
Войти
| Локальная шина PCI | |
 Три 5-вольтовых 32-битные слоты расширения PCI на материнской плате (кронштейн ПК с левой стороны) Три 5-вольтовых 32-битные слоты расширения PCI на материнской плате (кронштейн ПК с левой стороны) | |
| Год создания | 22 июня 1992 г.; 28 лет назад (1992-06-22) |
|---|---|
| Создано | Intel |
| Заменяет | ISA, EISA, MCA, VLB |
| Заменено на | PCI Express (2004) |
| Ширина в битах | 32 или 64 |
| Скорость | Полудуплекс :. 133 МБ / с (32-бит на 33 МГц - стандартная конфигурация). 266 МБ / с (32-бит на 66 МГц). 266 МБ / с (64-бит на 33 МГц). 533 МБ / с (64-бит, 66 МГц) |
| Стиль | Параллельный |
| Интерфейс горячего подключения | Необязательно |
| Веб-сайт | www.pcisig.com / home |
Peripheral Component Interconnect (PCI ) - это локальный компьютер шина для подключения оборудования устройств в компьютере и является частью стандарта локальной шины PCI. Шина PCI поддерживает функции шины процессора , но в стандартизованном формате, который не зависит от собственной шины процессора . Устройства, подключенные к шине PCI, кажутся мастеру шины подключенными непосредственно к его собственной шине, и им назначаются адреса в адресном пространстве процессора. Это параллельная шина, синхронная с одной тактовой частотой шины . Присоединенные устройства могут иметь форму интегральной схемы, установленной на самой материнской плате (называемой в спецификации PCI планарным устройством), либо в виде платы расширения , которая подходит в слот. Локальная шина PCI была впервые реализована в IBM PC-совместимых, где она заменила комбинацию нескольких медленных слотов Industry Standard Architecture (ISA) и одной быстрой локальной шины VESA <56.>слот как конфигурация шины. Впоследствии он был адаптирован для других типов компьютеров. Типичные карты PCI, используемые в ПК, включают: сетевые карты, звуковые карты, модемы, дополнительные порты, такие как USB или последовательный, ТВ-тюнеры и контроллеры дисков. Видеокарты PCI заменили карты ISA и VESA до тех пор, пока растущие требования к пропускной способности не превзошли возможности PCI. Затем предпочтительным интерфейсом для видеокарт стал AGP, который сам по себе является расширенным набором PCI, прежде чем уступить место PCI Express.
Первой версией PCI, обнаруженной в розничных настольных компьютерах, была 32-битная шина с тактовой частотой шины 33 МГц и сигнализацией 5 В, хотя стандарт PCI 1.0 также предусматривал 64-битный вариант. У них есть одна фиксирующая выемка на карте. Версия 2.0 стандарта PCI представила слоты на 3,3 В, физически отличающиеся перевернутым физическим разъемом для предотвращения случайной вставки карт 5 В. Универсальные карты, которые могут работать от любого напряжения, имеют две выемки. Версия 2.1 стандарта PCI представила опциональную работу на частоте 66 МГц. Ориентированный на сервер вариант PCI, PCI-X (PCI Extended) работал на частотах до 133 МГц для PCI-X 1.0 и до 533 МГц для PCI-X 2.0. Внутренний разъем для карт портативных компьютеров, названный Mini PCI, был представлен в версии 2.2 спецификации PCI. Шина PCI также была адаптирована для стандарта внешних разъемов портативных компьютеров - CardBus. Первая спецификация PCI была разработана Intel, но последующая разработка стандарта стала ответственностью PCI Special Interest Group (PCI-SIG).
PCI и PCI-X иногда называют либо параллельным PCI, либо обычным PCI, чтобы технологически отличить их от их более позднего преемника PCI Express, который принял серийный, линейная архитектура. Расцвет PCI на рынке настольных компьютеров приходился примерно на 1995–2005 годы. PCI и PCI-X устарели для большинства целей; однако в 2020 году они все еще распространены на современных настольных компьютерах из-за обратной совместимости и низкой относительной стоимости производства. Другое распространенное современное применение параллельного PCI - это промышленные ПК, где многие используемые здесь специализированные карты расширения никогда не передаются на PCI Express, как и некоторые карты ISA. Многие типы устройств, ранее доступные на картах расширения PCI, теперь обычно интегрируются в материнские платы или доступны в версиях USB и PCI Express.
 Типичный 32-битный, 5 V-only PCI-карта, в данном случае адаптер SCSI от Adaptec
Типичный 32-битный, 5 V-only PCI-карта, в данном случае адаптер SCSI от Adaptec  Материнская плата с двумя 32-битными слотами PCI и двумя размерами слотов PCI Express
Материнская плата с двумя 32-битными слотами PCI и двумя размерами слотов PCI Express Работа на PCI началась в Лаборатории разработки архитектуры (IAL) Intel c. 1990. Команда, состоящая в основном из инженеров IAL, определила архитектуру и разработала доказательство концепции набора микросхем и платформы (Saturn) в партнерстве с командами компании, занимающимися системами настольных ПК, и организациями, производящими основные логические продукты.
PCI был немедленно использован в серверах, заменив MCA и EISA в качестве предпочтительной шины расширения сервера. В обычных ПК PCI медленнее заменял VESA Local Bus (VLB) и не добился значительного проникновения на рынок до конца 1994 года в ПК второго поколения Pentium. К 1996 году VLB практически исчез, и производители приняли PCI даже для 486 компьютеров. EISA продолжал использоваться вместе с PCI до 2000 года. Apple Computer внедрила PCI для профессиональных компьютеров Power Macintosh (заменив NuBus ) в середине 1995 года, а потребительские Performa (заменив LC PDS ) в середине 1996 года.
64-битная версия простого PCI на практике оставалась редкостью, хотя она использовалась, например, на всех (после iMac) G3 и G4 Power Macintosh компьютерах.
Более поздние версии PCI добавили новые функции и улучшения производительности, в том числе стандарт 66 МГц 3,3 V и 133 МГц PCI-X, а также адаптацию сигнализации PCI. к другим форм-факторам. И PCI-X 1.0b, и PCI-X 2.0 обратно совместимы с некоторыми стандартами PCI. Эти версии использовались в серверном оборудовании, но почти все оборудование потребительских ПК оставалось 32-битным, 33 МГц и 5 вольт.
PCI-SIG представила последовательный порт PCI Express в c. 2004. С тех пор производители материнских плат добавили все меньше разъемов PCI в пользу нового стандарта. По состоянию на конец 2013 года многие новые материнские платы вообще не имеют слотов PCI.
| Спецификация | Год | Сводка изменений |
|---|---|---|
| PCI 1.0 | 1992 | Исходный выпуск |
| PCI 2.0 | 1993 | Встроенный разъем и спецификация карты расширения |
| PCI 2.1 | 1995 | Включены пояснения и добавлены разделы о 66 МГц |
| PCI 2.2 | 1998 | Включены ECN и улучшена читаемость |
| PCI 2.3 | 2002 | Включены ECN, исправления и удаленные надстройки с ключом только на 5 В |
| PCI 3.0 | 2004 | Удалена поддержка системы с ключом 5.0 В разъем платы |
PCI предоставляет отдельную память и адресные пространства портов ввода / вывода для семейства процессоров x86, 64 и 32 бита соответственно. Адреса в этих адресных пространствах назначаются программным обеспечением. Третье адресное пространство, называемое PCI Configuration Space, которое использует фиксированную схему адресации, позволяет программному обеспечению определять объем памяти и адресное пространство ввода-вывода, необходимое каждому устройству. Каждое устройство может запрашивать до шести областей памяти или I / O порт пространства через свои регистры пространства конфигурации.
В типичной системе прошивка (или операционная система ) запрашивает все шины PCI во время запуска (через конфигурационное пространство PCI ), чтобы выяснить, какие устройства присутствуют и какие системные ресурсы (пространство памяти, пространство ввода-вывода, линии прерывания и т. д.) необходимы каждому. Затем он выделяет ресурсы и сообщает каждому устройству, каково их распределение.
Пространство конфигурации PCI также содержит небольшой объем информации о типе устройства, которая помогает операционной системе выбрать для него драйверы устройств или, по крайней мере, вести диалог с пользователем о конфигурации системы.
Устройства могут иметь встроенное ПЗУ, содержащее исполняемый код для процессоров x86 или PA-RISC, драйвер Open Firmware или EFI драйвер. Обычно они необходимы для устройств, используемых во время запуска системы, до того, как драйверы устройств будут загружены операционной системой.
Кроме того, существуют таймеры задержки PCI, которые являются механизмом для устройств PCI Bus-Mastering для справедливого совместного использования шины PCI. "Удовлетворительно" в этом случае означает, что устройства не будут использовать такую большую часть доступной полосы пропускания шины PCI, чтобы другие устройства не могли выполнять необходимую работу. Обратите внимание, это не относится к PCI Express.
Принцип работы заключается в том, что каждое устройство PCI, которое может работать в режиме ведущей шины, должно иметь таймер, называемый таймером задержки, который ограничивает время, в течение которого устройство может удерживать шину PCI. Таймер запускается, когда устройство становится владельцем шины, и ведет обратный отсчет с тактовой частотой PCI. Когда счетчик достигает нуля, устройству требуется освободить шину. Если другие устройства не ожидают владения шиной, оно может просто снова захватить шину и передать больше данных.
Устройства должны следовать протоколу, чтобы строки прерывания можно поделиться. Шина PCI включает четыре линии прерывания, каждая из которых доступна каждому устройству. Однако они не подключены параллельно, как другие линии шины PCI. Позиции линий прерывания меняются между слотами, поэтому то, что кажется одному устройству строкой INTA #, является INTB # для следующего и INTC # для следующего. Однофункциональные устройства используют свой INTA # для сигнализации прерывания, поэтому нагрузка на устройство распределяется довольно равномерно по четырем доступным линиям прерывания. Это устраняет общую проблему с разделением прерываний.
Отображение линий прерывания PCI на линии прерывания системы через мост хоста PCI зависит от реализации. Код BIOS, зависящий от платформы, должен знать это и устанавливать поле «прерывание» в пространстве конфигурации каждого устройства, указывающее, к какому IRQ оно подключено.
линии прерывания PCI запускаются по уровню. Это было выбрано по сравнению с запуском по фронту, чтобы получить преимущество при обслуживании линии прерываний общего пользования и для надежности: прерывания, запускаемые фронтом, легко пропустить.
В более поздних версиях спецификации PCI добавлена поддержка прерываний с сообщением. В этой системе устройство сигнализирует о своей потребности в обслуживании, выполняя запись в память, а не утверждая выделенную линию. Это снимает проблему нехватки линий прерывания. Даже если векторы прерываний по-прежнему используются совместно, он не страдает от проблем разделения прерываний, запускаемых по уровню. Это также решает проблему маршрутизации, потому что запись в память не изменяется непредсказуемо между устройством и хостом. Наконец, поскольку сигнализация сообщения - это внутриполосный, он решает некоторые проблемы синхронизации, которые могут возникнуть с опубликованными записями и внеполосными линиями прерывания.
PCI Express вообще не имеет линий физического прерывания. Он использует исключительно прерывания, сигнализируемые сообщениями.
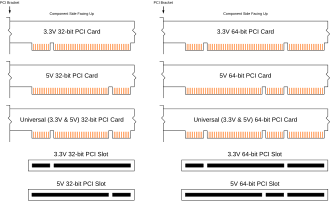 Диаграмма, показывающая различные позиции клавиш для 32-битных и 64-битных карт PCI
Диаграмма, показывающая различные позиции клавиш для 32-битных и 64-битных карт PCI Эти спецификации представляют собой наиболее распространенную версию PCI, используемую в обычных ПК:
Спецификация PCI также предоставляет опции для сигнализации 3,3 В, 64-битной шины и синхронизации 66 МГц, но они обычно не встречаются за пределами Поддержка PCI-X на материнских платах серверов.
Арбитр шины PCI выполняет арбитраж шины между несколькими мастерами на шине PCI. Любое количество мастеров шины может находиться на шины PCI, а также запросы на шину. Каждому мастеру шины выделена одна пара сигналов запроса и разрешения.
 Плата расширения PCI-X Gigabit Ethernet с выемками для 5 В и 3,3 В, сторона B в направлении камеры
Плата расширения PCI-X Gigabit Ethernet с выемками для 5 В и 3,3 В, сторона B в направлении камеры Типичные карты PCI имеют либо одна или две ключевые выемки, в зависимости от их сигнального напряжения. Карты, требующие 3,3 В, имеют выемку на расстоянии 56,21 мм от задней панели карты; Те, для которых требуется 5 В, имеют выемку на расстоянии 104,47 мм от задней панели. Это позволяет вставлять карты только в слоты с поддерживаемым ими напряжением. «Универсальные карты», принимающие любое напряжение, имеют оба ключевых паза.
Разъем PCI определяется как имеющий 62 контакта с каждой стороны краевого разъема, но два или четыре из них заменены ключевыми выемками, поэтому карта имеет 60 или 58 контактов с каждой стороны. Сторона A относится к «стороне припоя», а сторона B относится к «стороне компонента»: если карта удерживается коннектором вниз, на виде стороны A задняя панель будет справа, а на виде стороны B. будет иметь заднюю панель слева. Распиновка сторон B и A следующая, если смотреть вниз в разъем материнской платы (контакты A1 и B1 находятся ближе всего к задней панели).
| Контакт | Сторона B | Сторона A | Комментарии | ||
|---|---|---|---|---|---|
| 1 | -12 V | TRST # | JTAG выводы порта (необязательно) | ||
| 2 | TCK | +12 В | |||
| 3 | Заземление | TMS | |||
| 4 | TDO | TDI | |||
| 5 | +5 В | +5 В | |||
| 6 | +5 В | INTA # | Линии прерывания (открытый сток) | ||
| 7 | INTB# | INTC # | |||
| 8 | INTD# | +5 В | |||
| 9 | PRSNT1 # | Зарезервировано | Пониженный уровень означает, что требуется мощность 7,5 или 25 Вт | ||
| 10 | Зарезервировано | IOPWR | +5 В или +3,3 В | ||
| 11 | PRSNT2# | Зарезервировано | Пониженное напряжение для индикации требуемой мощности 7,5 или 15 Вт | ||
| 12 | Земля | Заземление | Ключевой вырез для плат с поддержкой 3.3 В | ||
| 13 | Заземление | Заземление | |||
| 14 | Зарезервировано | 3,3 В, доп. | Резервное питание (дополнительно) | ||
| 15 | Заземление | RST# | Сброс шины | ||
| 16 | CLK | IOPWR | Тактовая частота 33/66 МГц | ||
| 17 | Земля | GNT# | Разрешение шины от материнской платы к плате | ||
| 18 | REQ# | Ground | Запрос шины от карты к материнской плате | ||
| 19 | IOPWR | PME # | Событие управления питанием (опционально) 3,3 В, открытый сток, активный низкий уровень. | ||
| 20 | AD [31 ] | AD [30] | Шина адреса / данных (верхняя половина) | ||
| 21 | AD [29 ] | +3,3 В | |||
| 22 | Земля | н.э. [28] | |||
| 23 | AD [27 ] | н.э. [26] | |||
| 24 | н.э. [25] | Земля | |||
| 25 | +3,3 В | AD [24] | |||
| 26 | C/BE [3 ]# | IDSEL | |||
| 27 | AD [23 ] | +3,3 В | |||
| 28 | Земля | н.э. [22] | |||
| 29 | AD [21 ] | AD [20] | |||
| 30 | AD [19] impression | Земля | |||
| 31 | +3,3 V | н.э. [18] | |||
| 32 | AD [17 ] | AD [16] | |||
| 33 | C / BE [2 ] # | +3,3 В | |||
| 34 | Земля | FRAME# | Выполняется передача данных по шине | ||
| 35 | ИК DY # | Земля | Инициатор готов | ||
| 36 | +3,3 В | TRDY # | Цель готова | ||
| 37 | DEVSEL# | Земля | Выбрана цель | ||
| 38 | PCIXCAP | Земля | STOP # | PCI-X поддерживает; Остановка целевых запросов | |
| 39 | LOCK# | +3,3 V | Заблокированная транзакция | ||
| 40 | PERR# | SMBCLK | SDONE | Ошибка четности; SMBus синхронизация или отслеживание выполнено (устарело) | |
| 41 | +3,3 В | SMBDAT | SBO # | Данные SMBus или Snoop backoff (устаревший) | |
| 42 | SERR# | Ground | Системная ошибка | ||
| 43 | +3,3 В | PAR | Четность по AD [31:00] и C / BE [3: 0] # | ||
| 44 | C / BE [1] # | AD [15] | Адресная / информационная шина (верхняя половина) | ||
| 45 | AD [14 ] | +3,3 В | |||
| 46 | Земля | н.э. [13] | |||
| 47 | AD [12 ] | AD [11] | |||
| 48 | AD [10 ] | Земля | |||
| 49 | M66EN | Земля | AD [09] | ||
| 50 | Земля | Заземление | Ключевой вырез для 5 V-совместимых карт | ||
| 51 | Заземление | Заземление | |||
| 52 | AD [08] | C/BE[0pting# | Шина адреса / данных (нижняя половина) | ||
| 53 | AD [07 ] | +3,3 В | |||
| 54 | +3,3 V | AD [06] | |||
| 55 | AD[05 ] | AD [04] | |||
| 56 | AD [03 ] | Земля | |||
| 57 | Земля | AD [02] | |||
| 58 | AD [0 1] | AD [00] | |||
| 59 | IOPWR | IOPWR | |||
| 60 | ACK64# | REQ64 # | Для 64-битного расширения; нет подключения для 32-битных устройств. | ||
| 61 | +5 В | +5 В | |||
| 62 | +5 В | +5 В | |||
64-бит PCI расширяет это дополнительными 32 контактами на каждой стороне, которые обеспечивают AD [63:32], C / BE [7: 4] #, сигнал четности PAR64, а также ряд контактов питания и заземления.
| Вывод заземления | Беспотенциальный ссылка |
|---|---|
| Питание контактный | Подает питание на PCI-карты |
| Выходной контактный | Ведомый PCI карта, полученная материнской платой |
| Выход инициатора | Управляется мастером / инициатором, получен целевой |
| сигнал ввода / вывода | Может управляться инициатором или целью, в зависимости при операции |
| Целевой выход | Управляется целью, получено инициатором / мастером |
| Вход | Управляется материнской платой, получено картой PCI |
| Открытый сток | Может быть понижен и / или обнаружен несколькими картами |
| Зарезервировано | В настоящее время не используется, не подключается |
Большинство линий подключаются к каждому слоту параллельно. Исключения:
Примечания:
 Половставленная карта PCI-X в 32-битном слоте PCI, иллюстрирующая необходимость крайней правой выемки и дополнительного места на материнской плате, чтобы оставаться обратно совместимой
Половставленная карта PCI-X в 32-битном слоте PCI, иллюстрирующая необходимость крайней правой выемки и дополнительного места на материнской плате, чтобы оставаться обратно совместимой Большинство 32-битных карт PCI будут правильно работать в 64-битных слотах PCI-X, но тактовая частота шины будет ограничена тактовой частотой самой медленной карты, что является неотъемлемым ограничением общего доступа PCI. топология шины. Например, когда периферийное устройство PCI 2.3, 66 МГц, установлено в шину PCI-X, способную работать на частоте 133 МГц, вся объединительная плата шины будет ограничена до 66 МГц. Чтобы обойти это ограничение, многие материнские платы имеют две или более шины PCI / PCI-X, одна из которых предназначена для использования с высокоскоростными периферийными устройствами PCI-X, а другая шина предназначена для периферийных устройств общего назначения.
Многие 64-битные карты PCI-X разработаны для работы в 32-битном режиме при установке в более короткие 32-битные разъемы с некоторой потерей производительности. Примером этого является интерфейсная карта Adaptec 29160 64-bit SCSI. Однако некоторые 64-битные карты PCI-X не работают в стандартных 32-битных слотах PCI.
Установка 64-битной карты PCI-X в 32-битный слот оставит 64-битную часть крайний разъем карты не подключен и свисает. Для этого необходимо, чтобы компоненты материнской платы не располагались так, чтобы механически блокировать выступающую часть краевого разъема карты.
Высота кронштейнов PCI:
Длина карты PCI (стандартный кронштейн и 3,3 В):
Длина карты PCI (Низкопрофильная Кронштейн и 3,3 В):

Кронштейн во всю высоту.

Низкопрофильный.
 Mini PCI Wi-Fi карта типа IIIB
Mini PCI Wi-Fi карта типа IIIB  преобразователь PCI-to-MiniPCI тип III
преобразователь PCI-to-MiniPCI тип III  карты MiniPCI и MiniPCI Express в сравнении
карты MiniPCI и MiniPCI Express в сравнении Mini PCI был добавлен в PCI версии 2.2 для использования в ноутбуках ; он использует 32-битную шину 33 МГц с подключениями с питанием (только 3,3 В; 5 В ограничено до 100 мА) и поддерживает управление шиной и DMA. Стандартный размер карт Mini PCI составляет примерно четверть от их полноразмерных аналогов. Доступа к карте снаружи нет, в отличие от настольных PCI-карт с планками для крепления разъемов. Это ограничивает виды функций, которые может выполнять карта Mini PCI.
Было разработано множество устройств Mini PCI, таких как Wi-Fi, Fast Ethernet, Bluetooth, модемы (часто Winmodems ), звуковые карты, криптографические ускорители, SCSI, IDE - ATA, контроллеры SATA и комбинированные карты. Карты Mini PCI можно использовать с обычным оборудованием, оборудованным PCI, с помощью преобразователей Mini PCI-to-PCI. На смену Mini PCI пришла гораздо более узкая PCI Express Mini Card
Карты Mini PCI имеют максимальную потребляемую мощность 2 Вт, что ограничивает функциональность, которая может быть реализована в этот форм-фактор. Они также должны поддерживать сигнал CLKRUN # PCI, используемый для запуска и остановки тактовой частоты PCI в целях управления питанием.
Существует три форм-фактора карты : карты типа I, типа II и типа III. Разъемы для карт, используемые для каждого типа, включают: Тип I и II используют 100-контактный соединитель стекирования, тогда как Тип III использует 124-контактный краевой разъем, то есть разъем для Типов I и II отличается от разъема для Типа III, где разъем находится на краю карты, как в SO-DIMM. Дополнительные 24 контакта обеспечивают дополнительные сигналы, необходимые для маршрутизации ввода / вывода обратно через системный разъем (аудио, AC-Link, LAN, интерфейс телефонной линии). Карты типа II имеют разъемы RJ11 и RJ45. Эти карты должны быть расположены на краю компьютера или док-станции, чтобы порты RJ11 и RJ45 можно было установить для внешнего доступа.
| Тип | Карта на. внешнем крае. хост-системы | Разъем | Размер. (мм × мм × мм) | комментарии |
|---|---|---|---|---|
| IA | No | 100-контактный. штабелирование | 07,50 × 70,0 × 45,00 | Большой размер Z (7,5 мм) |
| IB | 05,50 × 70,0 × 45,00 | Меньший размер Z (5,5 мм) | ||
| IIA | Да | 17,44 × 70,0 × 45,00 | Большой размер Z (17,44 мм) | |
| IIB | 05,50 × 78,0 × 45,00 | Меньший размер Z (5,5 мм) | ||
| IIIA | No | 124-контактный. край карты | 02,40 × 59,6 × 50,95 | Большой размер Y (50,95 мм) |
| IIIB | 02,40 × 59,6 × 44,60 | Меньший размер Y (44,6 мм) |
Mini PCI отличается от 144-контактного Micro PCI.
Трафик шины PCI состоит из серии транзакций шины PCI. Каждая транзакция состоит из фазы адресации, за которой следует одна или несколько фаз данных. Направление фаз данных может быть от инициатора к цели (транзакция записи) или наоборот (транзакция чтения), но все фазы данных должны быть в одном направлении. Любая из сторон может в любой момент приостановить или остановить этапы обработки данных. (Одним из распространенных примеров является низкопроизводительное устройство PCI, которое не поддерживает пакетные транзакции и всегда останавливает транзакцию после первой фазы данных.)
Любое устройство PCI может инициировать транзакцию. Во-первых, он должен запросить разрешение у арбитра шины PCI на материнской плате. Арбитр предоставляет разрешение одному из запрашивающих устройств. Инициатор начинает фазу адресации с широковещательной рассылки 32-битного адреса плюс 4-битного кода команды, затем ожидает ответа от цели. Все остальные устройства проверяют этот адрес, и через несколько циклов одно из них отвечает.
64-битная адресация выполняется с использованием двухэтапной адресной фазы. Инициатор передает в широковещательном режиме 32 младших адресных бита в сопровождении специального командного кода "цикла двойного адреса". Устройства, не поддерживающие 64-битную адресацию, могут просто не отвечать на этот код команды. В следующем цикле инициатор передает старшие 32 адресных бита плюс реальный код команды. С этого момента транзакция работает идентично. Чтобы обеспечить совместимость с 32-битными устройствами PCI, запрещено использовать двойной адресный цикл, если это не необходимо, то есть если все биты адреса высокого порядка равны нулю.
Пока шина PCI передает 32 бита на фазу данных, инициатор передает 4 сигнала разрешения активного младшего байта, указывающих, какие 8-битные байты следует считать значимыми. В частности, запись должна затрагивать только разрешенные байты в целевом устройстве PCI. Они не имеют большого значения для чтения памяти, но чтение ввода-вывода может иметь побочные эффекты. Стандарт PCI явно разрешает фазу данных без включенных байтов, которая должна вести себя как бездействие.
PCI имеет три адресных пространства: память, адрес ввода-вывода и конфигурация.
Адреса памяти имеют размер 32 бита (необязательно 64 бита), поддерживают кэширование и могут быть пакетными транзакциями.
Адреса ввода-вывода предназначены для совместимости с адресным пространством портов ввода-вывода архитектуры Intel x86. Хотя спецификация шины PCI допускает пакетные транзакции в любом адресном пространстве, большинство устройств поддерживают ее только для адресов памяти, но не для ввода-вывода.
Наконец, конфигурационное пространство PCI обеспечивает доступ к 256 байтам специальных регистров конфигурации на каждое устройство PCI. Каждый слот PCI получает свой собственный диапазон адресов пространства конфигурации. Регистры используются для настройки памяти устройств и диапазонов адресов ввода-вывода, на которые они должны отвечать от инициаторов транзакций. При первом включении компьютера все устройства PCI реагируют только на доступ к их пространству конфигурации. BIOS компьютера сканирует устройства и назначает им диапазоны адресов памяти и ввода-вывода.
Если адрес не запрашивается каким-либо устройством, фаза адресации инициатора транзакции истекает по тайм-ауту, в результате чего инициатор прерывает операцию. В случае чтения обычно для считываемого значения данных (0xFFFFFFFF) обычно указываются все единицы. Поэтому устройства PCI обычно стараются избегать использования значения «все единицы» в важных регистрах состояния, чтобы такая ошибка могла быть легко обнаружена программным обеспечением.
Существует 16 возможных 4-битных кодов команд, 12 из которых назначены. За исключением уникального цикла двойного адреса, младший бит кода команды указывает, являются ли следующие фазы данных чтением (данные, отправленные от цели к инициатору) или записью (данные, отправленные от инициатора к цели). Цели PCI должны проверять код команды, а также адрес и не отвечать на этапы адресации, которые определяют неподдерживаемый код команды.
Команды, которые относятся к строкам кэша, зависят от правильной настройки регистра размера строки кэша PCI-конфигурационного пространства ; их нельзя использовать, пока это не будет сделано.
Вскоре после обнародования спецификации PCI было обнаружено, что длительные транзакции некоторых устройств из-за медленные подтверждения, длинные пакеты данных или их комбинация могут вызвать опустошение буфера или переполнение на других устройствах. Рекомендации по времени отдельных фаз в версии 2.0 стали обязательными в версии 2.1:
Кроме того, начиная с версии 2.1, все инициаторы, способные передавать более двух фаз данных, должны иметь программируемый таймер задержки. Таймер начинает отсчет тактовых циклов при запуске транзакции (инициатор устанавливает FRAME #). Если время таймера истекло и арбитр удалил GNT #, то инициатор должен завершить транзакцию при следующей законной возможности. Обычно это следующая фаза данных, но транзакции записи в память и недействительности должны продолжаться до конца строки кэша.
Устройства, которые не могут соответствовать этим временным ограничениям, должны использовать комбинацию опубликованных записей (для записи в память) и отложенных транзакций (для других операций записи и всех операций чтения). В отложенной транзакции цель записывает транзакцию (включая данные записи) внутренне и прерывает (устанавливает STOP #, а не TRDY #) первую фазу данных. Инициатор должен повторить ту же транзакцию позже. Тем временем цель внутренне выполняет транзакцию и ждет повторной транзакции. При обнаружении повторной транзакции доставляется буферизованный результат.
Устройство может быть целью других транзакций при выполнении одной отложенной транзакции; он должен запоминать тип транзакции, адрес, выбор байтов и (если запись) значение данных и выполнять только правильную транзакцию.
Если цель имеет ограничение на количество отложенных транзакций, которые она может записывать внутри (простые цели могут налагать ограничение на 1), она заставит эти транзакции повторить попытку без их записи. Они будут обработаны, когда текущая отложенная транзакция будет завершена. Если два инициатора пытаются выполнить одну и ту же транзакцию, отложенная транзакция, начатая одним, может иметь результат, доставленный другому; это безвредно.
Цель прекращает отложенную транзакцию, когда повторная попытка успешно доставила буферизованный результат, шина сбрасывается или когда 2 = 32768 тактовых циклов (приблизительно 1 мс) истекли, не увидев повторной попытки. Последнее никогда не должно происходить при нормальной работе, но оно предотвращает тупик всей шины, если один инициатор сброшен или неисправен.
Стандарт PCI позволяет соединять несколько независимых шин PCI с помощью шинных мостов, которые при необходимости перенаправляют операции на одной шине на другую. Хотя PCI обычно не использует много шинных мостов, системы PCI Express используют много; каждый слот PCI Express выглядит как отдельная шина, соединенная мостом с другими.
Обычно, когда шинный мост видит транзакцию на одной шине, которая должна быть перенаправлена на другую, исходная транзакция должна дождаться завершения перенаправленной транзакции, прежде чем будет готов результат. Одно примечательное исключение возникает в случае записи в память. Здесь мост может записывать данные записи внутренне (если в нем есть место) и сигнализировать о завершении записи до того, как завершится переадресация записи. Или даже до того, как это началось. Такие записи «отправлено, но еще не доставлено» называются «отправленными записями» по аналогии с почтовым сообщением. Несмотря на то, что они предлагают отличные возможности для повышения производительности, правила, определяющие, что допустимо, довольно запутаны.
Стандарт PCI позволяет шинным мостам преобразовывать несколько шинных транзакций в одну. более крупная сделка в определенных ситуациях. Это может повысить эффективность шины PCI.
Транзакции шины PCI управляются пятью основными управляющими сигналами, два из которых управляются инициатором транзакции (FRAME # и IRDY #), а три управляются целью (DEVSEL #, TRDY # и STOP #). Есть два дополнительных арбитражных сигнала (REQ # и GNT #), которые используются для получения разрешения на инициирование транзакции. Все они имеют активный низкий уровень, что означает, что активное или установленное состояние является низким напряжением. Подтягивающие резисторы на материнской плате гарантируют, что они будут оставаться высокими (неактивными или отключенными), если они не управляются каким-либо устройством, но шина PCI не зависит от резисторов для изменения уровня сигнала; все устройства устанавливают высокий уровень сигналов в течение одного цикла, прежде чем перестанет управлять сигналами.
Все сигналы шины PCI дискретизируются по нарастающему фронту тактовой частоты. Сигналы номинально изменяются на заднем фронте тактовой частоты, давая каждому устройству PCI примерно половину тактового цикла, чтобы решить, как реагировать на сигналы, наблюдаемые на переднем фронте, и половину тактового цикла для передачи своего ответа другому устройству..
Шина PCI требует, чтобы каждый раз при изменении устройства, управляющего сигналом шины PCI, между моментом, когда одно устройство прекращает передачу сигнала и запускается другое устройство, должен проходить один цикл обработки. Без этого мог бы быть период, когда оба устройства управляли сигналом, что могло бы помешать работе шины.
Комбинация этого оборотного цикла и требования установить высокий уровень на линии управления в течение одного цикла, прежде чем прекратить движение, означает, что каждая из основных линий управления должна иметь высокий уровень как минимум в течение двух циклов при смене владельцев. Протокол шины PCI разработан так, что это редко является ограничением; только в некоторых особых случаях (в частности, быстрые двусторонние транзакции) необходимо вставлять дополнительную задержку для удовлетворения этого требования.
Любое устройство на шине PCI, которое способно действовать как мастер шины, может инициировать транзакцию с любым другим устройством. Чтобы гарантировать, что одновременно инициируется только одна транзакция, каждый мастер должен сначала дождаться сигнала разрешения шины, GNT #, от арбитра, расположенного на материнской плате. Каждое устройство имеет отдельную строку запроса REQ #, которая запрашивает шину, но арбитр может «запарковать» сигнал разрешения шины на любом устройстве, если текущих запросов нет.
Арбитр может удалить GNT # в любое время. Устройство, которое теряет GNT #, может завершить свою текущую транзакцию, но не может начать ее (путем подтверждения FRAME #), если только оно не обнаружит, что GNT # подтвердил цикл до его начала.
Арбитр также может предоставить GNT # в любое время, в том числе во время транзакции другого мастера. Во время транзакции утверждается либо FRAME #, либо IRDY #, либо оба; когда оба сброшены, шина простаивает. Устройство может инициировать транзакцию в любой момент, когда заявлен GNT # и шина простаивает.
Транзакция шины PCI начинается с адресной фазы. Инициатор, видя, что у него есть GNT # и шина простаивает, вводит целевой адрес в строки AD [31: 0], а соответствующую команду (например, чтение памяти или запись ввода-вывода) на C / BE [3 : 0] # строк, и КАДР # сдвигается на низкий уровень.
Каждое другое устройство проверяет адрес и команду и решает, отвечать ли как цель, утверждая DEVSEL #. Устройство должно ответить, подтвердив DEVSEL # в течение 3 циклов. Устройства, которые обещают ответить в течение 1 или 2 циклов, называются «fast DEVSEL» или «medium DEVSEL» соответственно. (На самом деле время ответа составляет 2,5 цикла, поскольку устройства PCI должны передавать все сигналы на полцикла раньше, чтобы их можно было получить на три цикла позже.)
Обратите внимание, что устройство должно защелкнуться адрес по первому циклу; от инициатора требуется удалить адрес и команду с шины в следующем цикле, даже до получения ответа DEVSEL #. Дополнительное время доступно только для интерпретации адреса и команды после их захвата.
В пятом цикле адресной фазы (или раньше, если все другие устройства имеют средний DEVSEL или быстрее), для некоторых диапазонов адресов разрешено всеобъемлющее "вычитающее декодирование". Обычно это используется мостом шины ISA для адресов в пределах своего диапазона (24 бита для памяти и 16 бит для ввода / вывода).
В шестом цикле, если не было ответа, инициатор может прервать транзакцию, сняв FRAME #. Это известно как завершение прерывания ведущего, и в этом случае мосты шины PCI обычно возвращают данные «все единицы» (0xFFFFFFFF). Поэтому устройства PCI обычно проектируются так, чтобы избежать использования значения «все единицы» в важных регистрах состояния, чтобы такую ошибку можно было легко обнаружить с помощью программного обеспечения.
_ 0_ 1_ 2_ 3_ 4_ 5_ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / ___ GNT # \ ___ / XXXXXXXXXXXXXXXXXXX (GNT # Неактуально после начала цикла) _______ FRAME # \ ___________________ ___ AD [31: 0] ------- <___>--------------- (Действителен только адрес для одного цикла.) ___ _______________ C / BE [3: 0] # ------- <___X_______________ (Command, then first data phase byte enables) _______________________ DEVSEL# \___\___\___\___ Fast Med Slow Subtractive _ _ _ _ _ _ _ CLK _/ \_/ \_/ \_/ \_/ \_/ \_/ 0 1 2 3 4 5
По нарастающему фронту тактового сигнала 0 инициатор наблюдает одновременно высокий уровень FRAME # и IRDY # и низкий уровень GNT #, таким образом, он управляет адресом, командой и устанавливает номер КАДРА вовремя для нарастающего фронта тактового сигнала 1. Цели фиксируют адрес и начинают его декодирование. Они могут ответить DEVSEL # вовремя для часов 2 (быстрый DEVSEL), 3 (средний) или 4 (медленный). Устройства субтрактивного декодирования, не видя другого ответа по тактовому сигналу 4, могут ответить по тактовому сигналу 5. Если мастер не видит ответа по тактовому сигналу 5, он завершит транзакцию и удалит FRAME # по тактовому сигналу 6.
TRDY # и STOP # сбрасываются (высокий уровень) во время фазы адресации. Инициатор может заявить IRDY #, как только он будет готов к передаче данных, что теоретически может быть, как только часы 2.
Чтобы разрешить 64-битную адресацию, мастер будет представлять адрес в течение двух последовательных циклов. Во-первых, он отправляет биты адреса младшего разряда со специальной командой «адреса двойного цикла» на C / BE [3: 0] #. В следующем цикле он отправляет старшие биты адреса и фактическую команду. Двухадресные циклы запрещены, если старшие биты адреса равны нулю, поэтому устройства, не поддерживающие 64-битную адресацию, могут просто не реагировать на команды двойного цикла.
_ 0_ 1_ 2_ 3_ 4_ 5_ 6_ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / ___ GNT # \ ___ / XXXXXXXXXXXXXXXXXXXXXXXX _______ FRAME # \ _______________________ ___ ___ AD [31: 0] ------- <___X___>--------------- (младшие, затем старшие биты) ___ ___ _______________ C / BE [3: 0 ] # ------- <___X___X_______________ (DAC, then actual command) ___________________________ DEVSEL# \___\___\___\___ Fast Med Slow _ _ _ _ _ _ _ _ CLK _/ \_/ \_/ \_/ \_/ \_/ \_/ \_/ 0 1 2 3 4 5 6
Адреса для доступа к пространству конфигурации PCI декодируются специально. Для них строки адреса младшего разряда определяют смещение желаемого регистра конфигурации PCI, а строки адреса высокого порядка игнорируются. Вместо этого дополнительный адресный сигнал, вход IDSEL, должен иметь высокий уровень, прежде чем устройство сможет подтвердить DEVSEL #. Каждый слот подключает отдельную строку адреса высокого порядка к выводу IDSEL и выбирается с помощью кодирования one-hot в верхних адресных строках.
После фазы адресации (в частности, начиная с цикла, в котором DEVSEL # переходит на низкий уровень) идет пакет из одной или нескольких фаз данных. Во всех случаях инициатор передает сигналы выбора активного младшего байта в строках C / BE [3: 0] #, но данные в AD [31: 0] могут управляться инициатором (в случае записи) или цель (в случае чтения).
Во время фаз данных строки C / BE [3: 0] # интерпретируются как разрешения активного младшего байта. В случае записи заявленные сигналы указывают, какой из четырех байтов на шине AD должен быть записан в адресуемое место. В случае чтения они указывают, какие байты интересуют инициатора. Для чтения всегда допустимо игнорировать сигналы разрешения байтов и просто возвращать все 32 бита; ресурсы кэшируемой памяти должны всегда возвращать 32 действительных бита. Разрешенные байты в основном полезны для доступа к пространству ввода-вывода, когда чтение имеет побочные эффекты.
Фаза данных со всеми четырьмя деактивированными линиями C / BE # явно разрешена стандартом PCI и не должна оказывать никакого влияния на цель, кроме как на продвижение адреса в процессе пакетного доступа.
Фаза данных продолжается до тех пор, пока обе стороны не будут готовы завершить передачу и перейти к следующей фазе данных. Инициатор утверждает IRDY # (инициатор готов), когда ему больше не нужно ждать, в то время как цель утверждает TRDY # (цель готова). Независимо от того, какая сторона предоставляет данные, она должна передать их по шине AD до подачи сигнала готовности.
После того, как один из участников подтвердит свой сигнал готовности, он не может стать неготовым или иным образом изменить свои управляющие сигналы до конца фазы данных. Получатель данных должен защелкивать шину AD каждый цикл, пока не увидит, как утверждены как IRDY #, так и TRDY #, что отмечает конец текущей фазы данных и указывает, что только что защелкнутые данные являются словом для передачи.
Для поддержания полной пакетной скорости отправитель данных затем имеет половину тактового цикла после того, как видит как IRDY #, так и TRDY #, заявленные для передачи следующего слова на шину AD.
0_ 1_ 2_ 3_ 4_ 5_ 6_ 7_ 8_ 9_ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / ___ _______ ___ ___ ___ AD [31: 0] --- <___XXXXXXXXX_______XXXXX___X___X___ (If a write) ___ ___ _______ ___ ___ AD[31:0] ---<___>~~~Это продолжает цикл адресации, показанный выше, предполагая один цикл адреса со средним DEVSEL, поэтому цель отвечает вовремя для часов 3. Однако на этом время, ни одна из сторон не готова передавать данные. Для часов 4 инициатор готов, а цель - нет. На часах 5 оба готовы, и происходит передача данных (как показано вертикальными линиями). Для часов 6 цель готова к передаче, а инициатор - нет. На такте 7 инициатор становится готовым, и данные передаются. Для тактовых импульсов 8 и 9 обе стороны остаются готовыми к передаче данных, и данные передаются с максимально возможной скоростью (32 бита за такт).
В случае чтения, часы 2 зарезервированы для поворота шины AD, поэтому цели не разрешено передавать данные по шине, даже если она способна к быстрому DEVSEL.
Fast DEVSEL # при чтении
Цель, которая поддерживает быстрый DEVSEL, теоретически может начать отвечать на чтение цикла после того, как адрес представлен. Однако этот цикл зарезервирован для обслуживания шины AD. Таким образом, цель может не управлять шиной AD (и, следовательно, не может утверждать TRDY #) во втором цикле транзакции. Обратите внимание, что большинство целей не будут такими быстрыми и не нуждаются в специальной логике для выполнения этого условия.
Завершение транзакции
Любая сторона может запросить завершение пакета после текущей фазы данных. Простые устройства PCI, которые не поддерживают пакеты из нескольких слов, всегда запрашивают это немедленно. Даже устройства, которые поддерживают пакеты, будут иметь некоторое ограничение на максимальную длину, которую они могут поддерживать, например, конец их адресуемой памяти.
Завершение пакета инициатора
Инициатор может пометить любую фазу данных как последнюю в транзакции, сняв FRAME # одновременно с подтверждением IRDY #. Цикл после того, как цель устанавливает TRDY #, окончательная передача данных завершена, обе стороны отменяют свои соответствующие сигналы RDY #, и шина снова бездействует. Ведущее устройство не может деактивировать FRAME # до утверждения IRDY #, а также не может деактивировать FRAME # во время ожидания с подтвержденным IRDY #, чтобы цель утвердила TRDY #.
Единственное незначительное исключение - прерывание главного устройства, когда ни одна цель не отвечает DEVSEL #. Очевидно, ждать TRDY # в таком случае бессмысленно. Однако даже в этом случае мастер должен подтвердить IRDY # как минимум на один цикл после отмены FRAME #. (Обычно ведущее устройство устанавливает IRDY # перед получением DEVSEL #, поэтому он должен просто удерживать установленное значение IRDY # в течение одного цикла дольше.) Это необходимо для того, чтобы обеспечить соблюдение правил времени переключения шины в строке FRAME #.
Целевое завершение пакета
Целевое устройство запрашивает у инициатора завершение пакета, подтверждая STOP #. Затем инициатор завершит транзакцию, сняв FRAME # при следующей законной возможности; если он хочет передать больше данных, он будет продолжен отдельной транзакцией. У цели есть несколько способов сделать это:
- Отключиться с данными
- Если цель одновременно заявляет STOP # и TRDY #, это означает, что цель желает, чтобы это была последняя фаза данных.. Например, цель, которая не поддерживает пакетные передачи, всегда будет делать это, чтобы принудительно выполнить транзакции PCI, состоящие из одного слова. Это наиболее эффективный способ для цели завершить пакет.
- Отключение без данных
- Если цель заявляет STOP # без подтверждения TRDY #, это означает, что цель желает остановиться без передачи данные. STOP # считается эквивалентным TRDY # с целью завершения фазы данных, но данные не передаются.
- Retry
- Отключение без данных перед передачей любых данных является повторной попыткой, и в отличие от другие транзакции PCI, инициаторам PCI требуется небольшая пауза перед продолжением операции. Подробности см. В спецификации PCI.
- Target abort
- Обычно цель содержит DEVSEL #, заявленный на последней фазе данных. Однако, если цель отменяет DEVSEL # перед отключением без данных (подтверждение STOP #), это указывает на прерывание цели, что является условием фатальной ошибки. Инициатор не может повторить попытку и обычно рассматривает это как ошибку шины . Обратите внимание, что цель не может отменить DEVSEL # во время ожидания с TRDY # или STOP # low; он должен сделать это в начале фазы данных.
Всегда будет как минимум еще один цикл после отключения, инициированного целью, чтобы позволить мастеру отменить подтверждение FRAME #. Есть два подварианта, которые занимают одинаковое время, но один требует дополнительной фазы данных:
- Disconnect-A
- Если инициатор наблюдает STOP # перед тем, как подтвердить свой собственный IRDY #, то он может завершить пакет, сняв FRAME # одновременно с подтверждением IRDY #, завершив пакет после текущей фазы данных.
- Disconnect-B
- Если инициатор уже подтвердил IRDY # (без отмены FRAME #) к тому времени, когда он обнаруживает STOP # цели, он фиксируется на дополнительной фазе данных. Целевой объект должен дождаться дополнительной фазы данных, удерживая STOP #, заявленный без TRDY #, прежде чем транзакция может завершиться.
Если инициатор завершает пакет одновременно с целевым запросом отключения, дополнительного цикла шины нет.
Адресация пакетов
Для доступа к пространству памяти слова в пакете могут быть доступны в нескольких порядках. Ненужные младшие биты адреса AD [1: 0] используются для передачи запрошенного инициатором порядка. Цель, которая не поддерживает конкретный порядок, должна завершить пакет после первого слова. Некоторые из этих порядков зависят от размера строки кэша, который настраивается на всех устройствах PCI.
Порядок пакетов PCI A[1pting A[0pting Порядок пакетов (с 16-байтовой строкой кэша) 0 0 Линейное приращение (0x0C, 0x10, 0x14, 0x18, 0x1C,...) 0 1 Переключение строки кэша (0x0C, 0x08, 0x04, 0x00, 0x1C, 0x18,...) 1 0 Перенос кэша (0x0C, 0x00, 0x04, 0x08, 0x1C, 0x10,...) 1 1 Зарезервировано (отключение после первой передачи) Если начальное смещение в строке кэша равно нулю, все эти режимы сводятся к одному и тому же порядку.
Режимы переключения строки кэша и переноса строки кэша - это две формы выборки строки кэша первым критическим словом. Режим переключения выполняет операцию XOR для указанного адреса с увеличивающимся счетчиком. Это родной порядок для процессоров Intel 486 и Pentium. Его преимущество состоит в том, что для его реализации не требуется знать размер строки кэша.
PCI версии 2.1 исключил режим переключения и добавил режим переноса строки кэша, при котором выборка выполняется линейно, с переносом в конце каждой строки кэша. Когда одна строка кеша полностью выбрана, выборка переходит к начальному смещению в следующей строке кеша.
Обратите внимание, что большинство устройств PCI поддерживают только ограниченный диапазон типичных размеров строк кэша; если размер строки кэша запрограммирован на неожиданное значение, они принудительно обращаются к одному слову.
PCI также поддерживает пакетный доступ к вводу-выводу и пространству конфигурации, но поддерживается только линейный режим. (Это редко используется и может содержать ошибки на некоторых устройствах; они могут не поддерживать его, но также не обеспечивают принудительный доступ по одному слову.)
Примеры транзакций
Это самый высокий- возможная скорость, пакетная запись из четырех слов, завершаемая мастером:
0_ 1_ 2_ 3_ 4_ 5_ 6_ 7_ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ ___ ___ ___ ___ ___ AD [31: 0] --- <___X___X___X___X___>--- <___>___ ___ ___ ___ ___ C / BE [3: 0] # --- <___X___X___X___X___>--- <___>| | | | ___ IRDY # ^^^^^^^^ \ ______________ / ^^^^^ | | | | ___ TRDY # ^^^^^^^^ \ ______________ / ^^^^^ | | | | ___ DEVSEL # ^^^^^^^^ \ ______________ / ^^^^^ ___ | | | ___ КАДР № \ _______________ / | ^^^^ \ ____ _ _ | _ | _ | _ | _ _ _ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ 0 1 2 3 4 5 6 7На фронте 1 тактового сигнала инициатор запускает транзакцию, управляя адресом, командой и утверждая FRAME #. Остальные сигналы неактивны (обозначены ^^^), подтягиваются подтягивающими резисторами материнской платы.. Это может быть их цикл восстановления. В цикле 2 цель утверждает как DEVSEL #, так и TRDY #. Поскольку инициатор также готов, происходит передача данных. Это повторяется еще три цикла, но перед последним (тактовый фронт 5) мастер отменяет FRAME #, указывая, что это конец. На фронте 6 тактового сигнала шина AD и FRAME # не задействованы (цикл обработки), а другие линии управления находятся в состоянии высокого уровня в течение 1 цикла. На фронте тактового сигнала 7 другой инициатор может начать другую транзакцию. Это также цикл оборота для других линий управления.
Эквивалентный пакет чтения занимает еще один цикл, потому что цель должна ждать 1 цикл, пока шина AD не развернется, прежде чем она сможет подтвердить TRDY #:
0_ 1_ 2_ 3_ 4_ 5_ 6_ 7_ 8_ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ ___ ___ ___ ___ ___ AD [31: 0] --- <___>--- <___X___X___X___>--- <___>___ _______ ___ ___ ___ C / BE [3: 0] # --- <___X_______X___X___X___>--- <___>___ | | | | ___ IRDY # ^^^^ \ ___________________ / ^^^^^ ___ _____ | | | | ___ TRDY # ^^^^ \ ______________ / ^^^^^ ___ | | | | ___ DEVSEL # ^^^^ \ ___________________ / ^^^^^ ___ | | | ___ КАДР № \ ___________________ / | ^^^^ \ ____ _ _ _ | _ | _ | _ | _ _ _ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ 0 1 2 3 4 5 6 7 8Высокоскоростной пакет, завершенный целью, будет иметь дополнительный цикл в конце:
0_ 1_ 2_ 3_ 4_ 5_ 6_ 7_ 8_ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ ___ ___ ___ ___ ___ AD [31: 0] --- <___>--- <___X___X___X___XXXX>---- ___ _______ ___ ___ ___ ___ C / BE [3: 0] # --- <___X_______X___X___X___X___>---- | | | | ___ IRDY # ^^^^^^^ \ _______________________ / _____ | | | | _______ TRDY # ^^^^^^^ \ ______________ / ________________ | ___ STOP # ^^^^^^^ | | | \ _______ / | | | | ___ DEVSEL # ^^^^^^^ \ _______________________ / ___ | | | | ___ КАДР # \ _______________________ / ^^^^ _ _ _ | _ | _ | _ | _ _ _ CLK _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ _ / \ 0 1 2 3 4 5 6 7 8На фронте 6 тактового сигнала цель указывает, что она хочет остановиться (с данными), но инициатор уже удерживает IRDY # на низком уровне, поэтому есть пятые данные фаза (фронт часов 7), в течение которой данные не передаются.
Четность
Шина PCI обнаруживает ошибки четности, но не пытается исправить их, повторяя операции; это чисто индикация отказа. Благодаря этому нет необходимости обнаруживать ошибку четности до того, как она произошла, и шина PCI фактически обнаруживает ее несколькими циклами позже. Во время фазы данных, какое бы устройство ни управляло линиями AD [31: 0], вычисляет четность по ним и линиям C / BE [3: 0] # и отправляет это в линию PAR на один цикл позже. Все правила доступа и циклы обработки для шины AD применяются к линии PAR всего на один цикл позже. Устройство, прослушивающее шину AD, проверяет полученную четность и через один цикл после этого выдает строку PERR # (ошибка четности). Обычно это вызывает прерывание процессора, и процессор может искать на шине PCI устройство, обнаружившее ошибку.
Строка PERR # используется только во время фаз данных, когда цель была выбрана. Если ошибка четности обнаружена во время фазы адресации (или фазы данных специального цикла), устройства, которые ее наблюдают, подтверждают строку SERR # (системная ошибка).
Даже когда некоторые байты маскируются строками C / BE # и не используются, они все равно должны иметь определенное значение, и это значение должно использоваться для вычисления четности.
Быстрые двусторонние транзакции
Из-за необходимости цикла переключения между различными устройствами, управляющими сигналами шины PCI, в общем случае необходимо иметь цикл простоя между транзакциями шины PCI. Однако в некоторых случаях разрешается пропускать этот цикл ожидания, переходя непосредственно от последнего цикла одной передачи (IRDY # подтвержден, FRAME # отменен) к первому циклу следующего (FRAME # подтвержден, IRDY # отменен).
Инициатор может выполнять параллельные транзакции только в том случае, если:
- они выполняются одним и тем же инициатором (или не было бы времени перевернуть строки C / BE # и FRAME #),
- первая транзакция была записью (поэтому нет необходимости переключать шину AD), и
- инициатор все еще имеет разрешение (из своего входа GNT #) на использование шины PCI.
Дополнительные временные ограничения могут возникать из-за необходимости развернуть целевые линии управления, особенно DEVSEL #. Целевой объект сбрасывает DEVSEL #, переводя его в высокий уровень, в цикле, следующем за последней фазой данных, которая в случае параллельных транзакций является первым циклом фазы адресации. Затем второй цикл фазы адреса зарезервирован для выполнения DEVSEL #, поэтому, если цель отличается от предыдущей, она не должна утверждать DEVSEL # до третьего цикла (средняя скорость DEVSEL).
Одним из случаев, когда эта проблема не может возникнуть, является то, что инициатор каким-то образом знает (предположительно из-за того, что адреса разделяют достаточное количество старших битов), что вторая передача адресована той же цели, что и предыдущая. В этом случае он может выполнять обратные транзакции. Все цели PCI должны поддерживать это.
Также возможно, что цель отслеживает требования. Если он никогда не делает быстрого DEVSEL, они встречаются тривиально. Если это так, он должен дождаться среднего времени DEVSEL, если:
- текущей транзакции не предшествовал цикл простоя (не является последовательным), или
- предыдущая транзакция была к той же цели, или
- текущая транзакция началась с двойного адресного цикла.
Цели, у которых есть эта возможность, указывают ее специальным битом в регистре конфигурации PCI, и, если она есть у всех целей на шине, все инициаторы может свободно использовать обратные переводы.
Мост шины субтрактивного декодирования должен знать, что следует ожидать эту дополнительную задержку в случае последовательных циклов, чтобы объявить о поддержке.
64-битный PCI
Начиная с версии 2.1, спецификация PCI включает дополнительную поддержку 64-битного. Это обеспечивается через расширенный разъем, который обеспечивает 64-битные расширения шины AD [63:32], C / BE [7: 4] # и PAR64, а также ряд дополнительных контактов питания и заземления. 64-разрядный разъем PCI можно отличить от 32-разрядного разъема по дополнительному 64-разрядному сегменту.
При транзакциях с памятью между 64-битными устройствами могут использоваться все 64 бита для удвоения скорости передачи данных. Транзакции, не связанные с памятью (включая доступ к конфигурации и пространству ввода-вывода), не могут использовать 64-разрядное расширение. Во время 64-битного пакета адресация пакета работает так же, как и при 32-битной передаче, но адрес увеличивается дважды за фазу данных. Начальный адрес должен быть выровнен по 64 бита; т.е. AD2 должен быть 0. Данные, соответствующие промежуточным адресам (с AD2 = 1), передаются по верхней половине шины AD.
Чтобы инициировать 64-битную транзакцию, инициатор устанавливает начальный адрес на шине AD и устанавливает REQ64 # одновременно с FRAME #. Если выбранная цель может поддерживать 64-битную передачу для этой транзакции, она отвечает, подтверждая ACK64 # одновременно с DEVSEL #. Обратите внимание, что цель может решить для каждой транзакции, разрешить ли 64-битную передачу.
Если REQ64 # заявлено во время фазы адресации, инициатор также передает старшие 32 бита адреса и копию команды шины на старшую половину шины. Если для адреса требуется 64 бита, по-прежнему требуется цикл двойного адреса, но старшая половина шины несет верхнюю половину адреса и окончательный код команды в течение обоих циклов фазы адреса; это позволяет 64-битной цели видеть весь адрес и раньше начать отвечать.
Если инициатор видит, что DEVSEL # заявлено без ACK64 #, он выполняет 32-битные фазы данных. Данные, которые были бы переданы по верхней половине шины во время первой фазы данных, вместо этого передаются во время второй фазы данных. Обычно инициатор запускает все 64 бита данных до того, как увидит DEVSEL #. Если ACK64 # отсутствует, он может перестать управлять верхней половиной шины данных.
Строки REQ64 # и ACK64 # удерживаются утвержденными для всей транзакции, за исключением последней фазы данных, и отменяются одновременно с FRAME # и DEVSEL #, соответственно.
Линия PAR64 работает так же, как линия PAR, но обеспечивает четность по AD [63:32] и C / BE [7: 4] #. Это действительно только для адресных фаз, если заявлено REQ64 #. PAR64 действителен только для фаз данных, если заявлены как REQ64 #, так и ACK64 #.
Отслеживание кэша (устарело)
Изначально PCI включала дополнительную поддержку write-back согласованности кеша. Для этого требовалась поддержка целевыми объектами кэшируемой памяти, которые будут прослушивать два вывода из кеша на шине, SDONE (отслеживание завершено) и SBO # (задержка отслеживания).
Поскольку это редко реализовывалось на практике, это было удален из версии 2.2 спецификации PCI, а контакты повторно используются для доступа SMBus в версии 2.3.
Кэш будет отслеживать все обращения к памяти без подтверждения DEVSEL #. Если бы он заметил доступ, который мог быть кэширован, он снизил бы уровень SDONE (отслеживание не выполнено). Цель, поддерживающая согласованность, избежала бы завершения фазы данных (утверждения TRDY #) до тех пор, пока не обнаружит высокий уровень SDONE.
В случае записи в данные, которые были чистыми в кэше, кэш должен был бы только аннулировать свою копию и утверждать SDONE, как только это будет установлено. Однако, если кеш содержал грязные данные, кеш должен был бы записать их обратно, прежде чем доступ может продолжиться. поэтому он будет утверждать SBO # при поднятии SDONE. Это будет сигнализировать активной цели об утверждении STOP #, а не TRDY #, в результате чего инициатор отключится и попытается повторить операцию позже. Тем временем кеш будет выполнять арбитраж для шины и записывать свои данные обратно в память.
Целевые объекты, поддерживающие когерентность кэша, также должны завершать пакеты до того, как они пересекут строки кэша.
Инструменты разработкиПлата PCI, которая отображает номера POST во время запуска BIOS.
При разработке и / или устранении неисправностей шины PCI очень важно изучить сигналы оборудования. Логические анализаторы и анализаторы шины - это инструменты, которые собирают, анализируют и декодируют сигналы, чтобы пользователи могли их использовать.
См. Также
- Конфигурационное пространство PCI
- CompactPCI, PCI-X, PCI Express
- PCI-SIG, особый интерес PCI Группа
- PICMG, Группа производителей промышленных компьютеров PCI
- Еврокарта (печатная плата)
СсылкиДополнительная литература
- Официальные технические спецификации
- PCI-SIG (29 марта, 2002). Спецификация локальной шины PCI: версия 2.3.(1000 долларов для лиц, не являющихся членами, или 50 долларов для участников. Членство в PCI-SIG составляет 3000 долларов в год).
- PCI-SIG (12 августа 2002 г.). Спецификация локальной шины PCI: версия 3.0.(1000 долларов США для лиц, не являющихся участниками, или 50 долларов США для участников. Членство в PCI-SIG составляет 3000 долларов США в год). 2-е изд; Дуг Эбботт; 250 страниц; 2004; ISBN 978-0-7506-7739-4.
- Архитектура системы PCI; 4-е изд; Том Шенли; 832 страницы; 1999; ISBN 978-0-201-30974-4.
- Архитектура системы PCI-X; 1-е изд; Том Шенли; 752 страницы; 2000; ISBN 978-0-201-72682-4.
- Архитектура и дизайн аппаратного и программного обеспечения PCI и PCI-X; 5-е изд; Эд Солари; 1140 страниц; 2001; ISBN 978-0-929392-63-9.
- Применение и конструкция PCI HotPlug; 1-е изд; Алан Гудрам; 162 страницы; 1998; ISBN 978-0-929392-60-8.
Внешний l inks
Викискладе есть носители, связанные с PCI и Mini PCI.
- Official
- Официальный сайт, PCI Special Interest Group (PCI-SIG)
- Технические детали
- Введение в протокол PCI, electrofriends.com
- Распиновка и сигналы шины PCI, pinouts.ru
- Размеры карты PCI, interfacebus.com
- Списки поставщиков / устройств / идентификаторов
- Списки поставщиков и устройств PCI, pcidatabase.com
- Репозиторий идентификаторов PCI, проект по сбору всех известных идентификаторов
- Советы
- Краткий обзор PCI требования к питанию и совместимость с красивой диаграммой
- Хорошие диаграммы и текст о том, как распознать разницу между гнездами на 5 и 3,3 В
- Linux
- Linux с картами miniPCI
- Страница проверки драйверов устройств PCI GNU / Linux
- Декодирование данных PCI и вывод lspci на хостах Linux
- Инструменты разработки
- Активный удлинитель шины PCI, dinigroup.com
- Ядра ПЛИС
- Ядро интерфейса PCI, Lattice Semiconductor
- Ядро моста PCI, OpenCore.
- Поиск IP для PCI Bu s Ядра, Berkeley.
 Плата PCI, которая отображает номера
Плата PCI, которая отображает номера