим другой пример, где  и
и  является вещественной функцией. Теперь мы рассмотрим задачу MPF, в которой коммутативное полукольцо определяется как набор действительных чисел с обычным сложением и умножением, а локальные области и локальные ядра определяются следующим образом:
является вещественной функцией. Теперь мы рассмотрим задачу MPF, в которой коммутативное полукольцо определяется как набор действительных чисел с обычным сложением и умножением, а локальные области и локальные ядра определяются следующим образом:
| локальные области | локальные ядра |
|---|
 | |
 |  |
 |  |
 |  |
 |  |
 | |
Теперь, поскольку глобальное ядро определяется как продукт loc al ядер, это

и целевая функция в локальном домене  равно
равно

Это преобразование Адамара функции . Следовательно, мы можем видеть, что вычисление преобразования Адамара является частным случаем проблемы MPF. Можно продемонстрировать и другие примеры, чтобы доказать, что проблема MPF образует частные случаи многих классических проблем, как объяснено выше, детали которых можно найти в
GDL: алгоритм для решения проблемы MPF
Если один можно найти взаимосвязь между элементами данного набора  , тогда можно решить проблему MPF, основываясь на понятии распространения убеждений, которое является специальное использование техники «передачи сообщений». Требуемая взаимосвязь состоит в том, что данный набор локальных доменов может быть организован в дерево соединений . Другими словами, мы создаем теоретико-графическое дерево с элементами в качестве вершин tree
, тогда можно решить проблему MPF, основываясь на понятии распространения убеждений, которое является специальное использование техники «передачи сообщений». Требуемая взаимосвязь состоит в том, что данный набор локальных доменов может быть организован в дерево соединений . Другими словами, мы создаем теоретико-графическое дерево с элементами в качестве вершин tree  , так что для любых двух произвольных вершин говорят
, так что для любых двух произвольных вершин говорят  и
и  где
где  и между этими двумя вершинами существует ребро, то есть пересечение соответствующих меток, а именно
и между этими двумя вершинами существует ребро, то есть пересечение соответствующих меток, а именно  , представляет собой подмножество метки на каждой вершине на уникальном пути из на .
, представляет собой подмножество метки на каждой вершине на уникальном пути из на .
Например,
Пример 1. Рассмотрим следующие девять локальных доменов:






Для указанного выше набора локальных доменов их можно организовать в дерево соединений как показано ниже:
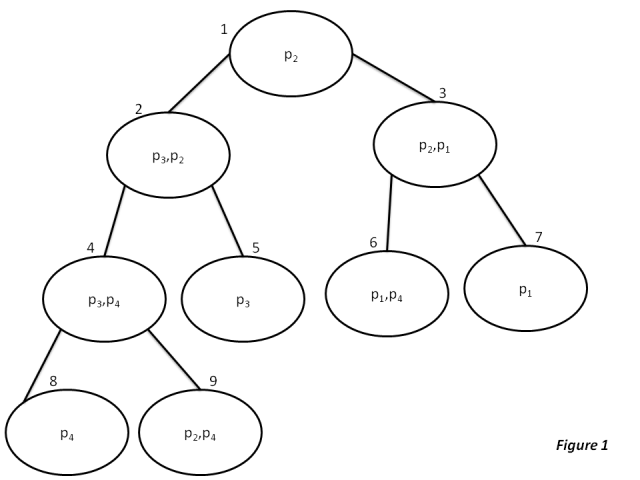
Аналогично. Если задан другой набор, подобный следующему
Пример 2: Рассмотрим следующие четыре локальных домена:


Затем построение дерева только с этими локальные домены невозможны, так как этот набор значений не имеет общих доменов, которые могут быть помещены между любыми двумя значениями указанного выше набора. Но, однако, если добавить два фиктивных домена, как показано ниже, то организация обновленного набора в дерево соединений станет возможной и простой.
5. ,
, . 6.
. 6. ,
,
Аналогично для этого набора доменов дерево соединений выглядит так, как показано ниже:

Алгоритм обобщенного закона распределения (GDL)
Входные данные: набор локальных доменов.. Выходные данные: для заданного набора доменов вычисляется возможное минимальное количество операций, необходимых для решения проблемы.. Итак, если и соединены ребром в дерево соединений, то сообщение от до представляет собой набор / таблицу значения, задаваемые функцией:  :
: . Чтобы начать со всех функций, т.е. для всех комбинаций
. Чтобы начать со всех функций, т.е. для всех комбинаций  и
и  в данном дереве, идентично , и когда конкретное сообщение обновляется, это следует уравнению, приведенному ниже.
в данном дереве, идентично , и когда конкретное сообщение обновляется, это следует уравнению, приведенному ниже.
 =
= 
где  означает, что
означает, что  является дополнительной вершина с в дереве.
является дополнительной вершина с в дереве.
Аналогичным образом каждая вершина имеет состояние, которое как таблица, содержащая значения из функций  , точно так же, как сообщения инициализируются в 1 идентично, состояние определяется как локальное ядро
, точно так же, как сообщения инициализируются в 1 идентично, состояние определяется как локальное ядро  , но всякий раз, когда
, но всякий раз, когда  обновляется, это следует к уравнению:
обновляется, это следует к уравнению:

Основная работа алгоритма
Для заданного набора локальных доменов в входных данных, мы разработняем, либо мы можем создать дерево соединений, либо напрямую используя набор, либо добавив сначала фиктивные домены к набору, а затем создавая дерево соединений, если построение соединения невозможно, чтобы выполнить алгоритм, что нет малое количество шагов для вычислений данной задачи уравнения, но как только у нас есть дерево соединений, алгоритмы должны быть запланированы сообщения и вычислить состояния, которые могут быть выполнены, когда шаги могут быть сокращены, поэтому мы можем сообщить это ниже.
Планирование передачи сообщений и вычислений состояния
Здесь мы собираемся поговорить о двух особых случаях, а именно задаче с одной вершиной, в которой целевая функция вычисляется только на одной вершине  , вторая - задача для всех вершин, цель которой - вычислить целевую функцию во всех вершинах.
, вторая - задача для всех вершин, цель которой - вычислить целевую функцию во всех вершинах.
Начнем с задачи с одной вершиной, GDL начало с направления каждого ребра к целевой вершине . Здесь сообщения отправляются только в направлении вершины. Обратите внимание, что все сообщения отправляются только один раз. Сообщения начинаются с конечных узлов (где степень равна 1) и идут вверх к вершине . Сообщение передается от листьев к своим родителям, а затем оттуда к их родителям и так далее, пока не достигнет вершины . Целевая вершина будет вычислять свое состояние только тогда, когда она получит все сообщения от всех своих соседей. Когда у нас есть состояние, мы получили ответ, и, следовательно, алгоритм завершается.
Например, давайте рассмотрим дерево соединений, приведенное выше, то есть набор из примера 1,. Теперь таблица планирования для этих доменов (где целевая вершина  ).
).
 .
.  .
.  .
.  .
.  .
.  .
.  .
.  .
.  .
. 
Таким образом, сложность GDL с одной вершиной может быть представлена как
 арифметические операции. Где (Примечание: объяснение приведенного выше уравнения объясняется позже в статье).
арифметические операции. Где (Примечание: объяснение приведенного выше уравнения объясняется позже в статье).  - это метка
- это метка  ..
..  - это степень для (т. Е. Количество вершин, связанных с v).
- это степень для (т. Е. Количество вершин, связанных с v).
Чтобы решить проблему All-Vertices, мы можем запланировать GDL методы, некоторые из них включают параллельную управление, где в каждом раунде обновляется каждое состояние, и каждое сообщение вычисляется и передается. в то же время. В этом типе реализации состояния и сообщения будут стабилизироваться после количества раундов, которое не больше диаметра дерева. В этот момент все состояния вершин будут равны желаемой целевой функции.
Другой способ запланировать GDL для проблемы - последовательная реализация, аналогичная этой задаче с одной вершиной, за исключением того, что мы не останавливаем алгоритм до тех пор, пока все вершины необходимого набора не получат все сообщения от всех их соседи и вычислили их состояние.. Таким образом, количество арифметических операций, необходимых для этой реализации, не больше  арифметические операции.
арифметические операции.
Построение дерева соединений
Ключ к построению соединений в локальном графе домена  , является взвешенным полным графом с
, является взвешенным полным графом с  вершинами
вершинами  т.е. по одному для каждого локального домена, имеющего вес ребра
т.е. по одному для каждого локального домена, имеющего вес ребра  имеет значение на.
имеет значение на.  .., если
.., если  , тогда мы говорим, что
, тогда мы говорим, что  содержится в
содержится в  . Обозначается
. Обозначается  (вес остовного дерева размера ), что определяется как
(вес остовного дерева размера ), что определяется как

, где n - количество элементов в этом наборе. Для большей ясности и подробностей, пожалуйста, обратитесь к ним.
Теорема планирования
Пусть  будет деревом соединений с набором вершин
будет деревом соединений с набором вершин  и набор ребер
и набор ребер  . В этом алгоритме сообщения отправляются в обоих направлениях на любом ребре, поэтому мы можем сказать / рассматривать набор ребер E как набор упорядоченных пар вершин. Например, из рисунка 1 можно определить следующим образом:
. В этом алгоритме сообщения отправляются в обоих направлениях на любом ребре, поэтому мы можем сказать / рассматривать набор ребер E как набор упорядоченных пар вершин. Например, из рисунка 1 можно определить следующим образом:

ПРИМЕЧАНИЕ:  выше дает вам все возможные направления, по которому может перемещаться в дереве.
выше дает вам все возможные направления, по которому может перемещаться в дереве.
Расписание для GDL как конечная последовательность подмножеств . Что обычно обозначается как  {
{ }, где
}, где  - это набор сообщений, обновленных в течение
- это набор сообщений, обновленных в течение  раунд запуска алгоритма.
раунд запуска алгоритма.
Определив / просмотрев некоторые обозначения, мы увидим, что в теореме говорится: «Когда нам дано расписание»  , соответствующая решетка сообщений как конечный ориентированный граф с набором вершин
, соответствующая решетка сообщений как конечный ориентированный граф с набором вершин  , в котором типичный элемент обозначается
, в котором типичный элемент обозначается  для
для  , после завершения передачи сообщения состояние в вершине будет
, после завершения передачи сообщения состояние в вершине будет  целью, предназначенным для
целью, предназначенным для

и если только там - путь от  до
до 
Вычислительная сложность
Здесь мы пытаемся объяснить сложность решения задачи MPF с точки зрения количества математических операций, необходимые для вычислений. т.е. Мы сравнили количество операций, требуемых при вычислении с использованием обычного метода, мы используем методы, которые не используют передачу сообщений или соединения в коротких методах, которые не используют GDL) и количество операций, использующих обобщенный распределительный закон.
Пример: рассмотрим простейший случай, когда нам нужно вычислить следующее выражение  .
.
Для вычислений этого выражения наивно требуется два умножения и одно сложение. Выражение, выраженное с использованием закона распределения, может быть записано  простая оптимизация, которая сокращает количество операций до одного добавления и одно умножение.
простая оптимизация, которая сокращает количество операций до одного добавления и одно умножение.
Подобно объясненному выше, мы будем выражать уравнения в различных формах, чтобы выполнить как можно меньше с помощью операций GDL.
Как объяснялось в предыдущих разделах, мы решаем проблему, используя концепцию соединений деревьев. Оптимизация, полученная с помощью этих деревьев, сравнима с оптимизацией, полученной путем полугрупповой задачи на деревьях. Например, чтобы найти минимум группы чисел, мы можем заметить, что если у нас есть дерево, и все элементы находятся в нижней части дерева, то мы можем сравнить минимум два элемента последовательно. Когда этот процесс распространяется по дереву, минимум элементов будет находиться в корне.
Ниже описана сложность решений соединений с использованием передачи сообщений
Мы перепишем формулу, используем ранее, в следующую форму. Это уравнение для отправки сообщения из вершины v в w
 ---- уравнение сообщения
---- уравнение сообщения
Аналогичным образом мы перепишем уравнение для расчета состояния вершины v следующим образом:

Сначала мы проанализируем задачу с одной вершиной и предположим, что целевая вершина равна и, следовательно, у нас есть одно ребро от до . Предположим, у нас есть край  , мы вычисляем сообщение, используя уравнение сообщения. Для вычисления
, мы вычисляем сообщение, используя уравнение сообщения. Для вычисления  требуется
требуется

сложения и

умножения.
(Мы представляем  как
как  .)
.)
Но будет много возможностей для  , следовательно,.
, следовательно,.  возможностей для
возможностей для  . Таким образом, для всего сообщения потребуется
. Таким образом, для всего сообщения потребуется

сложения и

умножения
Общее количество арифметических операций, необходимых для отправки сообщения по направлению по краям дерева будет

сложения и

умножения.
После того, как все сообщения были переданы, алгоритм завершается вычислением состояния в Для вычисления состояния требуется  больше умножений. Таким образом, количество вычислений, необходимых для вычисления состояния, указано ниже:
больше умножений. Таким образом, количество вычислений, необходимых для вычисления состояния, указано ниже:

сложения и

умножения
Таким образом, общая сумма количества вычислений равно
 ----
---- 
где  является ребром, и его размер определяется как
является ребром, и его размер определяется как 
Формула выше дает нам верхнюю границу.
Если мы определим сложность ребра как

Следовательно, можно записать как

Теперь вычислим сложность ребра для задачи, определенной на рисунке 1, следующим образом:








Общая сложность будет  , что значительно по сравнению с прямым методом. (Здесь под методом мы подразумеваем методы, которые используют методы использования передачи сообщений. Время, затрачиваемое на использование методов прямого вычисления, будет эквивалентно вычислению для вычислений состояний каждого из узлов.)
, что значительно по сравнению с прямым методом. (Здесь под методом мы подразумеваем методы, которые используют методы использования передачи сообщений. Время, затрачиваемое на использование методов прямого вычисления, будет эквивалентно вычислению для вычислений состояний каждого из узлов.)
всех вершин, в сообщении должно быть отправлено в обоих направлениях, а состояние должно быть вычислено в обоих вершинах. Для этого потребуется  но с помощью предварительных вычислений мы можем уменьшить количество умножений до
но с помощью предварительных вычислений мы можем уменьшить количество умножений до  . Здесь - степень вершины. Пример: Если есть набор
. Здесь - степень вершины. Пример: Если есть набор  с числа. Можно вычислить все d произведений
с числа. Можно вычислить все d произведений  из
из  с помощью не более умножения вместо очевидного
с помощью не более умножения вместо очевидного  . Выполним это, вычисляя величину
. Выполним это, вычисляя величину  и
и  для этого требуется
для этого требуется  умножений. Тогда, если
умножений. Тогда, если  обозначает произведение всех кроме
обозначает произведение всех кроме  имеем
имеем  и т. д. потребуются еще
и т. д. потребуются еще  умножения, в результате чего в сумме получится
умножения, в результате чего в сумме получится
Когда доходит до построения соединений, мы должны выбрать остовное дерево с наименьшим значением  , иногда это может означать добавление локального домена для снижения сложности дерева соединений.
, иногда это может означать добавление локального домена для снижения сложности дерева соединений.
Может показаться, что GDL верен только тогда, когда локальные домены могут быть представлены в виде дерева соединений. Но даже в случаях, когда есть циклы и количество итераций. Эксперименты с алгоритмом Галлагера - Таннера - Виберга для кодов с низкой плотностью проверки на четность подтвердили это утверждение.
Ссылки
- ^ Aji, S.M.; МакЭлис, Р.Дж. (Март 2000 г.). «Обобщенный распределительный закон» (PDF). IEEE Transactions по теории информации. 46 (2): 325–343. doi : 10.1109 / 18.825794.
- ^"закон о распределении доходов". Encyclopdia Britannica. Энциклопедия Britannica Online. Encyclopdia Britannica Inc. Проверено 1 мая 2012 г.
- ^«Архивная копия» (PDF). Архивировано из оригинального (PDF) 19 марта 2015 года. Проверено 19 марта 2015. CS1 maint: заархивированная копия как заголовок (ссылка ) Алгоритмы дерева соединений
- ^http://www-anw.cs.umass.edu/ ~ cs691t / SS02 / lectures / week7.PDF Архивировано 26 мая 2012 г. на Wayback Machine Алгоритм дерева соединений


