
Войти
Иерархия кэша, или многоуровневые кеши, относится к архитектуре памяти, которая использует иерархию хранилищ памяти в зависимости от скорости доступа к кэшируемым данным. Часто запрашиваемые данные кэшируются в хранилищах памяти с высокоскоростным доступом, что обеспечивает более быстрый доступ для ядер центрального процессора (ЦП).
Иерархия кэша является формой и частью иерархии памяти и может рассматриваться как форма многоуровневого хранилища. Эта конструкция была предназначена для ускорения обработки ядер ЦП, несмотря на задержку памяти при доступе к основной памяти. Доступ к основной памяти может стать узким местом для производительности ядра ЦП, поскольку ЦП ожидает данных, в то время как обеспечение высокой скорости всей основной памяти может быть чрезмерно дорогостоящим. Высокоскоростные кэши - это компромисс, позволяющий получить высокоскоростной доступ к данным, наиболее часто используемым ЦП, позволяющий повысить тактовую частоту ЦП.
 Универсальная многоуровневая организация кеширования
Универсальная многоуровневая организация кеширования В истории В развитии компьютеров и электронных микросхем был период, когда увеличение скорости процессора опережало улучшение скорости доступа к памяти. Разрыв между скоростью процессоров и памяти означал, что процессор часто простаивал. ЦП становились все более способными запускать и выполнять большие объемы инструкций в заданное время, но время, необходимое для доступа к данным из основной памяти, не позволяло программам в полной мере использовать эту возможность. Эта проблема побудила к созданию моделей памяти с более высокой скоростью доступа, чтобы реализовать потенциал более быстрых процессоров.
Это привело к концепции кэш-памяти, впервые предложенной Морисом. Уилкс, британский ученый-компьютерщик из Кембриджского университета в 1965 году. Он назвал такие модели памяти «рабской памятью». Примерно между 1970 и 1990 годами в статьях и статьях Ананта Агарвала, Алана Джея Смита, Марка Д. Хилла и других обсуждались более совершенные конструкции кэш-памяти. В то время были реализованы первые модели кэш-памяти, но даже когда исследователи изучали и предлагали лучшие конструкции, потребность в более быстрых моделях памяти сохранялась. Эта потребность возникла из-за того, что, хотя ранние модели кеширования улучшали задержку доступа к данным, с точки зрения стоимости и технических ограничений кэш компьютерной системы не мог приблизиться к размеру основной памяти. Начиная с 1990 года, предлагались такие идеи, как добавление еще одного уровня кэша (второго уровня) в качестве резервной копии кеша первого уровня. Жан-Лу Бэр, Вен-Ханн Ван, Эндрю Уилсон и другие проводили исследования этой модели. Когда несколько симуляций и реализаций продемонстрировали преимущества двухуровневых моделей кэш-памяти, концепция многоуровневых кешей стала новой и в целом более совершенной моделью кэш-памяти. С 2000 года модели многоуровневой кэш-памяти привлекли широкое внимание и в настоящее время реализованы во многих системах, например, трехуровневые кэш-памяти, присутствующие в продуктах Intel Core i7.
Доступ к основной памяти для выполнения каждой инструкции может привести к медленной обработке, при этом тактовая частота зависит от времени, необходимого для поиска и выборки данных. Чтобы скрыть эту задержку памяти от процессора, используется кэширование данных. Когда данные требуются процессору, они извлекаются из основной памяти и сохраняются в меньшей структуре памяти, называемой кешем. Если есть какие-либо дополнительные потребности в этих данных, сначала выполняется поиск в кэше, прежде чем переходить в основную память. Эта структура находится ближе к процессору с точки зрения времени, затрачиваемого на поиск и выборку данных по отношению к основной памяти. Преимущества использования кеша могут быть доказаны путем расчета среднего времени доступа (AAT) для иерархии памяти с кешем и без него.
Кеши, будучи небольшими в размер, может привести к частым ошибкам - когда поиск в кэше не дает искомой информации - что приведет к вызову основной памяти для выборки данных. Следовательно, на AAT влияет частота промахов каждой структуры, из которой они ищут данные.

AAT для основной памяти определяется временем обращения основная память. AAT для кешей может быть задан как
Время обращения к кешам меньше, чем время обращения к основной памяти, поэтому AAT для извлечения данных значительно ниже при доступе к данным через кеш, а не через основную память.
Хотя использование кеша может улучшить задержку памяти, это не всегда может привести к требуемому улучшению времени, затрачиваемого на выборку данных, из-за способа организации и обхода кешей. Например, кеши с прямым отображением, которые имеют одинаковый размер, обычно имеют более высокая частота промахов, чем полностью ассоциативные кеши. Это также может зависеть от теста компьютера, тестирующего процессор, и от шаблона инструкций. Но использование полностью ассоциативного кеша может привести к большему энергопотреблению, так как он должен искать весь кеш каждый время. Из-за этого компромисс между потребляемой мощностью (и сопутствующим теплом) и размером o f кэш становится критически важным при проектировании кэша.
 Иерархия кэша для уровня кэша до L3 и основной памяти с L1 на кристалле
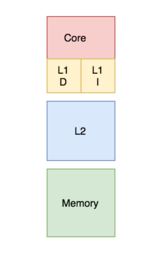
Иерархия кэша для уровня кэша до L3 и основной памяти с L1 на кристалле В случае промаха кэша цель Использование такой структуры будет бесполезным, и компьютеру придется обратиться к основной памяти, чтобы получить необходимые данные. Однако с многоуровневым кешем, если компьютер пропускает кэш, ближайший к процессору (кэш первого уровня или L1), он будет искать следующий ближайший уровень (уровни) кеша и перейдет к в основную память, только если эти методы не работают. Общая тенденция состоит в том, чтобы кэш L1 оставался небольшим и на расстоянии 1-2 тактовых циклов ЦП от процессора, при этом более низкие уровни кешей увеличивались в размере для хранения большего количества данных, чем L1, следовательно, они были более удаленными, но с меньшим количеством промахов. показатель. Это приводит к лучшему AAT. Количество уровней кэша может быть спроектировано архитекторами в соответствии с их требованиями после проверки компромиссов между стоимостью, AAT и размером.
Благодаря масштабированию технологий, которое позволило использовать память системы могут быть размещены на одном кристалле, большинство современных процессоров имеют до трех или четырех уровней кэш-памяти. Уменьшение AAT можно понять на этом примере, где компьютер проверяет AAT на наличие различных конфигураций вплоть до кэшей L3.
Пример: основная память = 50 нс, L1 = 1 нс с частотой промахов 10%, L2 = 5 нс с частотой промахов 1%), L3 = 10 нс с частотой промахов 0,2%.
 Организация кэша с отдельным L1 и объединенным L2
Организация кэша с отдельным L1 и объединенным L2 В Банковский кэш, кэш делится на кэш, выделенный для хранения инструкций , и кэш, выделенный для данных. Напротив, унифицированный кеш содержит как инструкции, так и данные в одном кэше. Во время процесса процессор обращается к кэшу L1 (или кэшу самого верхнего уровня по отношению к его подключению к процессору) для извлечения как инструкций, так и данных. Требование одновременного выполнения обоих действий требует нескольких портов и большего времени доступа к единому кешу. Наличие нескольких портов требует дополнительного оборудования и проводки, что приводит к значительной структуре между кэшами и процессорами. Чтобы избежать этого, кэш L1 часто организован в виде банковского кэша, что приводит к меньшему количеству портов, меньшему количеству оборудования и, как правило, меньшему времени доступа.
Современные процессоры имеют разделенные кеши, а в системах с многоуровневыми кешами кеши более высокого уровня могут быть объединены, а нижние уровни разделены.
 Инклюзивная организация кеша
Инклюзивная организация кеша Может ли блок, присутствующий в верхнем уровне кеша, также присутствовать на нижнем уровне кеша, определяется включением системы памяти политика, которая может быть включающей, исключающей или неисключающей, неисключительной (ДЕВЯТЬ).
С включающей политикой все блоки, присутствующие в кэше верхнего уровня, должны присутствовать в кэше нижнего уровня также. Каждый компонент кэша верхнего уровня является подмножеством компонента кэша нижнего уровня. В этом случае из-за дублирования блоков происходит некоторая потеря памяти. Однако проверка выполняется быстрее.
В соответствии с эксклюзивной политикой все компоненты иерархии кэша являются полностью исключительными, так что любой элемент в кэше верхнего уровня не будет присутствовать ни в одном из компонентов нижнего кеша. Это позволяет полностью использовать кэш-память. Однако существует большая задержка доступа к памяти.
Вышеупомянутые политики требуют соблюдения набора правил для их реализации. Если ничего из этого не выполняется принудительно, результирующая политика включения называется неисключительной неисключительной (ДЕВЯТЬ). Это означает, что кэш верхнего уровня может присутствовать или отсутствовать в кэше нижнего уровня.
Существуют две политики, которые определяют способ, которым измененный блок кеша будет быть обновленным в основной памяти: запись и обратная запись.
В случае политики сквозной записи всякий раз, когда значение блока кэша изменяется, оно также изменяется в иерархии памяти нижнего уровня. Эта политика гарантирует безопасное хранение данных, поскольку они записываются по всей иерархии.
Однако в случае политики обратной записи измененный блок кэша будет обновлен в иерархии нижнего уровня только тогда, когда блок кэша исключен. «Грязный бит» прикрепляется к каждому блоку кеша и устанавливается всякий раз, когда блок кеша изменяется. Во время вытеснения блоки с установленным грязным битом будут записаны в иерархию нижнего уровня. В соответствии с этой политикой существует риск потери данных, поскольку последняя измененная копия данных сохраняется только в кэше, и поэтому необходимо соблюдать некоторые методы исправления.
В случае записи, когда байт отсутствует в блоке кэша, байт может быть перенесен в кэш, как определено политикой выделения для записи или записи без выделения. Политика распределения записи гласит, что в случае промаха записи блок извлекается из основной памяти и помещается в кэш перед записью. В политике записи без выделения памяти, если блок пропущен в кэше, он будет записывать в иерархию памяти нижнего уровня без извлечения блока в кэш.
Общие комбинации политик: «блок записи», «выделение для записи» и «запись через запись без выделения».
 Организация кеша с частным L1 и общим L2 и L3
Организация кеша с частным L1 и общим L2 и L3 Частный кеш назначается одному конкретному ядру в процессоре и недоступен для других ядер. В некоторых архитектурах каждое ядро имеет собственный частный кэш; это создает риск дублирования блоков в архитектуре кэш-памяти системы, что приводит к снижению использования емкости. Однако этот тип дизайна в многоуровневой архитектуре кэш-памяти также может быть полезен для более низкой задержки доступа к данным.
Общий кеш - это кэш, к которому могут обращаться несколько ядер. Поскольку он является общим, каждый блок в кэше уникален и, следовательно, имеет более высокий процент попаданий, поскольку не будет дублированных блоков. Однако задержка при доступе к данным может увеличиваться, поскольку несколько ядер пытаются получить доступ к одному и тому же кэшу.
В многоядерных процессорах выбор конструкции, чтобы сделать кэш совместно используемым или частным, влияет на производительность процессор. На практике кэш L1 верхнего уровня (или иногда L2) реализован как частный, а кеши нижнего уровня реализованы как общие. Такая конструкция обеспечивает высокую скорость доступа для кэшей высокого уровня и низкую частоту пропусков для кэшей нижнего уровня.
 Организация кеш-памяти микроархитектуры Intel Nehalem
Организация кеш-памяти микроархитектуры Intel Nehalem