
Войти
В статистике, эконометрике, эпидемиологии, генетике и смежных дисциплинах графы причинно-следственных связей (также известные как диаграммы путей, причинно-следственные байесовские сети или DAG) - это вероятностные графические модели, используемые для кодирования предположений о процессе генерации данных. Их также можно рассматривать как схему алгоритма, с помощью которого Природа присваивает значения переменным в интересующей области.
Причинно-следственные диаграммы могут использоваться для коммуникации и для вывода. Как устройства связи, графики обеспечивают формальное и прозрачное представление причинных допущений, которые исследователи могут пожелать передать и защитить. В качестве инструментов вывода графики позволяют исследователям оценить величину эффекта на основе неэкспериментальных данных, получить проверяемые последствия закодированных предположений, проверить внешнюю валидность и управлять отсутствующими данными и ошибкой выбора.
Причинно-следственные графы впервые были использованы генетиком Сьюэлом Райт под рубрикой «путевые диаграммы». Позже они были приняты социологами и, в меньшей степени, экономистами. Эти модели изначально были ограничены линейными уравнениями с фиксированными параметрами. Современные разработки расширили графические модели до непараметрического анализа и, таким образом, достигли универсальности и гибкости, которые изменили причинный анализ в компьютерных науках, эпидемиологии и социальных науках.
Граф причинно-следственных связей можно построить следующим образом. Каждая переменная в модели имеет соответствующую вершину или узел, и стрелка рисуется от переменной X к переменной Y всякий раз, когда считается, что Y реагирует на изменения в X, когда все другие переменные остаются постоянными. Переменные, связанные с Y с помощью прямых стрелок, называются родительскими для Y или «непосредственными причинами Y» и обозначаются Pa (Y).
Причинно-следственные модели часто включают «условия ошибки» или «пропущенные факторы», которые представляют все неизмеряемые факторы, которые влияют на переменную Y, когда Pa (Y) остается постоянным. В большинстве случаев ошибки исключаются из графика. Однако, если автор графа подозревает, что условия ошибок любых двух переменных являются зависимыми (например, две переменные имеют ненаблюдаемую или скрытую общую причину), то между ними рисуется двунаправленная дуга. Таким образом, наличие скрытых переменных принимается во внимание посредством корреляций, которые они вызывают между ошибочными членами, представленными двунаправленными дугами.
Фундаментальным инструментом графического анализа является d-разделение, которое позволяет исследователям путем проверки определить, подразумевает ли причинная структура наличие двух наборов переменных независимы при третьем наборе. В рекурсивных моделях без коррелированных условий ошибок (иногда называемых марковскими) эти условные независимости представляют все проверяемые следствия модели.
Предположим, мы хотим оценить влияние посещения элитного колледжа на будущие доходы. Простая регрессия заработка на рейтинг колледжа не даст объективной оценки целевого эффекта, потому что элитные колледжи очень избирательны, и студенты, посещающие их, скорее всего, будут иметь квалификацию для высокооплачиваемой работы до поступления в школу. Предполагая, что причинно-следственные связи являются линейными, эти базовые знания могут быть выражены в следующей спецификации модели структурных уравнений (SEM).
Модель 1

где 



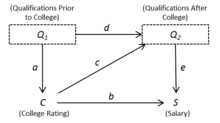 Рис. 1. Неидентифицированная модель со скрытыми переменными (и ) показан явно
Рис. 1. Неидентифицированная модель со скрытыми переменными (и ) показан явно 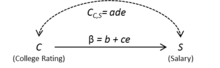 Рисунок 2: Неидентифицированная модель с обобщенными скрытыми переменными
Рисунок 2: Неидентифицированная модель с обобщенными скрытыми переменными Рисунок 1 - это причинно-следственный график, который представляет эту спецификацию модели. Каждая переменная в модели имеет соответствующий узел или вершину в графе. Кроме того, для каждого уравнения стрелки нарисованы от независимых переменных к зависимым переменным. Эти стрелки отражают направление причинно-следственной связи. В некоторых случаях мы можем обозначить стрелку соответствующим структурным коэффициентом, как показано на рисунке 1.
Если
Модель 2

Исходная информация, указанная в Модели 1, подразумевает, что член ошибки 

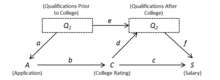 Рисунок 3: Идентифицированная модель со скрытыми переменными (и ) показан явно
Рисунок 3: Идентифицированная модель со скрытыми переменными (и ) показан явно 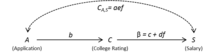 Рисунок 4. Идентифицированная модель с обобщенными скрытыми переменными
Рисунок 4. Идентифицированная модель с обобщенными скрытыми переменными Начиная с 

Model 3

Удалив скрытые переменные из спецификации модели, мы получим:
Модель 4

с 
Итак,