
Войти
 На этом изображении показан пример прогнозирования рейтинга пользователя с использованием совместной фильтрации. Сначала люди оценивают разные предметы (например, видео, изображения, игры). После этого система делает прогнозов о рейтинге пользователя для элемента, который пользователь еще не оценил. Эти прогнозы основаны на существующих рейтингах других пользователей, которые имеют аналогичные оценки с активным пользователем. Например, в нашем случае система сделала прогноз, что активному пользователю видео не понравится.
На этом изображении показан пример прогнозирования рейтинга пользователя с использованием совместной фильтрации. Сначала люди оценивают разные предметы (например, видео, изображения, игры). После этого система делает прогнозов о рейтинге пользователя для элемента, который пользователь еще не оценил. Эти прогнозы основаны на существующих рейтингах других пользователей, которые имеют аналогичные оценки с активным пользователем. Например, в нашем случае система сделала прогноз, что активному пользователю видео не понравится. Совместная фильтрация (CF) - это метод, используемый рекомендательными системами. У совместной фильтрации есть два смысла: узкое и более общее.
В более новом, более узком смысле совместная фильтрация - это метод автоматического прогнозов (фильтрация) в отношении интересов пользователь путем сбора предпочтений или вкуса информации от многих пользователей (сотрудничающих). Основное предположение подхода совместной фильтрации заключается в том, что если человек A придерживается того же мнения, что и человек B по вопросу, A с большей вероятностью будет иметь мнение B по другому вопросу, чем мнение случайно выбранного человека. Например, система рекомендаций с совместной фильтрацией для вкусов телевидения может делать прогнозы о том, какое телешоу должно понравиться пользователю, с учетом частичного списка вкусов этого пользователя (симпатий или антипатий). Обратите внимание, что эти прогнозы относятся к конкретному пользователю, но используют информацию, полученную от многих пользователей. Это отличается от более простого подхода, при котором средний (неспецифический) балл для каждого интересующего элемента, например, на основании его количества голосов.
В более общем смысле, совместная фильтрация представляет собой процесс фильтрации информации или шаблонов с использованием методов, предполагающих сотрудничество между несколькими агентами, точками зрения, источниками данных и т. д. Приложения совместной фильтрации обычно включают очень большие наборы данных. Методы совместной фильтрации применялись ко многим различным типам данных, включая: данные зондирования и мониторинга, такие как разведка полезных ископаемых, зондирование окружающей среды на больших площадях или множественные датчики; финансовые данные, такие как финансовые учреждения, которые объединяют множество финансовых источников; или в электронной коммерции и веб-приложениях, где основное внимание уделяется пользовательским данным и т. д. Остальная часть этого обсуждения посвящена совместной фильтрации для пользовательских данных, хотя некоторые методы и подходы могут применяться также и к другим основным приложениям.
The Рост Интернета значительно затруднил эффективное извлечение полезной информации из всего доступного. Подавляющее количество данных требует механизмов для эффективной фильтрации информации. Совместная фильтрация - один из методов, используемых для решения этой проблемы.
Мотивация к совместной фильтрации исходит из того, что люди часто получают лучшие рекомендации от кого-то с похожими вкусами. Совместная фильтрация включает в себя методы сопоставления людей со схожими интересами и выработки рекомендаций на этой основе.
Алгоритмы совместной фильтрации часто требуют (1) активного участия пользователей, (2) простого способа представления интересов пользователей и (3) алгоритмов, которые могут сопоставить людей со схожими интересами.
Обычно рабочий процесс системы совместной фильтрации:
Ключевой проблемой совместной фильтрации является как объединить и взвесить предпочтения соседей пользователей. Иногда пользователи могут сразу оценить рекомендуемые товары. В результате система получает все более точное представление о предпочтениях пользователя с течением времени.
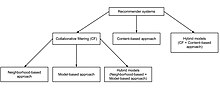 Совместная фильтрация в рекомендательных системах
Совместная фильтрация в рекомендательных системах Совместные системы фильтрации имеют множество форм, но многие общие системы можно сократить до двух этапов:
Это подпадает под категорию пользователей- совместная фильтрация на основе. Конкретным применением этого является ориентированный на пользователя алгоритм ближайшего соседа.
В качестве альтернативы, совместная фильтрация на основе элементов (пользователи, купившие x, также купили y), выполняется по элементам:
См., Например, Наклон Одно семейство совместной фильтрации на основе элементов.
Другая форма совместной фильтрации может быть основана на неявных наблюдениях за нормальным поведением пользователя (в отличие от искусственного поведения, навязанного оценочной задачей). Эти системы наблюдают за тем, что сделал пользователь, вместе с тем, что сделали все пользователи (какую музыку они слушали, какие предметы купили), и используют эти данные для прогнозирования поведения пользователя в будущем или для прогнозирования того, что пользователю может понравиться. вести себя при наличии возможности. Затем эти прогнозы необходимо отфильтровать с помощью бизнес-логики, чтобы определить, как они могут повлиять на действия бизнес-системы. Например, бесполезно предлагать кому-то продать определенный альбом музыки, если он уже продемонстрировал, что он владеет этой музыкой.
Использование системы оценок или оценок, усредненных для всех пользователей, игнорирует конкретные требования пользователя и особенно плохо справляется с задачами, в которых наблюдается большой разброс интересов (например, в рекомендациях по музыке). Однако существуют и другие методы борьбы с информационным взрывом, такие как веб поиск и кластеризация данных.
на основе памяти Этот подход использует данные рейтинга пользователей для вычисления сходства между пользователями или элементами. Типичными примерами этого подхода являются CF на основе соседства и рекомендации Top-N на основе элементов / пользователей. Например, в подходах, основанных на пользователях, значение оценок, которые пользователь u дает элементу i, вычисляется как совокупность некоторых аналогичных пользовательских оценок элемента:

где U обозначает набор верхних N пользователи, которые больше всего похожи на пользователя u, который оценил элемент i. Некоторые примеры функции агрегирования включают:


где k - нормализующий коэффициент, определяемый как 

где 
Алгоритм на основе соседства вычисляет сходство между двумя пользователями или элементами и производит прогноз для пользователя, беря средневзвешенное значение всех оценок. Вычисление сходства между элементами или пользователями - важная часть этого подхода. Для этого используются множественные меры, такие как корреляция Пирсона и сходство на основе векторного косинуса.
Корреляционное сходство Пирсона двух пользователей x, y определяется как

где I xy - это набор элементов, оцененных как пользователем x, так и пользователем y.
Подход на основе косинусов определяет косинус-подобие между двумя пользователями x и y как:

Алгоритм рекомендаций по топ-N на основе пользователей использует основанную на сходстве векторную модель для определения k пользователей, наиболее похожих на активного пользователя. После того, как k наиболее похожих пользователей найдены, соответствующие им матрицы элементов-пользователей агрегируются для определения набора элементов, которые следует рекомендовать. Популярным методом поиска похожих пользователей является хеширование с учетом местоположения, которое реализует механизм ближайшего соседа в линейное время.
Преимущества этого подхода включают: объяснимость результатов, что является важным аспектом систем рекомендаций; простота создания и использования; легкое внесение новых данных; независимость от содержания рекомендуемых элементов; хорошее масштабирование с предметами с одинаковым рейтингом.
Такой подход также имеет несколько недостатков. Его производительность снижается, когда данные становятся разреженными, что часто случается с элементами, связанными с Интернетом. Это препятствует масштабируемости этого подхода и создает проблемы с большими наборами данных. Хотя он может эффективно обрабатывать новых пользователей, поскольку он полагается на структуру данных , добавление новых элементов становится более сложным, поскольку это представление обычно основывается на конкретном векторном пространстве . Добавление новых элементов требует включения нового элемента и повторной вставки всех элементов в структуру.
В этом подходе модели разрабатываются с использованием различных алгоритмов интеллектуального анализа данных, машинного обучения для прогнозирования оценок пользователей безрейтинговых элементов.. Существует множество алгоритмов CF на основе моделей. Байесовские сети, модели кластеризации, латентно-семантические модели, такие как разложение по сингулярным значениям, вероятностный латентно-семантический анализ, множественный мультипликативный коэффициент, скрытое распределение Дирихле и модели на основе марковского процесса принятия решений.
Благодаря этому подходу методы уменьшения размерности в основном используются в качестве дополнительная техника для повышения надежности и точности подхода, основанного на памяти. В этом смысле такие методы, как разложение по сингулярным значениям, анализ главных компонентов, известные как модели скрытых факторов, сжимают матрицу элементов пользователя в низкоразмерное представление в терминах скрытых факторов. Одним из преимуществ использования этого подхода является то, что вместо того, чтобы иметь матрицу большой размерности, содержащую большое количество пропущенных значений, мы будем иметь дело с гораздо меньшей матрицей в пространстве меньшей размерности. Сокращенное представление можно использовать для алгоритмов соседства на основе пользователей или элементов, которые представлены в предыдущем разделе. У этой парадигмы есть несколько преимуществ. Он обрабатывает разреженность исходной матрицы лучше, чем матрицы на основе памяти. Кроме того, сравнение сходства в результирующей матрице гораздо более масштабируемо, особенно при работе с большими разреженными наборами данных.
Ряд приложений объединяют алгоритмы CF на основе памяти и на основе моделей. Они преодолевают ограничения собственных подходов CF и улучшают производительность прогнозирования. Важно отметить, что они преодолевают такие проблемы CF, как разреженность и потеря информации. Однако они имеют повышенную сложность и дороги в реализации. Обычно большинство коммерческих рекомендательных систем являются гибридными, например, рекомендательная система новостей Google.
В последние годы был предложен ряд методов нейронного и глубокого обучения. Некоторые обобщают традиционные алгоритмы матричной факторизации с помощью нелинейной нейронной архитектуры или используют новые типы моделей, такие как Variational Autoencoders. Хотя глубокое обучение применялось ко многим различным сценариям: с учетом контекста, с учетом последовательности, социальных тегов и т. Д., Его реальная эффективность при использовании в простом сценарии совместной рекомендации была поставлена под сомнение. Систематический анализ публикаций, применяющих глубокое обучение или нейронные методы для решения топ-k проблем рекомендаций, опубликованных на ведущих конференциях (SIGIR, KDD, WWW, RecSys), показал, что в среднем менее 40% статей воспроизводимы при минимальном как 14% на некоторых конференциях. В целом исследование выявило 18 статей, только 7 из них могли быть воспроизведены, а 6 из них могли быть лучше, чем гораздо более старые и более простые, правильно настроенные исходные данные. В статье также освещается ряд потенциальных проблем в современной исследовательской науке и содержится призыв к совершенствованию научной практики в этой области. Подобные проблемы были обнаружены также в рекомендательных системах с учетом последовательности.
Многие рекомендательные системы просто игнорируют другую контекстную информацию, существующую вместе с рейтингом пользователя, при предоставлении рекомендации элемента. Однако из-за повсеместной доступности контекстной информации, такой как время, местоположение, социальная информация и тип устройства, которое использует пользователь, для успешной рекомендательной системы становится как никогда важно предоставлять контекстно-зависимые рекомендации. По словам Чару Аггравала, «контекстно-зависимые рекомендательные системы адаптируют свои рекомендации к дополнительной информации, которая определяет конкретную ситуацию, при которой рекомендации делаются. Эта дополнительная информация упоминается как контекст».
Учет контекстной информации, у нас будет дополнительное измерение к существующей матрице рейтингов пользовательских элементов. Например, предположим, что система музыкальных рекомендаций дает разные рекомендации в зависимости от времени суток. В этом случае у пользователя могут быть разные предпочтения в отношении музыки в разное время суток. Таким образом, вместо использования матрицы пользовательских элементов мы можем использовать тензор порядка 3 (или выше для рассмотрения других контекстов) для представления контекстно-зависимых предпочтений пользователей.
Чтобы взять Преимущество совместной фильтрации и, в частности, методов на основе соседства, подходы могут быть расширены от двумерной рейтинговой матрицы до тензора более высокого порядка. Для этого нужно найти пользователей, наиболее похожих / единомышленников на целевого пользователя; можно извлечь и вычислить подобие срезов (например, матрицу элемент-время), соответствующих каждому пользователю. В отличие от контекстно-нечувствительного случая, для которого вычисляется сходство двух векторов оценок, в подходах с учетом контекста сходство матриц оценок, соответствующих каждому пользователю, вычисляется с использованием коэффициентов Пирсона. После того, как будут найдены наиболее единомышленники, их соответствующие рейтинги суммируются для определения набора элементов, которые следует рекомендовать целевому пользователю.
Самым важным недостатком включения контекста в модель рекомендаций является возможность работать с большим набором данных, который содержит гораздо больше пропущенных значений по сравнению с матрицей рейтинга пользовательских элементов. Следовательно, аналогично методам матричной факторизации, методы могут использоваться для уменьшения размерности исходных данных перед использованием каких-либо методов на основе соседства.
В отличие от традиционной модели массовых СМИ, в которой несколько редакторов устанавливают правила, в социальных сетях с совместной фильтрацией может быть очень большое количество редакторов, а контент улучшается. по мере увеличения количества участников. Такие сервисы, как Reddit, YouTube и Last.fm, являются типичными примерами мультимедиа на основе совместной фильтрации.
Один из сценариев приложения совместной фильтрации: рекомендовать интересную или популярную информацию по мнению сообщества. Как типичный пример, истории появляются на первой странице Reddit, поскольку они «проголосовали» (получили положительную оценку) сообществом. По мере того как сообщество становится больше и разнообразнее, продвигаемые истории могут лучше отражать средний интерес членов сообщества.
Другим аспектом систем совместной фильтрации является возможность генерировать более персонализированные рекомендации путем анализа информации из прошлой активности конкретного пользователя или истории других пользователей, которые, как считается, имеют схожие вкусы с данным пользователем. Эти ресурсы используются для профилирования пользователей и помогают сайту рекомендовать контент для каждого пользователя. Чем больше конкретный пользователь использует систему, тем точнее становятся рекомендации, поскольку система получает данные для улучшения своей модели этого пользователя.
Система совместной фильтрации не обязательно автоматически сопоставляет контент с предпочтениями пользователя. Если платформа не обеспечивает необычно хорошего разнообразия и независимости мнений, одна точка зрения всегда будет доминировать над другой в конкретном сообществе. Как и в сценарии персонализированной рекомендации, введение новых пользователей или новых элементов может вызвать проблему холодного запуска, так как данных по этим новым записям будет недостаточно для корректной работы совместной фильтрации. Чтобы дать соответствующие рекомендации для нового пользователя, система должна сначала изучить предпочтения пользователя, проанализировав прошлые голосования или рейтинговые действия. Система совместной фильтрации требует, чтобы значительное количество пользователей оценили новый элемент, прежде чем его можно будет рекомендовать.
На практике многие коммерческие рекомендательные системы основаны на больших наборах данных. В результате матрица «пользователь-элемент», используемая для совместной фильтрации, может быть чрезвычайно большой и разреженной, что затрудняет выполнение рекомендаций.
Одной из типичных проблем, вызванных нехваткой данных, является проблема холодного запуска. Поскольку методы совместной фильтрации рекомендуют элементы на основе прошлых предпочтений пользователей, новые пользователи должны будут оценить достаточное количество элементов, чтобы система могла точно уловить их предпочтения и, таким образом, предоставить надежные рекомендации.
Точно так же у новинок та же проблема. Когда новые элементы добавляются в систему, они должны быть оценены значительным числом пользователей, прежде чем их можно будет рекомендовать пользователям, у которых вкусы схожи с теми, кто их оценил. Проблема с новым элементом не влияет на рекомендации, основанные на содержании, поскольку рекомендация элемента основана на его дискретном наборе описательных качеств, а не на его рейтингах.
По мере роста числа пользователей и элементов традиционные алгоритмы CF столкнутся с серьезными проблемами масштабируемости. Например, с десятками миллионов клиентов 


Синонимы относится к тенденции числа одинаковых или очень похожих предметов, чтобы иметь разные названия или записи. Большинство рекомендательных систем неспособны обнаружить эту скрытую ассоциацию и поэтому по-разному относятся к этим продуктам.
Например, кажущиеся разными элементами «детский фильм» и «детский фильм» на самом деле относятся к одному и тому же элементу. Действительно, степень вариативности в использовании описательных терминов больше, чем обычно предполагалось. Преобладание синонимов снижает эффективность рекомендаций систем CF. Тематическое моделирование (например, метод скрытого распределения Дирихле ) может решить эту проблему, сгруппировав разные слова, принадлежащие одной теме.
Серая овца относится к пользователям, чьи мнения не всегда совпадают или не согласуются с какой-либо группой людей и, следовательно, не получают выгоды от совместной фильтрации. Черная овца - это группа, чьи идиосинкразические вкусы делают рекомендации практически невозможными. Несмотря на то, что это сбой рекомендательной системы, неэлектронные рекомендатели также имеют большие проблемы в этих случаях, поэтому наличие паршивой овцы - приемлемый отказ.
В рекомендательной системе, где каждый может давать оценки, люди могут давать много положительных оценок своим товарам и отрицательных оценок своим конкурентам. Совместным системам фильтрации часто необходимо вводить меры предосторожности для предотвращения таких манипуляций.
Ожидается, что фильтры для совместной работы увеличат разнообразие, потому что они помогают нам открывать новые продукты. Однако некоторые алгоритмы могут непреднамеренно сделать обратное. Поскольку совместные фильтры рекомендуют продукты на основе прошлых продаж или рейтингов, они обычно не могут рекомендовать продукты с ограниченными историческими данными. Это может создать для популярных товаров эффект «богатство - обогащение», подобный положительным отзывам. Этот уклон в сторону популярности может помешать тому, что в противном случае лучше соответствовало бы потребительскому товару. В исследовании Wharton подробно описывается этот феномен вместе с несколькими идеями, которые могут способствовать разнообразию и «длинному хвосту ». Было разработано несколько алгоритмов совместной фильтрации для продвижения разнообразия и «длинного хвоста » путем рекомендации новых, неожиданных и случайных элементов.
Матрица элементов пользователя является базовой основой традиционных методов совместной фильтрации, и она страдает от проблемы разреженности данных (т.е. холодный запуск ). Как следствие, за исключением матрицы пользовательских элементов, исследователи пытаются собрать больше вспомогательной информации, чтобы помочь повысить эффективность рекомендаций и разработать персонализированные рекомендательные системы. Как правило, существует две популярных вспомогательной информации: информация об атрибутах и информация о взаимодействии. Информация об атрибутах описывает свойства пользователя или элемента. Например, атрибут пользователя может включать общий профиль (например, пол и возраст) и социальные контакты (например, подписчиков или друзей в социальных сетях ); Атрибут предмета означает такие свойства, как категория, бренд или контент. Кроме того, информация о взаимодействии относится к неявным данным, показывающим, как пользователи взаимодействуют с элементом. Широко используемая информация о взаимодействии содержит теги, комментарии или обзоры, историю просмотров и т. Д. Вспомогательная информация играет важную роль во многих аспектах. Явные социальные связи, как надежный представитель доверия или дружбы, всегда используются при вычислении сходства, чтобы найти похожих людей, которые разделяют интересы с целевым пользователем. Информация, связанная с взаимодействием - теги - используется в качестве третьего измерения (в дополнение к пользователю и элементу) в расширенной совместной фильтрации для построения трехмерной тензорной структуры для исследования рекомендаций.