
Войти
Расширенный код Unix (EUC ) - это многобайтовая система кодирования символов, используемая в основном для японского, корейского и упрощенного китайского.
Структура EUC основана на ISO -2022 стандарт, который определяет способ представления наборов символов, содержащих максимум 94 символа, или 8836 (94) символов, или 830584 (94) символа, как последовательности 7-битных кодов. Формы EUC могут быть только в наборах символов, совместимых с ISO-2022. С помощью схемы EUC можно представить до четырех наборов кодированных символов (называемых G0, G1, G2 и G3 или кодовых наборов 0, 1, 2 и 3).
G0 почти всегда представляет собой набор кодированных символов, соответствующий ISO-646, например US-ASCII, ISO 646: KR (KS X 1003) или ISO 646: JP (нижняя половина JIS X 0201), который вызывается в GL (т. Е. С очищенным старшим битом). Исключением из US-ASCII является то, что 0x5C (обратная косая черта в US-ASCII) часто используется для представления знака йены в EUC-JP (см. Ниже) и выиграл знак в EUC-KR.
Чтобы получить форму EUC для символа ISO-2022, устанавливается старший бит каждого 7-битного байта исходных кодов ISO 2022 (путем добавления 128 к каждому из этих исходных 7-битных кодов) ; это позволяет программному обеспечению легко различать, принадлежит ли конкретный байт в строке символов коду ISO-646 или коду ISO-2022 (EUC).
Наиболее часто используемые коды EUC - это кодировки переменной ширины с символом, принадлежащим G0 (набор кодированных символов, совместимый с ISO-646), принимающим один байт и символ, принадлежащий G1 (принимаемый набор кодированных символов 94x94), представленный двумя байтами. EUC-CN форма GB 2312 и EUC-KR являются примерами таких двухбайтовых кодов EUC. EUC-JP включает символы, представленные до трех байтов, тогда как один символ в EUC-TW может занимать до четырех байтов.
Современные приложения с большей вероятностью будут использовать UTF-8, который поддерживает все символы кодов EUC и многое другое, и, как правило, более переносим с меньшим количеством отклонений и ошибок поставщика. Однако EUC все еще очень популярен, особенно EUC-KR для Южной Кореи.
 | |
| MIME / IANA | GB2312 |
|---|---|
| Псевдоним (а) | csGB2312 |
| Язык (и) | Упрощенный китайский, Английский, Русский |
| Стандартный | GB 2312 (1980) |
| Классификация | Расширенный ASCII, кодирование с переменной шириной, Кодировка CJK, EUC |
| Расширяет | US-ASCII |
| Extensions | 748, GBK, GB 18030, x-mac-chinesesimp |
| Преобразование / кодирование | GB 2312 |
| Преемник | GBK, GB 18030 |
| |
EUC-CN - это обычная кодированная форма стандарт GB 2312 для упрощенных китайских иероглифов. В отличие от японского JIS X 0208 и ISO-2022-JP, GB 2312 обычно не используется в 7-битной версии кода ISO 2022, хотя вариантная форма называется HZ (который ограничивает текст GB 2312 последовательностями ASCII) иногда использовался в USENET.
. Символ ASCII представлен в своей обычной кодировке. Символ из GB 2312 представлен двумя байтами, оба из диапазона 0xA1–0xFE.
Кодировка, связанная с EUC-CN, - это код «748», используемый в системе набора текста WITS, разработанной Beijing's Founder Technology (теперь устарел его новой системой набора FITS). Код 748 содержит все элементы GB 2312, но не соответствует стандарту ISO 2022 и, следовательно, не является истинным кодом EUC. (Он использует 8-битный ведущий байт, но различает второй байт с его самым старшим битом, и один с его самым старшим битом очищен, и поэтому по структуре больше похож на Big5 и другие не-ISO Совместимые с 2022 системы кодирования DBCS. Часть кода 748, отличная от GB2312, содержит традиционные и гонконгские символы и другие глифы, используемые при наборе газет.
GBK является расширением GB 2312. Он определяет расширенную форму кодировки EUC-CN, способную представлять более крупный массив символов CJK получены в основном из Unicode 1.1, включая традиционные китайские символы и символы, используемые только в японском. Однако это не настоящий код EUC, потому что байты ASCII могут отображаться как байты следа (и байты C1, не ограничиваясь отдельными сдвигами, могут отображаться как байты начала или окончания) из-за большего требуется пространство для кодирования.
Варианты GBK реализуются с помощью кодовой страницы Windows 936 (Microsoft Windows кодовой страницы для упрощенного китайского языка) и с помощью кодовой страницы IBM 1386.
Кодировка символов GB 18030 на основе Unicode определяет расширение GBK, способное полностью кодировать Unicode. Однако Unicode, закодированный как GB 18030, является кодировкой переменной ширины, которая может использовать до четырех байтов на символ из-за того, что требуется еще большее пространство кодирования. Являясь расширением GBK, он является расширенным набором EUC-CN, но сам по себе не является настоящим кодом EUC. Поскольку он является кодировкой Unicode, его репертуар идентичен репертуару других форматов преобразования Unicode, таких как UTF-8.
Другие варианты EUC-CN, отклоняющиеся от Механизм EUC включает сценарий Mac OS китайский упрощенный (известный как кодовая страница 10008 или x-mac-chinesesimp). Он использует байты 0x80, 0x81, 0x82, 0xA0, 0xFD, 0xFE и 0xFF для U с умлаутом (ü), двумя символами метрики специального шрифта, неразрывным пробелом, знак авторского права (©), знак товарного знака (™) и многоточие (…) соответственно. Это отличается тем, что считается однобайтовым символом по сравнению с первым байтом двухбайтового символа как из EUC (где из них 0xFD и 0xFE определены как ведущие байты), так и из GBK (где из них 0x81, 0x82, 0xFD и 0xFE определены как ведущие байты).
Такое использование 0xA0, 0xFD, 0xFE и 0xFF соответствует варианту Apple Shift_JIS.
 | |
| MIME / IANA | EUC-JP |
|---|---|
| Псевдоним (а) | Unixized JIS (UJIS), csEUCPkdFmt Японский |
| Язык (и) | Японский, Английский, Русский |
| Классификация | Расширенный ISO 646, кодирование переменной ширины, кодирование CJK, EUC |
| Расширяет | US-ASCII или ISO 646: JP |
| Преобразует / кодирует | JIS X 0208, JIS X 0212, JIS X 0201 |
| Преемник | EUC -JISx0213 |
| |
| Псевдоним (а) | EUC-JISx0213 |
|---|---|
| Язык (и) | Японский, Айнский, Английский, Русский |
| Стандартный | JIS X 0213 |
| Классификация | Расширенный ASCII, кодировка переменной ширины, Кодировка CJK, EUC |
| Расширяет | US-ASCII |
| Преобразовывает / кодирует | JIS X 0213, JIS X 0201 (Кана) |
| Предшествующий by | EUC-JP |
| |
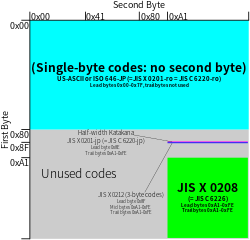
EUC-JP - это кодировка переменной ширины, используемая для воспроизведения представлены элементы трех японских стандартов набора символов, а именно JIS X 0208, JIS X 0212 и JIS X 0201. Другие имена для этой кодировки включают Unixized JIS (или UJIS ) и ATT JIS . 0,1% всех веб-страниц используют EUC-JP с августа 2018 года, тогда как 3,2% веб-сайтов Японии используют эту кодировку (реже, чем Shift JIS или UTF-8 ). IBM называет ее кодовой страницей 954 . У Microsoft есть два номера кодовой страницы для этой кодировки (51932 и 20932).
Эта схема кодирования позволяет легко смешивать 7-битный ASCII и 8-битный японский язык без необходимости использования управляющих символов, используемых в ISO-2022-JP, который основан на том же стандарты набора символов и без байтов ASCII, появляющихся как байты следа (в отличие от Shift JIS ).
Родственная и частично совместимая кодировка, называемая EUC-JISx0213 или EUC-JIS-2004, кодирует JIS X 0201 и JIS X 0213 (аналогично Shift_JISx0213, его аналог на основе Shift_JIS).
По сравнению с EUC-CN или EUC-KR, EUC-JP не получил такого широкого распространения на ПК и системах Macintosh в Японии, которые использовали Shift JIS или его расширения (кодовая страница Windows 932 в Microsoft Windows и MacJapanese в классической Mac OS ), хотя он стал активно использоваться в Unix или Unix-подобных операционные системы (кроме HP-UX ). Поэтому, используют ли японские веб-сайты EUC-JP или Shift_JIS, часто зависит от того, какую ОС использует автор.
Расширения поставщика для EUC-JP обычно распределялись в рамках отдельных кодовых наборов, в отличие от использования недопустимых последовательностей EUC (как в популярных расширениях EUC-CN и EUC-KR).
Символы кодируются следующим образом:
 Структура кода EUC-KR Структура кода EUC-KR | |
| MIME / IANA | EUC-KR |
|---|---|
| Псевдоним (а) | Wansung, IBM-970 |
| Язык (и) | Корейский, Английский, Русский |
| Стандарт | KS X 2901 (KS C 5861) |
| Классификация | Расширенный ISO 646, кодирование переменной ширины, Кодировка CJK, EUC |
| Расширяет | US-ASCII или ISO 646: KR |
| Расширения | , IBM-949, Unified Hangul Code (Windows -949) |
| Преобразование / кодирование | KS X 1001 |
| Преемник | Unified Hangul Code (веб-стандарты) |
| |
EUC-KR - это переменной ширины кодировка для представления корейского текста с использованием двух наборов кодированных символов: KS X 1001 (ранее KS C 5601) или ISO 646 : KR (KS X 1003, ранее KS C 5636) или US-ASCII, в зависимости от варианта. (ранее KS C 5861) оговаривает кодировку и RFC 1557 дублирует его как EUC-KR.
Символ, взятый из KS X 1001 (G1, кодовый набор 1), кодируется как два байта в GR (0xA1–0xFE) и символ из KS X 1003 или US-ASCII (G0, кодовый набор 0) занимает один байт в GL (0x21–0x7E).
При использовании с ASCII IBM называется кодовой страницей 970 . Она известна как кодовая страница 51949 от Microsoft. Обычно его называют Wansung (корейский : 완성, романизированный : Wanseong, lit. 'precomposed ') в Республике Корея.
Распространенным расширением EUC-KR является Унифицированный код хангыль (통합형 한글 코드, Tonghabhyeong Hangeul Kodeu, или 통합 완성형, Tonghab Wansunghyung), который является корейская кодовая страница по умолчанию в Microsoft Windows (кодовая страница 949, номер 1363 от IBM). Стандарт кодирования W3C / WHATWG, используемый HTML5, включает в себя расширения унифицированного кода хангыль в свое определение EUC-KR. Другие расширения, совместимые с EUC-KR, включают корейскую кодировку Mac OS, используемую классической Mac OS. Кодовая страница IBM 949 - еще одно, не связанное с этим расширение EUC-KR. Подобно описанным выше расширениям EUC-CN, эти расширения не соответствуют структуре EUC.
По состоянию на июль 2020 года 0,1% всех веб-страниц во всем мире используют EUC-KR, что вводит в заблуждение, поскольку 17,4% веб-страниц в Южной Корее используют (только страну, для которой предназначена кодировка), что делает его самым популярным. кодировка не UTF-8 / Unicode для языка / веб-домена, в то время как только 8,4% веб-страниц используют корейский язык (что делает UTF-8 менее популярным в Южной Корее, чем (по-видимому) во всех странах Мир). Включая расширения, это наиболее широко используемая устаревшая кодировка символов в Корее на всех трех основных платформах (macOS, другие Unix-подобные ОС и Windows), но ее использование очень медленно переходит на UTF-8, поскольку он набирает популярность, особенно в Linux и macOS.
Как и большинство других кодировок, UTF-8 теперь предпочтительнее для нового использования, решая проблемы с согласованностью между платформами и поставщиками.
EUC-TW - это кодировка переменной ширины, которая поддерживает US-ASCII и 16 плоскостей CNS 11643, каждая из которых имеет размер 94x94. Это редко используемая кодировка для традиционных китайских иероглифов, используемых в Тайване. Big5 встречается гораздо чаще.
Обратите внимание, что плоскость 1 CNS 11643 кодируется дважды как кодовый набор 1 и часть кодового набора 2.
UTF-8 становится более распространенным, чем EUC-TW, как и большинство кодовых страниц..
Кодировки, описанные выше (с использованием байтов в 0x21–0x7E для кодового набора 0, байтов в 0xA1–0xFE для кодового набора 1, 0x8E с последующими байтами в 0xA1 –0xFE для кодового набора 2 и 0x8F, за которым следуют байты в 0xA1–0xFE для кодового набора 3), находятся в форме переменной ширины, называемой упакованным форматом EUC. Эта форма обычно обозначается как EUC.
Внутренняя обработка может использовать альтернативную форму фиксированной длины, называемую полным двухбайтовым форматом EUC . Это представляет:
Начальные байты 0x00 и 0x80 используются в случаях, когда кодовый набор использует только один байт. Существует также четырехбайтовый формат фиксированной длины. Эти формы фиксированной длины подходят для внутренней обработки и обычно не встречаются при обмене.
EUC-JP зарегистрирован IANA в обоих форматах: в упакованном формате как «EUC-JP» или «csEUCPkdFmtJapanese» и в формате фиксированной ширины как «csEUCFixWidJapanese». Только упакованный формат включен в WHATWG Стандарт кодирования, используемый HTML5.