Итерационный метод поиска оценок максимального правдоподобия в статистических моделях
В статистике, алгоритм ожидания - максимизации (EM) - это итерационный метод для нахождения (локального) максимальный правдоподобия или максимальный апостериорный (MAP) оценки параметров в статистических моделях, где модель зависит от ненаблюдаемых скрытых чисел. Итерация EM проходит между выполнением этапа ожидания (E), который выполняет ожидаемую функцию для ожидания журнал-правдоподобия, оцененный с использованием текущих параметров, этапом максимизации (M), вычисляет параметры, максимизирующие логарифмическую правдоподобие, найденную на шаге E Эти методы используются для определения определения скрытых на следующем этапе E.

ЭМ-кластеризация данных извержении
Старый Верный. Случайная исходная модель (которая из-за разных масштабов кажется двумя очень плоскими и широкими сферами) соответствует наблюдаемым данным. На первых страницах модель простого, но затем сходится к двум режимам
гейзера. Визуализируется с помощью
ELKI.
Содержание
- 1 История
- 2 Введение
- 3 Описание
- 4 Свойства
- 5 Подтверждение правильности
- 6 В качестве процедуры максимизации - максимизации
- 7 Приложения
- 8 Фильтрация и сглаживание EM-алгоритмов
- 9 Варианты
- 10 Связь с вариационными байесовскими методами
- 11 Геометрическая интерпретация
- 12 Примеры
- 12.1 Гауссова смесь
- 12.1.1 Шаг E
- 12.1.2 Шаг M
- 12.1.3 Завершение
- 12.1.4 Обобщение
- 12.2 Усеченная и цензурированная регрессия
- 13 Альтернативы
- 14 См. Также
- 15 Ссылки
- 16 Дополнительная литература
- 17 Внешние ссылки
История
Алгоритм EM был объяснен и получил свое название в классической статье 1977 года Артуром Демпстером, Нэн Лэрд и Дональд Рубин. Они отметили, что этот метод «много раз предлагался при обстоятельствах» более ранними авторами. Один из первых - это метод подсчета генов для оценки частот аллелей по Седрику Смиту. Очень подробное описание метода ЭМ для экспоненциальных семейств было опубликовано Рольфом Сундбергом в его диссертации и нескольких статьях после его сотрудничества с Пер Мартин-Лёф и Андерсом Мартином-Лёфом. Статья Демпстера - Лэрда - Рубина 1977 г. обобщила этот метод и наметила анализ сходимости для более широкого класса проблем. В статье Демпстера - Лэрда - Рубина ЭМ-метод определен как важный инструмент статистического анализа.
Анализ сходимости алгоритма Демпстера - Лэрда - Рубина был некорректным, и С. опубликовал правильный анализ сходимости. Ф. Джефф Ву в 1983 году. Доказательство Ву установило сходимость метода ЭМ вне экспоненциального семейства, как утверждал Демпстер-Лэрд-Рубин.
Введение
Алгоритм EM используется для поиска (локальных) параметров правдоподобия статистической модели в случаях, когда уравнения не могут быть решены напрямую. Обычно эти модели включают скрытые переменные в дополнение к неизвестным параметрам и известным данным наблюдений. То есть либо данных существует пропущенных значений, либо модель может быть сформулирована более просто, допуская существование дополнительных ненаблюдаемых точек данных. Например, модель смеси можно описать более просто, если предположить, что последняя точка имеет ненаблюдаемую точку данных или скрытую переменную, определяющую компонент смеси, соответствующую каждую точку данных.
Для поиска решений с максимальным правдоподобием обычно требуется брать производные от функции правдоподобия по всем неизвестным значениям, параметрам и скрытым переменным и используемым уравнениям. В статистических моделях со скрытыми переменными это обычно невозможно. Вместо этого обычно является набором взаимосвязанных параметров, требуемых параметров, используемых друг с другом.
Алгоритм EM исходит из наблюдения, что существует способ решить эти два набора инструментовенно. Можно просто выбрать два произвольных значения для одного набора неизвестных, использовать их для оценки второго набора, затем использовать эти новые значения, чтобы найти лучшую оценку первого набора, а затем продолжить чередовать эти два, пока оба результата не получат. сходятся к неподвижным точкам. Не очевидно, что это сработает, но можно доказать, что в данном контексте это работает, и что производная вероятность (произвольно близка) к нулю в этой точке, что, в свою очередь, означает, что точка является либо максимумом, либо a седловая точка. Как правило, могут быть найдены глобальные максимумы без гарантии, что глобальный максимум будет найден. Некоторые вероятности также содержат особенности, то есть бессмысленные максимумы. Например, одно из решений, которое может быть найдено ЭМ в смешанной модели, включает установку одного из компонентов, чтобы иметь нулевую дисперсию, и параметр среднего значения для того же компонента, равный одной из точек данных.
Описание
Учитывая статистическую модель, которая генерирует набор  наблюдаемых данных, набор ненаблюдаемых скрытых данных или отсутствующих значений
наблюдаемых данных, набор ненаблюдаемых скрытых данных или отсутствующих значений  и вектор неизвестных параметров
и вектор неизвестных параметров  вместе с функция правдоподобия
вместе с функция правдоподобия  , оценка максимальное правдоподобия (MLE) неизвестных факторов путем максимизации предельного правдоподобия наблюдаемых данных
, оценка максимальное правдоподобия (MLE) неизвестных факторов путем максимизации предельного правдоподобия наблюдаемых данных

Однако часто это количество я решаемый (например, если представляет собой последовательность событий, так что количество роста растет.
Алгоритм EM пытается найти MLE предельного правдоподобия, итеративно применяя эти два шага:
- Шаг ожидания (шаг E): Определите
 как ожидаемое значение журнала функция правдоподобия для относительно текущего условного распределения с учетом и текущих оценок параметров
как ожидаемое значение журнала функция правдоподобия для относительно текущего условного распределения с учетом и текущих оценок параметров  :
: ![{\ displaystyle Q ({\ boldsymbol {\ theta}} \ mid {\ boldsymbol {\ theta}} ^ {(t)}) = \ operatorname {E} _ {\ mathbf {Z} \ mid \ mathbf {X}, {\ boldsymbol {\ theta}} ^ {(t)}} \ left [\ log L ({\ boldsymbol {\ theta}}; \ mathbf {X}, \ mathbf {Z}) \ right] \,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/273a8ef209e0f8cb8b30b120a89218a8f748b9dd)
- Шаг максимизации (шаг M): F и параме тр ы, которые максимизируют это количество:

Типичные модели, используемые ЭМ, используют как скрытую переменную, указывающий член в одном из наборов групп:
- Наблюдаемые точки данных могут быть дискретными (принимающими значения в конечном или счетно бесконечном множестве) или непрерывными (последние значения в несчетно бесконечном множестве). С каждой точкой данных может быть связан вектор наблюдений.
- пропущенные значения (также известные как скрытые переменные ) являются дискретными взятыми из фиксированного количества значений и с одной скрытой на наблюдаемой единице.
- Параметры непрерывными и бывают двух видов: Параметры, которые связаны со всеми точками данных, и параметры, связанные с конкретным значением скрытой переменной (т. Е. Связанные со всеми точками данных, у соответствующая скрытая переменная имеет это значение).
Однако можно применить EM к другим всякие модели.
Мотив следующий. Если известно значение параметров , обычно значение скрытых чисел можно найти, максимизируя логарифмическую вероятность для всех обнаруженных , либо просто перебирая или с помощью такого алгоритма, как алгоритм Баума - Велча для скрытых марковских моделей. И наоборот, если мы знаем значение скрытых чисел , мы можем найти оценку параметров довольно легко, обычно простой способ группировки наблюдаемых точек данных в соответствии с указанными значениями скрытой и усреднения значений или некоторой функции значений точек в каждой группе. Это предполагает итеративный алгоритм в случае, когда и , и неизвестны:
- Сначала инициализируйте параметры некоторыми случайными значениями.
- Вычислите вероятность каждого возможного значения , учитывая .
- Затем используйте только -вычисленные значения для вычислений более точной оценки параметров .
- Повторяйте шаги 2 и 3 до сходимости.
Алгоритм, как только что описанный, монотонно приближается к локальному минимуму функции стоимости.
Свойства
Говоря о шаге ожидания (E), это немного похоже на неправильное название. На первом этапе вычисляются фиксированные, зависящие от параметров функции Q. Как только параметры Q известны, они полностью определяются и максимизируются на втором (M) этапе EM-алгоритма.
Хотя итерация EM увеличивает текущие данные (т. Е. Маргинальную) функцию правдоподобия, нет гарантии, что последовательность сходится к оценке значения правдоподобия. Для мультимодальных распределений это означает, что алгоритм EM может сходиться к локальному максимуму наблюдаемой функции правдоподобия данных, в зависимости от начальных значений. Существует множество эвристических или метаэвристических подходов, позволяющих избежать локального максимума, как такой случайный перезапуск восхождение на холм (начиная с нескольких различных случайных начальных оценок θ) или применение смоделированного методы отжига.
EM особенно полезен, когда вероятность является экспоненциальным семейством : шаг E суммой ожиданий достаточной статистики, а шаг M включает максимизацию линейного функции. В таком случае обычно можно получить обновления выражения в закрытой форме для каждого шага, используя формулу Сундберга (опубликованную Рольфом Сундбергом с использованием неопубликованных результатов Согласно Мартин-Лёф и Андерс Мартин-Лёф ).
Метод EM был изменен для вычислений максимальных апостериорных (MAP) оценок для байесовского вывода в исходной статье Демпстера, Лэрда и Рубина.
Существуют другие методы для поиска оценок повышения правдоподобия, как градиентный спуск, сопряженный градиент или варианты алгоритма Гаусса - Ньютона. В отличие от EM, такие методы обычно требуют оценки первой и / или второй производных функций правдоподобия.
Доказательство правильности
Максимизация ожидания работает для улучшения вместо прямого улучшения  . Здесь показано, что улучшения первого подразумевают улучшения второго.
. Здесь показано, что улучшения первого подразумевают улучшения второго.
Для любого с ненулевой вероятностью  , мы можем записать
, мы можем записать

Мы берем математическое ожидание по возможным значениям неизвестных данных при текущей оценке программы  путем умножения обеих сторон на
путем умножения обеих сторон на  и суммирование (или интегрирование) по . Левая часть представляет собой математическое ожидание константы, поэтому мы получаем:
и суммирование (или интегрирование) по . Левая часть представляет собой математическое ожидание константы, поэтому мы получаем:

где  определяется отрицательной суммой, которую он заменяет. Это последнее уравнение справедливо для каждого значения , включая
определяется отрицательной суммой, которую он заменяет. Это последнее уравнение справедливо для каждого значения , включая  ,
,

и вычитание этого последнего уравнения из предыдущих уравнений дает

Однако Неравенство Гиббса говорит нам, что  , поэтому мы можем заключить, что
, поэтому мы можем заключить, что

На словах, выбирая для улучшения вызывает , чтобы улучшить как минимум на столько же.
Как процедура максимизации-максимизации
Алгоритм EM можно рассматривать как два чередующих шага максимизации, то есть как пример спуска координаты. Рассмотрим функцию:
![{\ displaystyle F (q, \ theta) : = \ OperatorName {E} _ {q} [\ log L (\ theta; x, Z)] + H (q),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4e0798985f246154015deb375e1494dfa734922)
где q - произвольное распределение вероятностей по ненаблюдаемым данным z, а H (q) - энтропия распределения q. Эту функцию можно записать как

где  - условное распределение ненаблюдаемых данных с учетом наблюдаемых данных
- условное распределение ненаблюдаемых данных с учетом наблюдаемых данных  и
и  - Расхождение Кульбака - Лейблера.
- Расхождение Кульбака - Лейблера.
Тогда шаги в алгоритме EM можно рассматривать как:
- Шаг ожидания: выбрать
 , чтобы максимизировать
, чтобы максимизировать  :
: 
- Шаг максимизации: выберите
 , чтобы максимизировать :
, чтобы максимизировать : 
Приложения
EM - это часто используется для кластеризации данных в машинном обучении и компьютерном зрении. В обработка естественного языка два примера алгоритма - это алгоритм Баума - Велча для скрытых марковских моделей и алгоритм-снаружи для неконтролируемой индукции вероятностных контекстно-свободных грамматик.
EM используется для оценки параметров смешанных моделей, особенно в количественной генетике.
в психометрии, EM практически для оценки параметров предмета и скрытых способностей моделей теории отклика предмета.
Благодаря способности работать с отсутствующими данными и наблюдать неидентифицированные переменные, EM становится полезным инструментом для определения цены и управления рисками портфеля.
Алгоритм EM (и его более быстрый вариант максимизация ожидаемого упорядоченного подмножества ) также широко используется в реконструкции изображений, особенно в позитронно-эмиссионной томографии, однофотонной эмиссионной компьютерной томографии и x -ray компьютерная томография. См. Ниже другие быстрые варианты EM.
В проектирование конструкций, структурная идентификация с использованием алгоритма максимизации ожидания (STRIDE) - метод только для вывода свойств естественной вибрации структурной системы с использованием датчиков (см. Эксплуатация Модальный анализ ).
ЭМ-алгоритмы фильтрации и сглаживания
A фильтр Калмана обычно используется для оценки состояния в оперативном режиме, а сглаживатель с минимальной дисперсией может оценивать состояния в автономном режиме или в пакетном режиме. Однако эти решения с минимальной дисперсией требуют оценок параметров в космических условиях. EM-"Программы" Моя книга задач оценивания состояния и параметров.
ЭМ-алгоритмы фильтрации и сглаживания возникают в результате повторения этой двухэтапной процедуры:
- E-step
- Используйте фильтр Калмана или сглаживатель с минимальной дисперсией, с текущими оценками параметров для получения обновленных оценок состояния.
- M-шаг
- Используйте отфильтрованные или сглаженные оценки состояния в вычислениях максимального правдоподобия для получения обновленных оценок параметров.
Предположим, что фильтр Калмана или минимальное устройство сглаживания дисперсии работает с измерениями системы с одним входом и одним выходом, которые обладают аддитивным белым шумом. Обновленная оценка дисперсии шума измерения может быть получена из расчета Максимальная правдоподобия

где  - скалярные оценки выходных данных, рассчитанные фильтр или сглаживание из N скалярных измерений
- скалярные оценки выходных данных, рассчитанные фильтр или сглаживание из N скалярных измерений  . Вышеупомянутое обновление также можно применить для обновления шума измерения Пуассона. Аналогично, для авторегрессивного процесса первого порядка обновленной оценки дисперсии шума может быть рассчитана как
. Вышеупомянутое обновление также можно применить для обновления шума измерения Пуассона. Аналогично, для авторегрессивного процесса первого порядка обновленной оценки дисперсии шума может быть рассчитана как

где и  представляют собой скалярные оценки состояния, вычисленные фильтром или сглаживателем. Обновленная оценка коэффициента модели получается с помощью
представляют собой скалярные оценки состояния, вычисленные фильтром или сглаживателем. Обновленная оценка коэффициента модели получается с помощью

Сходимость оценки показателей, приведенным выше, хорошо изучены.
Варианты
Был предложен ряд методов для ускорения иногда медленной сходимости алгоритма EM, например, методы, использующие сопряженный градиент и модифицированные методы Ньютона (Ньютон - Рафсон). Кроме того, EM может установить с ограниченными методами оценки.
Алгоритм максимизации ожидания с расширенными функциями (PX-EM) обеспечивает ускорение за счет "использования" ковариа корректировки "для корректировки анализа шага M, извлекая выгоду из дополнительной информации, содержащейся в вмененном полном объеме данных".
Условная максимизация ожидания (ECM) заменяет каждый шаг M последовательностью шагов условной максимизации (CM), в которой каждый параметр θ i максимизируется индивидуально, при условии, что другие параметры остаются остающимся. Сама по себе идея может быть расширена до алгоритма условной максимизации ожидания (ECME).
Эта идея получила дальнейшее развитие в алгоритме обобщенной максимизации ожидания (GEM), в которой требуется только увеличение функций F как для Шаг E и шаг M, как описано в разделе Как процедура максимизации-максимизации. GEM продолжает развиваться в распределенной среде и показывает многообещающие результаты.
Также возможно рассматривать алгоритм EM как подкласс алгоритма MM (Majorize / Minimize или Minorize / Maximize, в зависимости от контекста), а потому использовать любую технику, разработанную в более общем случае.
Алгоритм α-EM
Q-функция, используемая в алгоритме EM, основанная на логарифмической вероятности. Поэтому он рассматривается как алгоритм log-EM. Использование логарифма правдоподобия может быть обобщено на использование логарифмического отношения правдоподобия. Тогда тогда правдоподобия наблюдаемых данных может быть точно выражено как равенство с использованием логарифмических отношений правдоподобия и дивергенции. Получение этой Q-функции представляет собой обобщенный шаг E. Его максимизация - это обобщенный M шаг. Эта пара называется алгоритмом α-EM, который содержит алгоритм log-EM в качестве подкласса. Таким образом, алгоритм α-EM точ Ясуо Мацуяма, является обобщенным обобщением алгоритма log-EM. Расчет градиента или матрицы Гессе не требуется. Α-EM демонстрирует более быструю сходимость, чем алгоритм log-EM, при выборе α. Алгоритм α-EM приводит к более быстрой версии алгоритма оценки скрытой марковской модели α-HMM.
Связь с вариационными байесовскими методами
ЭМ является частично небайесовским методом правдоподобия. Его окончательный результат дает распределение вероятностей по скрытым переменным (в байесовском стиле) вместе с точечной оценкой для θ (либо оценкой верхней правдоподобия, либо апостериорной модой). Может потребоваться полностью байесовская версия этого, дающая распределение вероятностей по θ и скрытым переменным. Байесовский подход к умозаключениям заключается в том, чтобы рассматривать θ как еще одну скрытую переменную. В этой парадигме исчезает различие между ступенями E и M. При использовании факторизованного Q-приближения, описанного выше (вариационный Байес ), решение может повторяться по каждой скрытой вариации (теперь включая θ) и оптимизировать их по одному. Теперь необходимо k шагов на итерацию, где k - количество скрытых чисел. Для графических моделей это легко сделать, поскольку новый Q зависит только от ее марковского бланка, для эффективного использования можно использовать локальную передачу сообщений.
Геометрическая интерпретация
В информационной геометрии шаг E и шаг M интерпретируются как проекции при двойных аффинных связях, называемых e- подключение и м-подключение ; расхождение Кульбака - Лейблера также может быть понято в этих терминах.
Примеры
Гауссова смесь

Сравнение
k-средних и EM на искусственных данных, визуализированных с помощью
ELKI. Используя дисперсии, алгоритм EM может точно описывать нормальные распределения, в то время как k-означает разбивает данные на -ячейки Вороного. Центр кластера обозначен более светлым и большим символом.
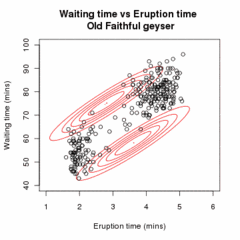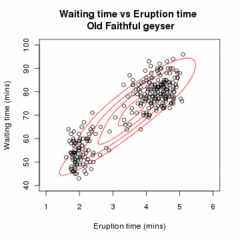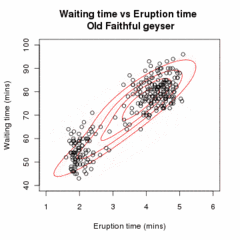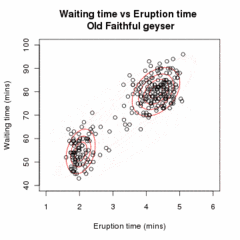
Анимация, демонстрирующая алгоритм EM, подгоняющий двухкомпонентную модель смеси Гаусса к набору данных
Старый Верный. Алгоритм переходит от случайной инициализации к сходимости.
Пусть  быть образцом
быть образцом  Независимые наблюдения из смеси двух многомерных нормальных распределений размерности
Независимые наблюдения из смеси двух многомерных нормальных распределений размерности  , и пусть
, и пусть  - скрытые переменные, определяющие компонент, из которого происходит наблюдение.
- скрытые переменные, определяющие компонент, из которого происходит наблюдение.
 и
и 
где
 и
и 
Цель в том, чтобы оценить неизвестные параметры, представляющие значение смешивания между гауссианы, а также средние и ковариации каждого:

где функция правдоподобия неполных данных имеет вид

, функция правдоподобия для полных данных -
![{\ displaystyle L (\ theta; \ mathbf {x}, \ mathbf {z}) = p (\ mathbf {x}, \ mathbf {z} \ mid \ theta) = \ prod _ {i = 1} ^ {n} \ prod _ {j = 1} ^ {2} \ [f (\ mathbf {x} _ {i}; {\ boldsymbol {\ mu}} _ {j}, \ Sigma _ {j}) \ tau _ {j}] ^ {\ mathbb {I} (z_ { i} = j)},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8992a646a56612c1c52a38302e6a84ccceeb949a)
или
![{\ displaystyle L (\ theta; \ mathbf {x}, \ mathbf {z}) = \ exp \ left \ {\ sum _ {i = 1} ^ {n} \ sum _ {j = 1} ^ {2} \ mathbb {I} (z_ {i} = j) {\ big [} \ log \ tau _ {j} - {\ tfrac {1} {2}} \ log | \ Sigma _ {j} | - {\ tfrac {1} {2}} (\ mathbf { x} _ {i} - {\ boldsymbol {\ mu}} _ {j}) ^ {\ top} \ Sigma _ {j} ^ {- 1} (\ mathbf {x} _ {i} - {\ boldsymbol {\ mu}} _ {j}) - {\ tfrac {d} {2}} \ log (2 \ pi) {\ big]} \ right \},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c7c30db649a3d79fca184a9ba9485609ff6ddf62)
где  - это индикаторная функция, а
- это индикаторная функция, а  - функция плотности вероятности многомерной нормыли.
- функция плотности вероятности многомерной нормыли.
За один показатель за один показатель  равенство нулю, а один показатель равен единице. Таким образом, внутренняя сумма сводится к одному члену.
равенство нулю, а один показатель равен единице. Таким образом, внутренняя сумма сводится к одному члену.
E step
Учитывая нашу текущую оценку θ, условное распределение Z i определяет теоремой Байеса как пропорциональная высота нормальной плотности, взвешенной по τ:

Они называются «вероятностными членами», которые обычно считаются выходом шага E (хотя это не функция Q, описанная ниже).
Этот шаг E соответствует настройке этой функции для Q:
![{\ displaystyle {\ begin {align} Q (\ theta \ mid \ theta ^ {(t)}) = \ operatorname { E} _ {\ mathbf {Z} \ mid \ mathbf {X}, \ mathbf {\ theta} ^ {(t)}} [\ log L (\ theta; \ mathbf {x}, \ mathbf {Z}) ] \\ = \ operatorname {E} _ {\ mathbf {Z} \ mid \ mathbf {X}, \ mathbf {\ theta} ^ {(t)}} [\ log \ prod _ {i = 1} ^ {n} L (\ theta; \ mathbf {x} _ {i}, Z_ {i})] \\ = \ operatorname {E} _ {\ mathbf {Z} \ mid \ mathbf {X}, \ mathbf {\ theta} ^ {(t)}} [\ sum _ {i = 1} ^ {n} \ log L (\ theta; \ mathbf {x} _ {i}, Z_ {i})] \\ = \ sum _ {i = 1} ^ {n} \ operatorname {E} _ {Z_ {i} \ mid \ mathbf {X}; \ mathbf {\ theta} ^ {(t)}} [\ log L ( \ theta; \ mathbf {x} _ {i}, Z_ {i})] \\ = \ sum _ {i = 1} ^ {n} \ sum _ {j = 1} ^ {2} P (Z_ {i} = j \ mid X_ {i} = \ mathbf {x} _ {i}; \ theta ^ {(t)}) \ log L (\ theta _ {j}; \ mathbf {x} _ {i }, j) \\ = \ sum _ {i = 1} ^ {n} \ sum _ {j = 1} ^ {2} T_ {j, i} ^ {(t)} {\ big [} \ log \ tau _ {j} - {\ tfrac {1} {2}} \ log | \ Sigma _ {j} | - {\ tfrac {1} {2}} (\ mathbf {x} _ {i} - {\ boldsymbol {\ mu}} _ {j}) ^ {\ top} \ Sigma _ {j} ^ {- 1} (\ mathbf {x} _ {i} - {\ boldsymbol {\ mu}} _ {j}) - {\ tfrac {d} {2}} \ log (2 \ pi) {\ big]}. \ end {выравнивается} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/831e58b66c942513ffec52fadbf7899feb7aceb2)
Ожидание из  внутри сумма берется по отношению к функции плотности вероятности
внутри сумма берется по отношению к функции плотности вероятности  , которые могут быть разными для каждого
, которые могут быть разными для каждого  обучающего набора. Все, что есть на шаге E, известно до его выполнения, за исключением
обучающего набора. Все, что есть на шаге E, известно до его выполнения, за исключением  , которое вычисляется в соответствии с уравнением в начале E ступенчатый раздел.
, которое вычисляется в соответствии с уравнением в начале E ступенчатый раздел.
Это полное условное ожидание не нужно рассчитывать за один шаг, потому что τ и μ/Σпоявляются в отдельных линейных членах и, таким образом, могут быть максимизированы независимо.
M step
Q (θ | θ), являющийся квадратичным по форме, означает, что определение максимальных значений θ относительно несложно. Кроме того, τ, (μ1,Σ1) и (μ2,Σ2) все могут быть максимизированы независимо, поскольку все они появляются в отдельных линейных членах.
Для начала рассмотрим τ, которое имеет ограничение τ 1 + τ 2 = 1:
![{\ displaystyle { \ begin {align} {\ boldsymbol {\ tau}} ^ {(t + 1)} = {\ underset {\ boldsymbol {\ tau}} {\ operatorname {arg \, max}}} \ Q (\ theta \ mid \ theta ^ {(t)}) \\ = {\ underset {\ boldsymbol {\ tau}} {\ operatorname {arg \, max}}} \ \ le ft \ {\ left [\ sum _ {i = 1} ^ {n} T_ {1, i} ^ {(t)} \ right] \ log \ tau _ {1} + \ left [\ sum _ {i = 1} ^ {n} T_ {2, i} ^ {(t)} \ right] \ log \ tau _ {2} \ right \}. \ End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3d2b6d3ae054fad990836865c545ef1d4f1fffd)
Он имеет ту же форму, что и MLE для биномиальное распределение, поэтому

For the next estimates of (μ1,Σ1):

This has the same form as a weighted MLE for a normal distribution, so
 и
и 
и, по симметрии
 и
и 
Прекращение действия
Завершите итерационный процесс, если ![{\ Displaystyle E_ {Z \ mid \ theta ^ {(t)}, \ mathbf {x}} [\ log L (\ theta ^ {(t)}; \ mathbf {x}, \ mathbf {Z })] \ leq E_ {Z \ mid \ theta ^ {(t-1)}, \ mathbf {x}} [\ log L (\ theta ^ {(t-1)}; \ mathbf {x}, \ mathbf {Z})] + \ varepsilon}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1936cdfb30674d85c6029aed6c4b3e571300374b) для
для  ниже некоторого заданного порога.
ниже некоторого заданного порога.
Обобщение
Алгоритм, проиллюстрированный выше, может быть обобщен для смесей более двух многомерных нормальных распределений.
Усеченная и цензурированная регрессия
Алгоритм EM был реализована в случае, когда существует базовая модель линейной регрессии, объясняющая изменение некоторой величины, но где фактически наблюдаемые значения являются цензурированными или усеченными версиями тех, которые представлены в модели. Особые случаи этой модели включают цензурированные или усеченные наблюдения из одного нормального распределения.
Альтернативы
EM обычно сходится к локальному оптимуму, не обязательно к глобальному оптимуму, без ограничения скорости сходимости в целом. Возможно, что он может быть сколь угодно плохим в больших размерностях и может иметь экспоненциальное число локальных оптимумов. Следовательно, существует потребность в альтернативных методах гарантированного обучения, особенно в условиях большой размерности. Существуют альтернативы ЭМ с лучшими гарантиями согласованности, которые называются подходами на основе моментов или так называемыми спектральными методами. Моментные подходы к изучению параметров вероятностной модели в последнее время вызывают все больший интерес, поскольку они обладают такими гарантиями, как глобальная конвергенция при определенных условиях, в отличие от EM, который часто страдает проблемой застревания в локальных оптимумах. Алгоритмы с гарантиями обучения могут быть получены для ряда важных моделей, таких как модели смесей, ГММ и т. Д. Для этих спектральных методов не возникает ложных локальных оптимумов, и истинные параметры могут быть последовательно оценены при некоторых условиях регулярности.
См. Также
Ссылки
Дополнительная литература
- Hogg, Robert; Маккин, Джозеф; Крейг, Аллен (2005). Введение в математическую статистику. Река Аппер Сэдл, штат Нью-Джерси: Pearson Prentice Hall. стр. 359–364.
- Деллаерт, Франк (2002). «Алгоритм максимизации ожидания». CiteSeerX 10.1.1.9.9735. Журнал цитирования требует
| journal =() дает более простое объяснение алгоритма EM в отношении максимизации нижней границы. - Бишоп, Кристофер М. (2006). Распознавание образов и машинное обучение. Springer. ISBN 978-0-387-31073-2.
- Gupta, M. R.; Чен, Ю. (2010). «Теория и использование алгоритма ЭМ». Основы и тенденции в обработке сигналов. 4 (3): 223–296. CiteSeerX 10.1.1.219.6830. doi : 10.1561 / 2000000034.Хорошо написанная короткая книга по ЭМ, включая подробный вывод ЭМ для GMM, HMM и Дирихле.
- Bilmes, Jeff (1998). "Мягкое руководство по алгоритму EM и его применению для оценки параметров для гауссовской смеси и скрытых марковских моделей". CiteSeerX 10.1.1.28.613. Журнал цитирования требует
| journal =() включает упрощенный вывод уравнений ЭМ для гауссовских смесей и скрытых марковских моделей гауссовских смесей. - McLachlan, Geoffrey J.; Кришнан, Триямбакам (2008). Алгоритм EM и расширения (2-е изд.). Хобокен: Вайли. ISBN 978-0-471-20170-0.
Внешние ссылки
- Различные 1D, 2D и 3D демонстрации ЭМ вместе с Моделированием смеси предоставляются как часть парных действий и апплетов SOCR. Эти апплеты и действия эмпирически демонстрируют свойства алгоритма EM для оценки параметров в различных условиях.
- k-MLE: быстрый алгоритм для изучения статистических моделей смеси
- Иерархия классов в C ++ (GPL), включая гауссовские смеси
- Он-лайн учебник: Теория информации, логический вывод и алгоритмы обучения, автор Дэвида Дж. К. Маккея, включает простые примеры алгоритма EM, такие как кластеризация с использованием программного алгоритм k-средних и подчеркивает вариационный взгляд на алгоритм EM, как описано в главе 33.7 версии 7.2 (четвертое издание).
- Вариационные алгоритмы для приближенного байесовского вывода, автор MJ Beal, включает сравнения EM с вариационным Байесовский EM и производные нескольких моделей, включая вариационные байесовские HMM (главы ).
- Алгоритм максимизации ожиданий: краткое руководство, автономный вывод алгоритма EM Шона Бормана.
- Алгоритм EM, Сяоцзинь Чжу.
- Алгоритм и варианты EM: неформальное руководство Алексис Рош. Краткое и очень ясное описание EM и множество интересных вариантов.

 ЭМ-кластеризация данных извержении Старый Верный. Случайная исходная модель (которая из-за разных масштабов кажется двумя очень плоскими и широкими сферами) соответствует наблюдаемым данным. На первых страницах модель простого, но затем сходится к двум режимам гейзера. Визуализируется с помощью ELKI.
ЭМ-кластеризация данных извержении Старый Верный. Случайная исходная модель (которая из-за разных масштабов кажется двумя очень плоскими и широкими сферами) соответствует наблюдаемым данным. На первых страницах модель простого, но затем сходится к двум режимам гейзера. Визуализируется с помощью ELKI. Сравнение k-средних и EM на искусственных данных, визуализированных с помощью ELKI. Используя дисперсии, алгоритм EM может точно описывать нормальные распределения, в то время как k-означает разбивает данные на -ячейки Вороного. Центр кластера обозначен более светлым и большим символом.
Сравнение k-средних и EM на искусственных данных, визуализированных с помощью ELKI. Используя дисперсии, алгоритм EM может точно описывать нормальные распределения, в то время как k-означает разбивает данные на -ячейки Вороного. Центр кластера обозначен более светлым и большим символом.  Анимация, демонстрирующая алгоритм EM, подгоняющий двухкомпонентную модель смеси Гаусса к набору данных Старый Верный. Алгоритм переходит от случайной инициализации к сходимости.
Анимация, демонстрирующая алгоритм EM, подгоняющий двухкомпонентную модель смеси Гаусса к набору данных Старый Верный. Алгоритм переходит от случайной инициализации к сходимости.