
Войти
В математике, приближение Теория занимается тем, как функции могут быть наилучшим образом аппроксимированы более простыми функциями, а количественно характеризуют вызванные этим ошибки. Обратите внимание, что то, что подразумевается под лучшим и простым, будет зависеть от приложения.
Тесно связанной темой является приближение функций обобщенным рядом Фурье, то есть приближения, основанные на суммировании ряда членов, основанных на ортогональных многочленах.
Одна проблема Особый интерес представляет аппроксимация функции в математической библиотеке компьютер с использованием операций, которые могут выполняться на компьютере или калькуляторе (например, сложение и умножение), так что результат максимально приближен к фактической функции насколько возможно. Обычно это делается с помощью аппроксимаций полинома или рационального (отношение полиномов).
Цель состоит в том, чтобы сделать приближение как можно ближе к фактической функции, обычно с точностью, близкой к точности арифметики с плавающей запятой базового компьютера. Это достигается за счет использования полинома высокой степени и / или сужения области, в которой полином должен аппроксимировать функцию. Сужение области часто можно осуществить за счет использования различных формул сложения или масштабирования для аппроксимируемой функции. Современные математические библиотеки часто сокращают область до множества крошечных сегментов и используют полином низкой степени для каждого сегмента.
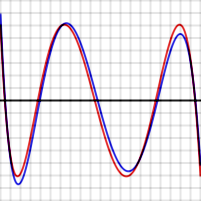 Ошибка между оптимальным полиномом и log (x) (красный), и приближением Чебышева и log (x) (синий) на интервале [2, 4]. Вертикальные деления равны 10. Максимальная ошибка для оптимального полинома составляет 6,07 × 10. Ошибка между оптимальным полиномом и log (x) (красный), и приближением Чебышева и log (x) (синий) на интервале [2, 4]. Вертикальные деления равны 10. Максимальная ошибка для оптимального полинома составляет 6,07 × 10. |  Ошибка между оптимальным полиномом и exp (x) (красный), а также приближением Чебышева и exp (x) (синий) на интервале [−1, 1]. Вертикальное деление равно 10. Максимальная ошибка для оптимального полинома составляет 5,47 × 10. Ошибка между оптимальным полиномом и exp (x) (красный), а также приближением Чебышева и exp (x) (синий) на интервале [−1, 1]. Вертикальное деление равно 10. Максимальная ошибка для оптимального полинома составляет 5,47 × 10. |
После выбора области (обычно интервал) и степени многочлена выбирается сам многочлен таким образом, чтобы минимизировать наихудшая ошибка. То есть цель состоит в том, чтобы минимизировать максимальное значение 



Например, графики, показанные справа, показывают ошибку аппроксимации log (x) и exp (x) для N = 4. Красные кривые для оптимального полинома имеют уровень, то есть они колеблются между
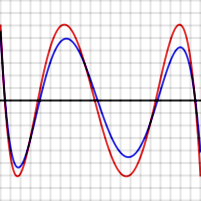 Ошибка P (x) - f (x) для многочлена уровня (красный) и для предполагаемого лучшего многочлена (синий)
Ошибка P (x) - f (x) для многочлена уровня (красный) и для предполагаемого лучшего многочлена (синий) Чтобы доказать, что это в целом верно, предположим, что P - многочлен степени N, обладающий свойством описывается, то есть порождает функцию ошибок, которая имеет N + 2 экстремума, чередующихся знаков и равных величин. Красный график справа показывает, как эта функция ошибок может выглядеть для N = 4. Предположим, Q (x) (чья функция ошибок показана синим справа) - это еще один многочлен N-степени, который является лучшим приближением к f, чем P. В частности, Q ближе к f, чем P для каждого значения x i, где встречается крайнее значение P − f, поэтому

Когда максимум P − f встречается в x i, тогда

И когда минимум P − f встречается в x i, тогда

Итак, как видно на графике, [P (x) - f (x)] - [Q (x) - f (x)] должны чередоваться по знаку для N + 2 значений x я. Но [P (x) - f (x)] - [Q (x) - f (x)] сводится к P (x) - Q (x), который является многочленом степени N. Эта функция меняет знак не менее N +1 раз, поэтому по теореме о промежуточном значении он имеет N + 1 нулей, что невозможно для многочлена степени N.
Можно получить многочлены, очень близкие к оптимальному, расширяя данную функцию в терминах многочленов Чебышева и затем обрезая разложение в желаемой степени. Это похоже на анализ Фурье функции, использующий полиномы Чебышева вместо обычных тригонометрических функций.
Если вычислить коэффициенты в разложении Чебышева для функции:

, а затем обрезает ряд после 
Причина, по которой этот многочлен почти оптимален, заключается в том, что для функций с быстро сходящимися степенными рядами, если ряд обрезается после некоторого члена, общая ошибка, возникающая из-за обрезания, близка к первому члену после обрезания. То есть первый член после отсечения доминирует над всеми последующими членами. То же самое верно и в случае разложения в терминах полиномов противодействия. Если раскрытие Чебышева прерывается после 
На графиках выше обратите внимание, что синяя функция ошибки иногда лучше (внутри) красной функции, но иногда хуже, что означает, что это не совсем оптимальный полином. Расхождение менее серьезно для функции exp, которая имеет чрезвычайно быстро сходящийся степенной ряд, чем для функции log.
Чебышёвское приближение является основой для квадратур Кленшоу – Кертиса, метода численного интегрирования.
Алгоритм Ремеза (иногда пишется Ремес) используется для получения оптимального полинома P (x), приближающего заданную функцию f (x) по заданной интервал. Это итерационный алгоритм, который сходится к полиному, который имеет функцию ошибок с N + 2 экстремумами уровня. По теореме выше этот многочлен оптимален.
Алгоритм Ремеза использует тот факт, что можно построить многочлен N-й степени, который приводит к уровням и переменным значениям ошибок, учитывая N + 2 контрольных точки.
Дано N + 2 контрольных точки 



Правые части меняются знаками.
То есть

Поскольку 




На приведенном ниже графике показан пример этого, создавая полином четвертой степени, аппроксимирующий 
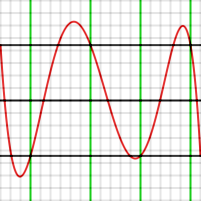 Ошибка полинома, полученного на первом шаге алгоритма Ремеза, аппроксимирующего e в интервале [-1, 1 ]. Вертикальное деление равно 10.
Ошибка полинома, полученного на первом шаге алгоритма Ремеза, аппроксимирующего e в интервале [-1, 1 ]. Вертикальное деление равно 10. Обратите внимание, что график ошибок действительно принимает значения 
Второй шаг алгоритма Ремеза состоит в перемещении контрольных точек в приблизительные места, где функция ошибок имела свои фактические локальные максимумы или минимумы. Например, глядя на график, можно сказать, что точка -0,1 должна была находиться примерно в -0,28. Способ сделать это в алгоритме - использовать один цикл метода Ньютона. Поскольку известна первая и вторая производные от P (x) - f (x), можно приблизительно вычислить, на сколько нужно переместить контрольную точку, чтобы производная была равна нулю.
Вычислить производные полинома несложно. Также необходимо уметь вычислять первую и вторую производные от f (x). Алгоритм Ремеза требует способности вычислять 


После перемещения контрольных точек часть линейного уравнения повторяется, получая новый многочлен, и снова используется метод Ньютона для повторного перемещения контрольных точек. Эта последовательность продолжается до тех пор, пока результат не достигнет желаемой точности. Алгоритм сходится очень быстро. Сходимость квадратичная для корректных функций - если контрольные точки находятся в пределах 

Алгоритм Ремеза обычно запускается с выбора экстремумов полинома Чебышева