
Войти
A рекуррентная нейронная сеть (RNN ), является класс искусственных нейронных сетей, в котором соединения между узлами образуют ориентированный граф во временной последовательности. Это позволяет ему демонстрировать динамическое поведение во времени. Полученные из нейронных сетей прямого распространения, RNN могут использовать свое внутреннее состояние (память) для обработки последовательностей входных данных переменной длины. Это делает их применимыми к таким задачам, как несегментированное связанное распознавание рукописного ввода или распознавание речи.
. Термин «рекуррентная нейронная сеть» используется без разбора для обозначения двух широких классов сетей с одинаковыми общими характеристиками. структура, где один - конечный импульс, а другой - бесконечный импульс. Оба класса сетей демонстрируют временное динамическое поведение. Конечная импульсная рекуррентная сеть - это направленный ациклический граф, который можно развернуть и заменить нейронной сетью со строго прямой связью, в то время как бесконечная импульсная рекуррентная сеть - это направленный циклический граф, который не может быть развернутый.
И конечные импульсные, и бесконечные импульсные рекуррентные сети могут иметь дополнительные сохраненные состояния, и хранилище может находиться под непосредственным контролем нейронной сети. Хранилище также может быть заменено другой сетью или графиком, если он включает временные задержки или имеет петли обратной связи. Такие контролируемые состояния называются стробированными состояниями или стробированной памятью и являются частью сетей с долговременной краткосрочной памятью (LSTM) и стробированных рекуррентных блоков. Это также называется нейронной сетью с обратной связью (FNN).
Рекуррентные нейронные сети были основаны на работе Дэвида Рамелхарта в 1986 году. Hopfield ne tworks - особый вид RNN - был обнаружен Джоном Хопфилдом в 1982 году. В 1993 году система компрессора нейронной истории решила задачу «очень глубокого обучения», которая требовала более 1000 последующих слоев в RNN разворачивалась во времени.
Сети с долговременной краткосрочной памятью (LSTM) были изобретены Хохрайтером и Шмидхубером в 1997 году и устанавливали точность записи в нескольких доменах приложений.
Примерно в 2007 году LSTM начала революцию в распознавании речи, превзойдя традиционные модели в некоторых речевых приложениях. В 2009 году сеть LSTM, обученная Connectionist Temporal Classification (CTC), стала первой RNN, которая выиграла соревнования по распознаванию образов, когда она выиграла несколько соревнований по подключенному распознаванию рукописного ввода. В 2014 году китайский поисковый гигант Baidu использовал обученные CTC RNN, чтобы преодолеть эталон распознавания речи Switchboard Hub5'00 без использования традиционных методов обработки речи.
LSTM также улучшил распознавание речи с большим словарем и синтез преобразования текста в речь и использовался в Google Android. Сообщается, что в 2015 году производительность распознавания речи Google резко выросла на 49% благодаря обученному CTC LSTM, который использовался в 17.
LSTM побил рекорды по улучшенному машинному переводу, Языковое моделирование и многоязычная языковая обработка. LSTM в сочетании с сверточными нейронными сетями (CNN) улучшили автоматические подписи к изображениям. Учитывая накладные расходы на вычисления и память при запуске LSTM, были предприняты усилия по ускорению LSTM с помощью аппаратных ускорителей.
RNN бывают во многих вариантах.
 Развернутая базовая рекуррентная нейронная сеть
Развернутая базовая рекуррентная нейронная сеть Базовые RNN представляют собой сеть из нейроноподобных узлов, организованных в последовательные уровни. Каждый узел на данном уровне связан с направленным (односторонним) соединением с каждым другим узлом в следующем последующем уровне. Каждый узел (нейрон) имеет изменяющуюся во времени действительную активацию. Каждое соединение (синапс) имеет изменяемый действительный вес . Узлы - это либо входные узлы (получающие данные извне сети), выходные узлы (выдающие результаты), либо скрытые узлы (которые изменяют данные по пути от входа к выходу).
Для контролируемого обучения в настройках дискретного времени, последовательности входных векторов с действительным знаком поступают во входные узлы, по одному вектору за раз. На любом заданном временном шаге каждый не входящий блок вычисляет свою текущую активацию (результат) как нелинейную функцию взвешенной суммы активаций всех блоков, которые к нему подключены. Заданные супервизором целевые активации могут быть предоставлены для некоторых выходных устройств в определенные временные интервалы. Например, если входная последовательность представляет собой речевой сигнал, соответствующий произнесенной цифре, конечный целевой выход в конце последовательности может быть меткой, классифицирующей цифру.
В настройках обучения с подкреплением ни один учитель не подает целевые сигналы. Вместо этого для оценки производительности RNN иногда используется функция пригодности или функция вознаграждения, которая влияет на ее входной поток через блоки вывода, подключенные к исполнительным механизмам, которые влияют на окружающую среду. Это может быть использовано для игры, в которой прогресс измеряется количеством выигранных очков.
Каждая последовательность дает ошибку как сумму отклонений всех целевых сигналов от соответствующих активаций, вычисленных сетью. Для обучающего набора из множества последовательностей общая ошибка - это сумма ошибок всех отдельных последовательностей.
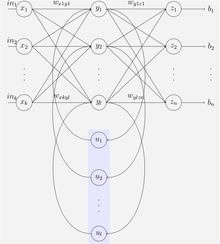 Сеть Элмана
Сеть Элмана Сеть Элмана представляет собой трехуровневую сеть (на рисунке расположена горизонтально как x, y и z) с добавление набора контекстных единиц (u на иллюстрации). Средний (скрытый) уровень связан с этими блоками контекста с весом, равным единице. На каждом временном шаге ввод передается вперед, и применяется правило обучения . Фиксированные обратные соединения сохраняют копию предыдущих значений скрытых единиц в единицах контекста (поскольку они распространяются по соединениям до применения правила обучения). Таким образом, сеть может поддерживать своего рода состояние, позволяя ей выполнять такие задачи, как предсказание последовательности, которые выходят за рамки возможностей стандартного многослойного персептрона.
сети Jordan, аналогичного сетям Элмана. Единицы контекста загружаются из выходного слоя вместо скрытого. Блоки контекста в сети Иордании также называются уровнем состояния. У них есть периодическая связь между собой.
Сети Элмана и Джордана также известны как «Простые рекуррентные сети» (SRN).


Переменные и функции
 : вектор ввода
: вектор ввода : вектор скрытого слоя
: вектор скрытого слоя : выходной вектор
: выходной вектор ,
,  и
и  : матрицы параметров и вектор
: матрицы параметров и вектор и
и  : Функции активации
: Функции активации Сеть Хопфилда - это RNN, в которой все соединения симметричны. Он требует стационарных входов и, таким образом, не является общей RNN, поскольку не обрабатывает последовательности шаблонов. Это гарантирует, что он сойдется. Если соединения обучаются с использованием обучения Hebbian, тогда сеть Хопфилда может работать как надежная память с адресацией по содержанию, устойчивая к изменению соединения.
Представленная Бартом Коско, двунаправленная ассоциативная память (BAM) представляет собой вариант сети Хопфилда, в которой ассоциативные данные хранятся в виде вектора. Двунаправленность возникает из-за прохождения информации через матрицу и ее транспонирования. Обычно биполярное кодирование предпочтительнее двоичного кодирования ассоциативных пар. В последнее время стохастические модели BAM с использованием марковского степпинга были оптимизированы для повышения стабильности сети и соответствия реальным приложениям.
Сеть BAM имеет два уровня, каждый из которых может использоваться в качестве входа для вызова ассоциации и создания вывода на другом уровне.
Сеть состояний эхо (ESN) имеет редко связанный случайный скрытый слой. Веса выходных нейронов - единственная часть сети, которая может изменяться (обучаться). ESN хорошо воспроизводят определенные временные ряды. Вариант для нейронов с пиками известен как машина с жидкими состояниями.
. в традиционной полносвязной РНС. Каждый нейрон в одном слое получает только свое прошлое состояние в качестве контекстной информации (вместо полной связи со всеми другими нейронами в этом слое), и, таким образом, нейроны не зависят от истории друг друга. Обратное распространение градиента можно регулировать, чтобы избежать исчезновения и увеличения градиента, чтобы сохранить долгосрочную или краткосрочную память. Информация о кросс-нейронах исследуется на следующих уровнях. IndRNN можно надежно обучить с помощью ненасыщенных нелинейных функций, таких как ReLU. С помощью пропуска соединений можно обучать глубокие сети.
A рекурсивная нейронная сеть создается путем применения того же набора весов рекурсивно над дифференцируемой графоподобной структурой путем обхода структуры в топологическом порядке. Такие сети обычно также обучаются в обратном режиме автоматического дифференцирования. Они могут обрабатывать распределенные представления структуры, такие как логические термины. Частным случаем рекурсивных нейронных сетей является РНС, структура которой соответствует линейной цепочке. Рекурсивные нейронные сети были применены к обработке естественного языка. Рекурсивная нейронная тензорная сеть использует функцию композиции на основе тензора для всех узлов в дереве.
Компрессор нейронной истории представляет собой неконтролируемый стек RNN. На уровне ввода он учится предсказывать свой следующий ввод на основе предыдущих вводов. Только непредсказуемые входы некоторой RNN в иерархии становятся входами для RNN следующего более высокого уровня, которая поэтому повторно вычисляет свое внутреннее состояние только изредка. Таким образом, каждая RNN более высокого уровня изучает сжатое представление информации в RNN ниже. Это делается таким образом, чтобы входная последовательность могла быть точно реконструирована из представления на самом высоком уровне.
Система эффективно минимизирует длину описания или отрицательный логарифм вероятности данных. Учитывая большую предсказуемость обучения в последовательности входящих данных, RNN самого высокого уровня может использовать контролируемое обучение, чтобы легко классифицировать даже глубокие последовательности с длинными интервалами между важными событиями.
Можно разделить иерархию RNN на две RNN: «сознательный» блок (более высокий уровень) и «подсознательный» автоматизатор (более низкий уровень). После того, как блокировщик научился предсказывать и сжимать входные данные, которые непредсказуемы автоматизатором, автоматизатор может быть вынужден на следующей фазе обучения предсказывать или имитировать с помощью дополнительных блоков скрытые блоки более медленно изменяющегося блока. Это позволяет автоматизатору легко запоминать подходящие, редко меняющиеся воспоминания через длительные промежутки времени. В свою очередь, это помогает автоматизатору сделать многие из его некогда непредсказуемых входных данных предсказуемыми, так что блок может сосредоточиться на оставшихся непредсказуемых событиях.
A Генеративная модель частично преодолела проблему исчезающего градиента из автоматическое дифференцирование или обратное распространение в нейронных сетях в 1992 году. В 1993 году такая система решила задачу «очень глубокого обучения», которая требовала более 1000 последующих слоев в RNN, развернутых во времени.
RNN второго порядка используют веса более высокого порядка 

 Единица долговременной кратковременной памяти
Единица долговременной кратковременной памяти Долговременная кратковременная память (LSTM) - это система глубокого обучения, которая избегает исчезающего градиента проблема. LSTM обычно дополняется повторяющимися воротами, называемыми «воротами забывания». LSTM предотвращает исчезновение или распространение ошибок с обратным распространением. Вместо этого ошибки могут течь в обратном направлении через неограниченное количество виртуальных слоев, развернутых в пространстве. То есть LSTM может изучать задачи, требующие воспоминаний о событиях, произошедших на тысячи или даже миллионы дискретных временных шагов ранее. Топологии, подобные LSTM, могут быть разработаны для конкретных задач. LSTM работает даже при длительных задержках между важными событиями и может обрабатывать сигналы, которые смешивают низкочастотные и высокочастотные компоненты.
Многие приложения используют стеки LSTM RNN и обучают их с помощью Connectionist Temporal Classification (CTC), чтобы найти матрицу весов RNN, которая максимизирует вероятность последовательностей меток в обучающем наборе, учитывая соответствующие входные последовательности. СТС добивается согласованности и признания.
LSTM может научиться распознавать контекстно-зависимые языки в отличие от предыдущих моделей, основанных на скрытых марковских моделях (HMM) и аналогичных концепциях.
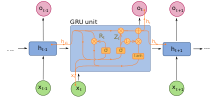 Стробируемый повторяющийся модуль
Стробируемый повторяющийся модуль Стробируемый рекуррентный модуль (GRU) - это стробирующий механизм в рекуррентных нейронных сетях, представленных в 2014 году. Они используются в полной форме и в нескольких упрощенных вариантах. Их производительность при моделировании полифонической музыки и моделирования речевых сигналов оказалась аналогичной работе с долговременной кратковременной памятью. У них меньше параметров, чем у LSTM, так как у них нет выходного вентиля.
Двунаправленные RNN используют конечную последовательность для прогнозирования или маркировки каждого элемента последовательности на основе элемента прошлые и будущие контексты. Это делается путем объединения выходных данных двух RNN, одна обрабатывает последовательность слева направо, а другая - справа налево. Комбинированные выходные данные - это предсказания заданных учителем целевых сигналов. Доказано, что этот метод особенно полезен в сочетании с LSTM RNN.
Постоянно-рекуррентная нейронная сеть (CTRNN) использует систему обыкновенных дифференциальных уравнений, чтобы смоделировать воздействие на нейрон входящей последовательности шипов.
Для нейрона 


Где:
 : постоянная времени постсинаптического узла: активация постсинаптического узла
: постоянная времени постсинаптического узла: активация постсинаптического узла : Скорость изменения активации постсинаптического узла
: Скорость изменения активации постсинаптического узла : Вес соединения от пре до постсинаптического узла
: Вес соединения от пре до постсинаптического узла : сигмоид x, например.
: сигмоид x, например.  .
. : активация пресинаптического узла
: активация пресинаптического узла : смещение пресинаптического узла
: смещение пресинаптического узла : входные данные (если есть) для узла
: входные данные (если есть) для узлаCTRNN были применены к эволюционной робототехнике, где они использовались для решения проблем зрения, сотрудничества, и минимальное когнитивное поведение.
Обратите внимание, что в соответствии с теоремой Шеннона рекуррентные нейронные сети с дискретным временем можно рассматривать как рекуррентные нейронные сети с непрерывным временем, в которых дифференциальные уравнения преобразованы в эквивалентные разностные уравнения. Это преобразование можно рассматривать как происходящее после того, как функции активации постсинаптического узла 
Иерархические RNN различными способами соединяют свои нейроны, чтобы разложить иерархическое поведение на полезные подпрограммы.
Как правило, рекуррентная многослойная сеть перцептронов (RMLP) состоит из каскадных подсетей, каждая из которых содержит несколько уровней узлов. Каждая из этих подсетей является прямой, за исключением последнего уровня, который может иметь обратные связи. Каждая из этих подсетей соединена только соединениями с прямой связью.
Рекуррентная нейронная сеть с несколькими масштабами времени (MTRNN) - это вычислительная модель на основе нейронных сетей, которая может имитировать функциональную иерархию мозг через самоорганизацию, которая зависит от пространственной связи между нейронами и от различных типов активности нейронов, каждый из которых имеет свои временные свойства. При такой разнообразной нейронной активности непрерывные последовательности любого набора поведений сегментируются в примитивы многократного использования, которые, в свою очередь, гибко интегрируются в разнообразные последовательные поведения. Биологическое одобрение такого типа иерархии обсуждалось в теории предсказания памяти функции мозга Хокинса в его книге Об интеллекте.
Нейронные машины Тьюринга (NTM) - это метод расширения рекуррентных нейронных сетей путем связывания их с внешними ресурсами памяти, с которыми они могут взаимодействовать. Комбинированная система аналогична машине Тьюринга или архитектуре фон Неймана, но является дифференцируемой сквозной, что позволяет ее эффективно обучать с помощью градиентный спуск.
Дифференцируемые нейронные компьютеры (DNC) - это расширение нейронных машин Тьюринга, позволяющее использовать нечеткие значения каждого адреса памяти и запись хронологии.
Нейросетевые выталкивающие автоматы (NNPDA) похожи на NTM, но ленты заменяются аналоговыми стеками, которые дифференцируются и обучаются. В этом смысле они похожи по сложности на распознаватели контекстно-свободных грамматик (CFG).
Грег Снайдер из HP Labs описывает систему корковых вычислений с мемристивными наноустройствами. мемристоры (резисторы памяти) выполнены из тонкопленочных материалов, в которых сопротивление электрически регулируется посредством переноса ионов или кислородных вакансий внутри пленки. Проект DARPA SyNAPSE профинансировал исследования IBM и HP Labs в сотрудничестве с Департаментом когнитивных и нейронных систем (CNS) Бостонского университета для разработки нейроморфных архитектур, которые могут быть основаны на мемристивные системы. Мемристивные сети - это особый тип физической нейронной сети, которая имеет очень похожие свойства с (Литтл-) сетями Хопфилда, поскольку они имеют непрерывную динамику, ограниченный объем памяти и естественным образом расслабляются за счет минимизации функция, которая асимптотична модели Изинга. В этом смысле динамика мемристической схемы имеет преимущество по сравнению с схемой резистор-конденсатор в том, что она имеет более интересное нелинейное поведение. С этой точки зрения разработка аналоговых мемристивных сетей представляет собой особый тип нейроморфной инженерии, в которой поведение устройства зависит от схемы или топологии.
Градиентный спуск - это оптимизация первого порядка итеративная алгоритм для поиска минимума функции. В нейронных сетях его можно использовать для минимизации члена ошибки путем изменения каждого веса пропорционально производной ошибки по этому весу, при условии, что нелинейные функции активации являются дифференцируемыми. Различные методы для этого были разработаны в 1980-х и начале 1990-х годов Вербосом, Уильямсом, Робинсоном, Шмидхубером, Хохрайтером., Перлмуттер и другие.
Стандартный метод называется «обратным распространением во времени » или BPTT и является обобщением обратного распространения для сетей с прямой связью. Подобно этому методу, это пример автоматического дифференцирования в режиме обратного накопления принципа минимума Понтрягина. Более затратный с точки зрения вычислений онлайновый вариант называется «Рекуррентное обучение в реальном времени» или RTRL, который является примером автоматического дифференцирования в режиме прямого накопления со сложенными касательными векторами. В отличие от BPTT, этот алгоритм является локальным во времени, но не локальным в пространстве.
В этом контексте локальный в пространстве означает, что вектор веса единицы может быть обновлен с использованием только информации, хранящейся в подключенных единицах и самой единице, так что сложность обновления отдельной единицы линейна по размерности веса. вектор. Локальный по времени означает, что обновления происходят постоянно (онлайн) и зависят только от самого последнего временного шага, а не от нескольких временных шагов в пределах заданного временного горизонта, как в BPTT. Биологические нейронные сети кажутся локальными по отношению как к времени, так и по пространству.
Для рекурсивного вычисления частных производных RTRL имеет временную сложность O (количество скрытых x количество весов) на временной шаг для вычисления матриц Якоби, в то время как BPTT принимает только O (количество весов) за временной шаг за счет сохранения всех прямых активаций в пределах данного временного горизонта. Существует онлайн-гибрид между BPTT и RTRL с промежуточной сложностью, а также варианты для непрерывного времени.
Основная проблема с градиентным спуском для стандартных архитектур RNN заключается в том, что градиенты ошибок исчезают экспоненциально быстро с размер временного интервала между важными событиями. LSTM в сочетании с гибридным методом обучения BPTT / RTRL пытается решить эти проблемы. Эта проблема также решается в независимой рекуррентной нейронной сети (IndRNN) за счет сведения контекста нейрона к его собственному прошлому состоянию, а информация о кросс-нейроне может быть затем исследована на следующих уровнях. Воспоминания различного диапазона, включая долговременную память, могут быть изучены без проблемы исчезновения и взрыва градиента.
Он-лайн алгоритм, называемый причинно-рекурсивным обратным распространением (CRBP), реализует и объединяет парадигмы BPTT и RTRL для локально рекуррентных сетей. Он работает с наиболее распространенными локально повторяющимися сетями. Алгоритм CRBP может минимизировать глобальную ошибку. Этот факт повышает стабильность алгоритма, обеспечивая единый взгляд на методы расчета градиента для рекуррентных сетей с локальной обратной связью.
Один подход к вычислению градиентной информации в RNN с произвольной архитектурой основан на схематическом выводе графов потока сигналов. Он использует пакетный алгоритм BPTT, основанный на теореме Ли для расчета чувствительности сети. Его предложили Ван и Бофайс, а его быстрая онлайн-версия была предложена Камполуччи, Унчини и Пиацца.
Обучение весов в нейронной сети можно смоделировать как не -линейная задача глобальной оптимизации. Целевая функция может быть сформирована для оценки соответствия или ошибки конкретного вектора весов следующим образом: сначала веса в сети устанавливаются в соответствии с вектором весов. Затем сеть сравнивается с обучающей последовательностью. Обычно сумма квадратов разности между предсказаниями и целевыми значениями, указанными в обучающей последовательности, используется для представления ошибки текущего вектора весовых коэффициентов. Затем можно использовать произвольные методы глобальной оптимизации, чтобы минимизировать эту целевую функцию.
Наиболее распространенный метод глобальной оптимизации для обучения RNN - это генетические алгоритмы, особенно в неструктурированных сетях.
Первоначально генетический алгоритм кодируется с помощью весов нейронной сети в предопределенный способ, при котором один ген в хромосоме представляет одну весовую связь. Вся сеть представлена в виде одной хромосомы. Функция пригодности оценивается следующим образом:
Многие хромосомы составляют популяцию; поэтому многие разные нейронные сети развиваются до тех пор, пока не будет удовлетворен критерий остановки. Типичная схема остановки:
Критерий остановки оценивается функцией приспособленности, поскольку он получает обратную величину среднеквадратичной ошибки от каждой сети во время обучения. Следовательно, цель генетического алгоритма - максимизировать функцию приспособленности, уменьшая среднеквадратичную ошибку.
Для поиска подходящего набора весов могут использоваться другие методы глобальной (и / или эволюционной) оптимизации, такие как моделируемый отжиг или оптимизация роя частиц.
RNN могут вести себя хаотично. В таких случаях для анализа может использоваться теория динамических систем.
На самом деле это рекурсивные нейронные сети с определенной структурой: линейной цепочкой. В то время как рекурсивные нейронные сети работают с любой иерархической структурой, комбинируя дочерние представления с родительскими представлениями, рекуррентные нейронные сети работают с линейной прогрессией времени, комбинируя предыдущий временной шаг и скрытое представление в представление для текущего временного шага.
В частности, RNN могут появляться как нелинейные версии фильтров с конечной импульсной характеристикой и с бесконечной импульсной характеристикой, а также как нелинейная авторегрессионная экзогенная модель (NARX).
Приложения рекуррентных нейронных сетей включают: