
Войти
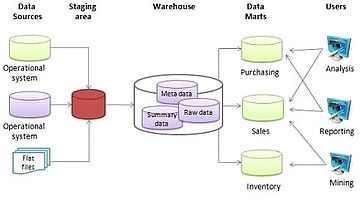 Базовая архитектура хранилища данных
Базовая архитектура хранилища данных Агрегаты используются в размерных моделях хранилища данных , чтобы обеспечить положительное влияние на время, необходимое для запроса больших наборов данных. В простейшем виде агрегат представляет собой простую сводную таблицу, которую можно получить, выполнив SQL-запрос Group by. Более распространенное использование агрегатов - взять измерение и изменить степень детализации этого измерения. При изменении степени детализации измерения таблица фактов должна быть частично обобщена, чтобы соответствовать новому зерну нового измерения, создавая таким образом новое измерение . и таблицы фактов, соответствующие этому новому уровню детализации. Агрегаты иногда называют предварительно вычисленными итоговыми данными, поскольку агрегаты обычно представляют собой предварительно вычисленные частично обобщенные данные, которые хранятся в новых агрегированных таблицах. Когда факты объединяются, это делается либо путем исключения размерности, либо путем связывания фактов со свернутым измерением. Свернутые измерения должны быть уменьшенными версиями измерений, связанных с гранулированными базовыми фактами. Таким образом, агрегированные таблицы измерений должны соответствовать базовым таблицам измерений. Таким образом, причина, по которой агрегаты могут значительно повысить производительность хранилища данных, заключается в уменьшении количества строк, к которым нужно получить доступ при ответе на запрос.
Ральф Кимбалл, которого многие считают таковым. один из первых архитекторов хранилищ данных, говорит:
Единственный наиболее существенный способ повлиять на производительность в большом хранилище данных - это предоставить правильный набор агрегированных (сводных) записей, которые сосуществуют с первичными базовыми записями. Агрегаты могут очень сильно влиять на производительность, в некоторых случаях ускоряя запросы в сто или даже тысячу раз. Никаких других средств для получения таких впечатляющих результатов не существует.
Наличие агрегатов и атомарных данных увеличивает сложность размерной модели. Эта сложность должна быть прозрачной для пользователей хранилища данных, поэтому при выполнении запроса хранилище данных должно возвращать данные из таблицы с правильной степенью детализации. Поэтому, когда выполняются запросы к хранилищу данных, должна быть реализована функция агрегированного навигатора, чтобы помочь определить правильную таблицу с правильной степенью детализации. Количество возможных агрегатов определяется всеми возможными комбинациями гранулярностей измерений. Поскольку построение всех возможных агрегатов приведет к большим накладным расходам, рекомендуется выбрать подмножество таблиц для агрегирования. Лучший способ выбрать это подмножество и решить, какие агрегаты создавать - это отслеживать запросы и разрабатывать агрегаты для соответствия шаблонам запросов.
Наличие агрегированных данных в многомерной модели делает среду более удобной. сложный. Чтобы сделать эту дополнительную сложность прозрачной для пользователя, используется функция, известная как агрегированная навигация, для запроса таблиц измерений и фактов с правильным уровнем детализации. Агрегатная навигация по существу исследует запрос, чтобы увидеть, можно ли на него ответить, используя агрегатную таблицу меньшего размера.
Реализации агрегатных навигаторов можно найти в ряде технологий:
Обычно рекомендуется использовать любую из первых трех технологий, поскольку в последнем случае преимущества ограничено одним интерфейсом BI tool